También podría gustarte
- AED82 Eq 04 Prac 04 22pDocumento5 páginasAED82 Eq 04 Prac 04 22pRoberto RicoAún no hay calificaciones
- Opcional Diseño de Algoritmos UnivalleDocumento1 páginaOpcional Diseño de Algoritmos UnivalleToXiC GoLDeN - Android GamingAún no hay calificaciones
- Tarea Tercer ParcialDocumento5 páginasTarea Tercer ParcialIrma Dinorah LemusAún no hay calificaciones
- Diap Micros Clase 02Documento27 páginasDiap Micros Clase 02abraham pinedaAún no hay calificaciones
- Tarea Final de Identificación de SistemasDocumento4 páginasTarea Final de Identificación de SistemasCRISTOPHER ANDRES ULLOA HONORATOAún no hay calificaciones
- Lab06 2022-2Documento15 páginasLab06 2022-2Victor Jhorgant Antaihua HuayllaAún no hay calificaciones
- 2do Parcial de Calculo 1 Jose QuinteroDocumento11 páginas2do Parcial de Calculo 1 Jose QuinteroJose Eduardo Nuñez HernandezAún no hay calificaciones
- Practica 4 R IDDocumento10 páginasPractica 4 R IDpajedrezAún no hay calificaciones
- Vectores, Matrices y Punteros en C++Documento17 páginasVectores, Matrices y Punteros en C++Alfredo Toriz Palacios0% (1)
- Econometria 1er ExamenDocumento8 páginasEconometria 1er ExamenVICTOR RAUL VENTURA BARRIENTOSAún no hay calificaciones
- Asignacion 2Documento14 páginasAsignacion 2Sam EliasAún no hay calificaciones
- Informe Investigativo 2Documento8 páginasInforme Investigativo 2Gilberto AguiarAún no hay calificaciones
- Nivel 3 Tipo 1Documento11 páginasNivel 3 Tipo 1ismaelAún no hay calificaciones
- SobrecargaDocumento11 páginasSobrecargaAntonio Vazquez AraujoAún no hay calificaciones
- Tutorial Spatstat 2Documento55 páginasTutorial Spatstat 2Gerardo MartinAún no hay calificaciones
- Carranza Ramírez Mario Hiram M18S4PIDocumento4 páginasCarranza Ramírez Mario Hiram M18S4PIHiram CarranzaAún no hay calificaciones
- Ejercicios de Implementación Java Tercera EntregaDocumento7 páginasEjercicios de Implementación Java Tercera Entregazaider garciaAún no hay calificaciones
- Lab05 MatematicaAplicadaalaElectronica Informe PDFDocumento24 páginasLab05 MatematicaAplicadaalaElectronica Informe PDFFernan HDAún no hay calificaciones
- Guias Analisis NumericoDocumento15 páginasGuias Analisis NumericoSealdeSaAún no hay calificaciones
- Actividad 3 Luis Manuel FonsecaDocumento14 páginasActividad 3 Luis Manuel FonsecaErick Machado100% (1)
- Si Fr."i Si (151 5i: Unn'ErsidadctudadailaDocumento2 páginasSi Fr."i Si (151 5i: Unn'Ersidadctudadailamayito imajenesAún no hay calificaciones
- Practica General INF121 Programacion 2Documento19 páginasPractica General INF121 Programacion 2Julio GrajedaAún no hay calificaciones
- Proyecto Unidad Tematica 2 - Cinematica de ParticulasDocumento10 páginasProyecto Unidad Tematica 2 - Cinematica de ParticulasBrayan PeñaAún no hay calificaciones
- DataTable Versus DatareaderDocumento5 páginasDataTable Versus DatareaderTximis KurdiAún no hay calificaciones
- Establecimiento y Ajuste de Los IntervalDocumento14 páginasEstablecimiento y Ajuste de Los IntervalYULI PAULINS PELAYO CASTAEDAAún no hay calificaciones
- IS13 Examenenero09Documento4 páginasIS13 Examenenero09nmulettAún no hay calificaciones
- Informe - Analisis Grafico (LUIGI)Documento16 páginasInforme - Analisis Grafico (LUIGI)Joaquin Alberto Vesga JimenezAún no hay calificaciones
- Taller Clases-ObjetosDocumento47 páginasTaller Clases-ObjetosDiego RodriguezAún no hay calificaciones
- Diap Tema 01 Clase 02Documento25 páginasDiap Tema 01 Clase 02Antony Jose Borbon OspinoAún no hay calificaciones
- Problemas de Fisica Resueltos Por IntegralesDocumento5 páginasProblemas de Fisica Resueltos Por IntegralesAriel SaPa40% (5)
- Lab 1 ModelamientoDocumento13 páginasLab 1 ModelamientoC Carlos100% (1)
- Control de Sistemas Electricos PidDocumento3 páginasControl de Sistemas Electricos PidJuan Yesid Cáceres RosasAún no hay calificaciones
- 1 Curvas y Funciones Vectoriales de Una Variable RealDocumento9 páginas1 Curvas y Funciones Vectoriales de Una Variable RealElder Cortez Bueno0% (1)
- LAB01 - Informe Pendulo InvertidoDocumento25 páginasLAB01 - Informe Pendulo InvertidosaulAún no hay calificaciones
- Ep2-Grupo 4Documento11 páginasEp2-Grupo 4Bryan RuizAún no hay calificaciones
- Práctica 1 - Estimación de Punto y Por Intervalos 1Documento9 páginasPráctica 1 - Estimación de Punto y Por Intervalos 1jorge antonio torres cabreraAún no hay calificaciones
- Coeficiente de Amortiguamiento, Frecuencia Natural y Efecto de Los Ceros en Un Sistemas de Segundo Orden y en Sistemas de Orden SuperiorDocumento25 páginasCoeficiente de Amortiguamiento, Frecuencia Natural y Efecto de Los Ceros en Un Sistemas de Segundo Orden y en Sistemas de Orden SuperiorDaniel OrtuñoAún no hay calificaciones
- Grupo 8 TF IMCDocumento10 páginasGrupo 8 TF IMCKevin RamónAún no hay calificaciones
- Reporte Practica3Documento30 páginasReporte Practica3Edward RichtofenAún no hay calificaciones
- Guía 2 Valor Promedio y Eficaz (Matlab)Documento4 páginasGuía 2 Valor Promedio y Eficaz (Matlab)Diego Fernando Ramirez MuñozAún no hay calificaciones
- Etapa 1 - Grupo 243005 - 23Documento10 páginasEtapa 1 - Grupo 243005 - 23Julian Andres Hernandez CastroAún no hay calificaciones
- g48 Ej2a Jupyter NotebookDocumento5 páginasg48 Ej2a Jupyter NotebookMarisnelvys CabrejaAún no hay calificaciones
- Laboratorio 5Documento8 páginasLaboratorio 5Juan Felipe Plata ValbuenaAún no hay calificaciones
- Primera Practica Calificada ResueltaDocumento6 páginasPrimera Practica Calificada Resueltawlen2012Aún no hay calificaciones
- Aplicaciones de La EDO EN LA INGDocumento6 páginasAplicaciones de La EDO EN LA INGAxel G MNAún no hay calificaciones
- Fase 1 - Modelar El Sistema Dinámico en El Dominio Del Tiempo - Omar GomezDocumento6 páginasFase 1 - Modelar El Sistema Dinámico en El Dominio Del Tiempo - Omar GomezOmar Gomez100% (1)
- Estructuras de Datos Clase Teórica 1: ContenidoDocumento12 páginasEstructuras de Datos Clase Teórica 1: ContenidoAlejandro Gómez JAún no hay calificaciones
- Tarea Control2 SernaTorre ESTRATEGIASDocumento9 páginasTarea Control2 SernaTorre ESTRATEGIASJohny GarganoAún no hay calificaciones
- Tarea3 - Grupo4 Señales y SistemasDocumento24 páginasTarea3 - Grupo4 Señales y SistemasDEIVI MARIAAún no hay calificaciones
- Practica No 4 MatricesDocumento4 páginasPractica No 4 MatricesSkaty-bethy AlvarezAún no hay calificaciones
- L5 Aplicaciones de La IntegralDocumento12 páginasL5 Aplicaciones de La IntegralKoey SanchezAún no hay calificaciones
- Examen 5Documento8 páginasExamen 5Manuela MerchanAún no hay calificaciones
- Eficiencia de Algoritmos PDFDocumento67 páginasEficiencia de Algoritmos PDFJairo MolinaAún no hay calificaciones
- Practica 5 - Complejidad en TiempoDocumento4 páginasPractica 5 - Complejidad en TiempoMagnificent McAún no hay calificaciones
- Tarea 2 Semana 5Documento3 páginasTarea 2 Semana 5Luis Alberto VelasquezAún no hay calificaciones
- Solucionario 1 Parcial Matematica 41Documento1 páginaSolucionario 1 Parcial Matematica 41Jhon FernandezAún no hay calificaciones
- Campamento de Programacion Dia 6 - Estructuras de DatosDocumento35 páginasCampamento de Programacion Dia 6 - Estructuras de DatosRuben Holguino BordaAún no hay calificaciones
- Resolución de La Segunda Práctica de Laboratorio de Cálculo Numérico y ComputacionalDocumento14 páginasResolución de La Segunda Práctica de Laboratorio de Cálculo Numérico y ComputacionalGabriel BayonaAún no hay calificaciones
- Radical Pilot - MerzkyDocumento20 páginasRadical Pilot - MerzkyAli RojasAún no hay calificaciones
- Mementopython3 Espanol 58 PDFDocumento2 páginasMementopython3 Espanol 58 PDFKerly Caterine Barzola RodríguezAún no hay calificaciones
- Informe PrototipoDocumento1 páginaInforme PrototipoAli RojasAún no hay calificaciones
- Reconstruccion3D Con Sistema Estereocopico de Camaras BlanesFDocumento8 páginasReconstruccion3D Con Sistema Estereocopico de Camaras BlanesFAli RojasAún no hay calificaciones
- Farsa Del Cornudo Apaleado y ContentoDocumento19 páginasFarsa Del Cornudo Apaleado y ContentoAli RojasAún no hay calificaciones
- A Tutorial On Visual Servo ControlDocumento26 páginasA Tutorial On Visual Servo ControlAli RojasAún no hay calificaciones
- De La Noche A La Mañana - Letra RepartidaDocumento1 páginaDe La Noche A La Mañana - Letra RepartidaAli RojasAún no hay calificaciones
- FuaDocumento5 páginasFuaeldeivissAún no hay calificaciones
- Yo Apoyo A Aldo Mariategui en La Lucha Contra Los Ineptos y CorruptosDocumento4 páginasYo Apoyo A Aldo Mariategui en La Lucha Contra Los Ineptos y CorruptosAli RojasAún no hay calificaciones
- Anexo 1Documento1 páginaAnexo 1Pablo ParicahuaAún no hay calificaciones
- CT 042se CCTVDocumento1 páginaCT 042se CCTVAli RojasAún no hay calificaciones
- 2 DoexamDocumento4 páginas2 DoexamAli RojasAún no hay calificaciones
- FactorizacionDocumento14 páginasFactorizacionYover Arroyo GuerreroAún no hay calificaciones
- Plan 29Documento1 páginaPlan 29Ali RojasAún no hay calificaciones
- Desvelando Nuestra Identidad DigitalDocumento7 páginasDesvelando Nuestra Identidad DigitalAli RojasAún no hay calificaciones
- Calculo Ejercicios 2Documento2 páginasCalculo Ejercicios 2Jair Francesco HcAún no hay calificaciones
- Desvelando Nuestra Identidad DigitalDocumento7 páginasDesvelando Nuestra Identidad DigitalAli RojasAún no hay calificaciones
- Informe EXPOTRONDocumento22 páginasInforme EXPOTRONAli RojasAún no hay calificaciones
- 09-07-2009 2do Examen ActuadoresDocumento2 páginas09-07-2009 2do Examen ActuadoresAli RojasAún no hay calificaciones
- GuillermoGallego PFC ResumenDocumento13 páginasGuillermoGallego PFC ResumenAli RojasAún no hay calificaciones
- Cómo Ensamblar en PROTEUS ISISDocumento4 páginasCómo Ensamblar en PROTEUS ISISMiguel Albino MachicadoAún no hay calificaciones
- Manual Ciclista UrbanoDocumento191 páginasManual Ciclista UrbanoÁlvaro Tapia MiquelAún no hay calificaciones
- TINAJANI - Ciudad de TitanesDocumento30 páginasTINAJANI - Ciudad de TitanesAli Rojas100% (1)
- LiricaDocumento27 páginasLiricaAli RojasAún no hay calificaciones
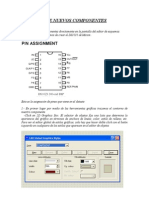
- Creación de Nuevos ComponentesDocumento12 páginasCreación de Nuevos Componentestkf23mAún no hay calificaciones
- ArraysDocumento12 páginasArrayseeindustrialAún no hay calificaciones
- Control PID (Traduccion Cap 5 Corripio - Ing Echaiz)Documento6 páginasControl PID (Traduccion Cap 5 Corripio - Ing Echaiz)Ali RojasAún no hay calificaciones
- Transmisión de Audio Por Línea EléctricaDocumento7 páginasTransmisión de Audio Por Línea EléctricaAli RojasAún no hay calificaciones
- Informatica JuridicaDocumento21 páginasInformatica JuridicaNathalyAún no hay calificaciones
- MINICASO 2 JuanaDocumento2 páginasMINICASO 2 JuanaEsteban RcAún no hay calificaciones
- CV Emmanuel ContrerasDocumento3 páginasCV Emmanuel Contrerasacustico82Aún no hay calificaciones
- Volante InformeDocumento15 páginasVolante InformeCristian JoaquinAún no hay calificaciones
- Sistema de Lavado para Mezcladoras y TanquesDocumento2 páginasSistema de Lavado para Mezcladoras y TanquesVillecco LucasAún no hay calificaciones
- Manual Librerias BIM PlastigamaDocumento70 páginasManual Librerias BIM PlastigamaCarlitos VegaAún no hay calificaciones
- Clase de Clasificacion Del SoftwareDocumento7 páginasClase de Clasificacion Del SoftwareMauricio PradoAún no hay calificaciones
- Ex Amen Complex IvoDocumento244 páginasEx Amen Complex IvoJhon Harrynson Jiménez RuirAún no hay calificaciones
- Oral Project First Term Exam English 4Documento3 páginasOral Project First Term Exam English 4liss CrAún no hay calificaciones
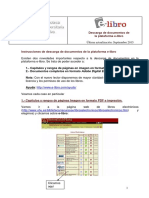
- Descarga de Libros en La Plataforma ElibroDocumento13 páginasDescarga de Libros en La Plataforma ElibroDra.Teresa SuárezAún no hay calificaciones
- Practica 3 Arcgis Vectorizacion CuencaDocumento3 páginasPractica 3 Arcgis Vectorizacion CuencamarioAún no hay calificaciones
- Manual XentryDocumento115 páginasManual Xentryjasogti0% (1)
- Articles - ST-GU-18 Copia ControladaDocumento13 páginasArticles - ST-GU-18 Copia Controladaseven team securityAún no hay calificaciones
- Mantenimiento Preventivo DemoDocumento362 páginasMantenimiento Preventivo DemoDaniel MarquezAún no hay calificaciones
- Atajos de Teclado AlumnosDocumento14 páginasAtajos de Teclado AlumnosMadrigal M. EsthefanyAún no hay calificaciones
- Epm-Resumen-Grupo No 9 (Aporte)Documento6 páginasEpm-Resumen-Grupo No 9 (Aporte)Moises LaneAún no hay calificaciones
- Excel EmpresarialDocumento13 páginasExcel EmpresarialRossangella OrtizAún no hay calificaciones
- 1 - Manual Actualizacion Firmware OLT GP3600-16 V1Documento14 páginas1 - Manual Actualizacion Firmware OLT GP3600-16 V1fermac telecomunicacionesAún no hay calificaciones
- Rendimiento LaboralDocumento30 páginasRendimiento LaboralAngel Edward Alanya MallquiAún no hay calificaciones
- Crear Tu Propio Ebook Con LibreOffice en FormatoDocumento4 páginasCrear Tu Propio Ebook Con LibreOffice en FormatoPavier JazAún no hay calificaciones
- Trabajo Final - Grupo - MEDIFASTDocumento9 páginasTrabajo Final - Grupo - MEDIFASTLizbeth SaavedraAún no hay calificaciones
- Infra WorksDocumento22 páginasInfra WorksJuan V. Gomez HonoriAún no hay calificaciones
- Impresora XeroxDocumento1 páginaImpresora XeroxFrancisco Norambuena RAún no hay calificaciones
- Mapa Mental TextoDocumento2 páginasMapa Mental TextoANGIE NICOL ROMERO ESPINOSAAún no hay calificaciones
- Odoo AnotacionesDocumento4 páginasOdoo AnotacionesMario AvilaAún no hay calificaciones
- GuiónDocumento4 páginasGuiónMariaAlejndra1Aún no hay calificaciones
- Uso de Filtros en WiresharkDocumento5 páginasUso de Filtros en WiresharkJulieta García Da RosaAún no hay calificaciones
- Cuestionario - Métodos NuméricosDocumento6 páginasCuestionario - Métodos NuméricosBRYAN ALEXANDER ULLOA LATACUNGAAún no hay calificaciones
- Silabo Software MatematicoDocumento5 páginasSilabo Software MatematicoMaximiliano E. Asis Lopez100% (2)
- Seguridad en Los Sistemas de Información Expocicion Tema 8 Grupo 3 Con BrunoDocumento10 páginasSeguridad en Los Sistemas de Información Expocicion Tema 8 Grupo 3 Con Brunotessy moreiraAún no hay calificaciones