También podría gustarte
- Estadística para veterinarios y zootecnistasDe EverandEstadística para veterinarios y zootecnistasCalificación: 5 de 5 estrellas5/5 (1)
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Solucionario de Estadistica para Administracion y Economia Anderson Sweeney Williams 10 Edition Rarg PDFDocumento3 páginasSolucionario de Estadistica para Administracion y Economia Anderson Sweeney Williams 10 Edition Rarg PDFJuAn Escobar C0% (3)
- Qué Es La Muestra EstadísticaDocumento9 páginasQué Es La Muestra EstadísticaRiofrio Net SernaAún no hay calificaciones
- Muestreo Probabilidad Tema 4Documento35 páginasMuestreo Probabilidad Tema 4esauAún no hay calificaciones
- Unidad 4 MuestreoDocumento8 páginasUnidad 4 MuestreoIván ReyesAún no hay calificaciones
- Muestreo y Estimacion Estadistica PDFDocumento7 páginasMuestreo y Estimacion Estadistica PDFAdolfo OrellanaAún no hay calificaciones
- Muestreo SLDocumento15 páginasMuestreo SLValeria Ramos RealAún no hay calificaciones
- El MuestreoDocumento4 páginasEl MuestreoLisbeth ParedesAún no hay calificaciones
- Estadística inferencial 1: Introducción a distribuciones muestralesDocumento17 páginasEstadística inferencial 1: Introducción a distribuciones muestralesFERNANDO NarvaezAún no hay calificaciones
- Teoría Elemental de MuestreoDocumento12 páginasTeoría Elemental de MuestreoDave RodriguezAún no hay calificaciones
- Resumen Distribuciones MuestralesDocumento11 páginasResumen Distribuciones MuestralesANA GABRIELA LOPEZ PEREZAún no hay calificaciones
- Diapositiva de Distribucion MuestralDocumento63 páginasDiapositiva de Distribucion MuestralRicardo Angel Berrio PerezAún no hay calificaciones
- Inv de Los Temas de La Unidad 6Documento28 páginasInv de Los Temas de La Unidad 6Alan MarcosAún no hay calificaciones
- Consulta (Muestreo TLC)Documento5 páginasConsulta (Muestreo TLC)faustoandres95Aún no hay calificaciones
- Teoria Elemental de MuestreoDocumento29 páginasTeoria Elemental de MuestreoJiselaAún no hay calificaciones
- 1 Texto Paralelo Metodos EstadisticosDocumento9 páginas1 Texto Paralelo Metodos EstadisticosELMERurielAún no hay calificaciones
- Sesion 03 :muestreo y Distribuciones MuestralesDocumento25 páginasSesion 03 :muestreo y Distribuciones MuestralesJunior HZ100% (1)
- Población y MuestraDocumento6 páginasPoblación y MuestraFernando Cob chiAún no hay calificaciones
- Taller 2 Investigación EstadísticaDocumento9 páginasTaller 2 Investigación Estadísticajessica zaqueAún no hay calificaciones
- Copia de Estimadores EstadisticosDocumento26 páginasCopia de Estimadores Estadisticosbq7gk4q7wcAún no hay calificaciones
- Muestreo PpsDocumento14 páginasMuestreo PpsJhofrey AlmazanAún no hay calificaciones
- 4 Muestreo Estadistico CicloDocumento9 páginas4 Muestreo Estadistico CicloHenry Valdez AquinoAún no hay calificaciones
- Teoria Elemental de MuestreoDocumento29 páginasTeoria Elemental de MuestreoWinnie C. MoralesAún no hay calificaciones
- Caldwell Capítulo 5Documento3 páginasCaldwell Capítulo 5andresAún no hay calificaciones
- Trabajo Inferencia Estadistica TeoriaDocumento10 páginasTrabajo Inferencia Estadistica Teoriaeduar vela100% (1)
- Muestreo Probabilísticos y No ProbabilísticosDocumento6 páginasMuestreo Probabilísticos y No ProbabilísticosLizbeth Borda DonairesAún no hay calificaciones
- Muestreo (Estadística) PDFDocumento5 páginasMuestreo (Estadística) PDFAnibal Capuñay IzquierdoAún no hay calificaciones
- Muestreo no aleatorioDocumento8 páginasMuestreo no aleatorioJuan CarlosAún no hay calificaciones
- Investigación U4.cruz Martínez AdrianaDocumento14 páginasInvestigación U4.cruz Martínez AdrianaAdriana Cruz MartínezAún no hay calificaciones
- Distribuciones MuestralesDocumento13 páginasDistribuciones MuestralesJuan SotoAún no hay calificaciones
- 8muestreo AleatorioDocumento18 páginas8muestreo AleatorioAlex JavierAún no hay calificaciones
- Estadistica Inferencial I - 304i - 072433Documento29 páginasEstadistica Inferencial I - 304i - 072433Fausto JoaquinAún no hay calificaciones
- Teoria Del Muestreo, Teoria de La Estimacion Estadistica, Analisis de Regresion y Correlacion.Documento16 páginasTeoria Del Muestreo, Teoria de La Estimacion Estadistica, Analisis de Regresion y Correlacion.Ismael DarAún no hay calificaciones
- Informe de Estadistica IIDocumento13 páginasInforme de Estadistica IIFabricio PerdomoAún no hay calificaciones
- Informe 2 Muestreo y Estimacion 4Documento7 páginasInforme 2 Muestreo y Estimacion 4cristinoAún no hay calificaciones
- Teoría MuestralDocumento18 páginasTeoría MuestralVannya Vargas Lopez100% (1)
- Tema 3Documento19 páginasTema 3miacalvo100303Aún no hay calificaciones
- Muestreo estadísticoDocumento16 páginasMuestreo estadísticoDaniel NoriegaAún no hay calificaciones
- ESTADÍSTICAINVESTIGACION-WPS OfficeDocumento3 páginasESTADÍSTICAINVESTIGACION-WPS Officejesus alejandro betancourt mataAún no hay calificaciones
- Distribuciones muestrales de estadísticosDocumento23 páginasDistribuciones muestrales de estadísticosFreddy Rodriguez QuinteroAún no hay calificaciones
- 5 - Unidad 5Documento12 páginas5 - Unidad 5Angeles DmcAún no hay calificaciones
- Chavez Alejandro Tarea1Documento8 páginasChavez Alejandro Tarea1Jorge ChavezAún no hay calificaciones
- Tipos de Muestreo y Teorema Del Límite CentralDocumento2 páginasTipos de Muestreo y Teorema Del Límite CentralJuanhartuRocker CortésAún no hay calificaciones
- Poblacion Muestra y MuestreoDocumento48 páginasPoblacion Muestra y MuestreoOsmer CalderónAún no hay calificaciones
- Trabajo UNAD - Muestreo e Intervalos de ConfianzaDocumento7 páginasTrabajo UNAD - Muestreo e Intervalos de Confianzapedro gil100% (1)
- Unidad 1 Estadistica InferencialDocumento15 páginasUnidad 1 Estadistica InferencialDart SuarezAún no hay calificaciones
- Competencia 1 - Distribuciones Fundamentales para El MuestreoDocumento56 páginasCompetencia 1 - Distribuciones Fundamentales para El MuestreoJuan Manuel Martinez EnriquezAún no hay calificaciones
- Probabilidad Tema 5 Trabajo de InvestigaciónDocumento19 páginasProbabilidad Tema 5 Trabajo de InvestigaciónEMaria Galván VegaAún no hay calificaciones
- Investigación Distribuciones MuestralesDocumento15 páginasInvestigación Distribuciones MuestralesXavier DiazAún no hay calificaciones
- Muest ReoDocumento32 páginasMuest ReoTomasHamAún no hay calificaciones
- Tipos de Muestreo (Presentacion Estadistica) - 1Documento29 páginasTipos de Muestreo (Presentacion Estadistica) - 1programassociales programassocialesAún no hay calificaciones
- Taller 2 Tecnicas de Muestreo y TLC LAURA OLARTEDocumento2 páginasTaller 2 Tecnicas de Muestreo y TLC LAURA OLARTELaura OlarteAún no hay calificaciones
- Muestreo 2022Documento17 páginasMuestreo 2022ARLIN CRISTIANY GARCIA RETAMOZOAún no hay calificaciones
- Ensayo de Muestreo y EstimacionDocumento5 páginasEnsayo de Muestreo y EstimacionDerechosyobligaciones delostrabajadoresAún no hay calificaciones
- Estadistica InferencialDocumento53 páginasEstadistica Inferencialmaria alejandraAún no hay calificaciones
- Trujillo Gonzalez Andy Distribucion MuestralDocumento40 páginasTrujillo Gonzalez Andy Distribucion MuestralJorge L. OlmedoAún no hay calificaciones
- Distribución BinomialDocumento11 páginasDistribución BinomialVicky TolozaAún no hay calificaciones
- Elementos de estadística para ingeniería: Un curso básicoDe EverandElementos de estadística para ingeniería: Un curso básicoAún no hay calificaciones
- Tema 4 Medidas de DispersiónDocumento17 páginasTema 4 Medidas de DispersiónMónica Vargas TriveñoAún no hay calificaciones
- Marco metodológico del estudioDocumento5 páginasMarco metodológico del estudioMónica Vargas TriveñoAún no hay calificaciones
- PDE Hito 2: Práctica sobre temas 1 y 2Documento4 páginasPDE Hito 2: Práctica sobre temas 1 y 2Mónica Vargas Triveño0% (1)
- Alpha de CronbachDocumento2 páginasAlpha de CronbachMónica Vargas TriveñoAún no hay calificaciones
- Avance de Informe - PROCESUAL - Hito 3 PDE - II22Documento5 páginasAvance de Informe - PROCESUAL - Hito 3 PDE - II22Mónica Vargas TriveñoAún no hay calificaciones
- Análisis de datos médicosDocumento2 páginasAnálisis de datos médicosMónica Vargas TriveñoAún no hay calificaciones
- Practica Spss Psico I2022Documento4 páginasPractica Spss Psico I2022Mónica Vargas TriveñoAún no hay calificaciones
- Ejemplo de Respuestas y CodificaciónDocumento28 páginasEjemplo de Respuestas y CodificaciónMónica Vargas TriveñoAún no hay calificaciones
- Flujo de Caja ExcelDocumento6 páginasFlujo de Caja ExcelMónica Vargas TriveñoAún no hay calificaciones
- Analisis Del Empleo en BoliviaDocumento164 páginasAnalisis Del Empleo en BoliviaMarisel Hinojosa ToroAún no hay calificaciones
- Uso de La Estadística para El Análisis Crediticio en El Sector ProductivoDocumento24 páginasUso de La Estadística para El Análisis Crediticio en El Sector ProductivoMónica Vargas TriveñoAún no hay calificaciones
- Pruebas paramétricas y no paramétricas: diferencias claveDocumento6 páginasPruebas paramétricas y no paramétricas: diferencias claveMónica Vargas TriveñoAún no hay calificaciones
- Carta Solicitud Información UnifranzDocumento4 páginasCarta Solicitud Información UnifranzMónica Vargas TriveñoAún no hay calificaciones
- Caso de Estudio HarleyDocumento6 páginasCaso de Estudio HarleyMónica Vargas Triveño100% (1)
- Uso de La Estadística para El Análisis Crediticio en El Sector ProductivoDocumento24 páginasUso de La Estadística para El Análisis Crediticio en El Sector ProductivoMónica Vargas TriveñoAún no hay calificaciones
- Rapport Final MicmacDocumento6 páginasRapport Final MicmacMónica Vargas TriveñoAún no hay calificaciones
- Medidas de dispersión: rango, cuartiles, desviación media, varianza y desviación estándarDocumento2 páginasMedidas de dispersión: rango, cuartiles, desviación media, varianza y desviación estándarMónica Vargas TriveñoAún no hay calificaciones
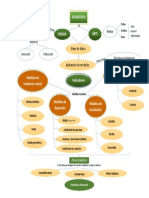
- Mapa Mental EstadísticaDocumento1 páginaMapa Mental EstadísticaMónica Vargas TriveñoAún no hay calificaciones
- Ejercicios Analisis de VariablesDocumento1 páginaEjercicios Analisis de VariablesMónica Vargas TriveñoAún no hay calificaciones
- Guia ParticipanteDocumento67 páginasGuia ParticipanteFrank GarciaAún no hay calificaciones
- Enseñanza Verdadera. Serge Raynaud de La FerriereDocumento48 páginasEnseñanza Verdadera. Serge Raynaud de La FerriereWilfredoErnesto100% (2)
- OraturaDocumento11 páginasOraturaCharlee ChimaliAún no hay calificaciones
- El Carnaval Juliaqueño Ofrenda A La PachamamaDocumento186 páginasEl Carnaval Juliaqueño Ofrenda A La PachamamaElard Serruto DancuartAún no hay calificaciones
- Ud1primerobach 4Documento10 páginasUd1primerobach 4Ismael Aranda RodriguezAún no hay calificaciones
- Organismos e Instituciones Científicos Tecnológicos Dedicados A La Promoción, Difusión de La Ciencia y La Tecnología.Documento2 páginasOrganismos e Instituciones Científicos Tecnológicos Dedicados A La Promoción, Difusión de La Ciencia y La Tecnología.Jordelis HerreraAún no hay calificaciones
- El Abordaje Etnográfico de La Investigación SocialDocumento6 páginasEl Abordaje Etnográfico de La Investigación SocialNahir Firpo100% (2)
- Ema ManuDocumento39 páginasEma ManuJAIMEADRIANO100% (1)
- Inteligencia ArtificialDocumento32 páginasInteligencia ArtificialMaria Jose SequeiraAún no hay calificaciones
- Técnicas Difusas para La Evaluación de ImpactosDocumento18 páginasTécnicas Difusas para La Evaluación de ImpactosJavierAún no hay calificaciones
- Generación y Transformación de Las Instituciones SocialesDocumento40 páginasGeneración y Transformación de Las Instituciones SocialesGabrielLopezAún no hay calificaciones
- Como Estudiarla Conciencia: Tres Paradigmas para La PsicologiaDocumento12 páginasComo Estudiarla Conciencia: Tres Paradigmas para La PsicologiaBOSSAún no hay calificaciones
- Resumen David GarlandDocumento2 páginasResumen David GarlandkelldiazAún no hay calificaciones
- Tarea 2 - Elementos Teoricos de La EtnopsicologiaDocumento14 páginasTarea 2 - Elementos Teoricos de La EtnopsicologiaAdriana VanegasAún no hay calificaciones
- Modelo Basico para La Superacion Del DocenteDocumento77 páginasModelo Basico para La Superacion Del DocenteAnonymous OennIb3Aún no hay calificaciones
- Padron-2022-Pdf-Corte-Agosto 2022 - ActualizadoDocumento14 páginasPadron-2022-Pdf-Corte-Agosto 2022 - ActualizadoElmer Tratamiento De Agua PootAún no hay calificaciones
- Sustento TeoricoDocumento16 páginasSustento TeoricoLuis Francisco Herrera GarayAún no hay calificaciones
- FenomenologíaDocumento3 páginasFenomenologíaBenjamin TorresAún no hay calificaciones
- Antropología MexicanaDocumento24 páginasAntropología MexicanaJessica DíazAún no hay calificaciones
- Interpretación y Uso de Los Certificados de CalibraciónDocumento8 páginasInterpretación y Uso de Los Certificados de CalibraciónsismecalabAún no hay calificaciones
- Dicccionario Universal de La Lengua Castellana, Ciencia y Artes Tomo IDocumento140 páginasDicccionario Universal de La Lengua Castellana, Ciencia y Artes Tomo IJeremy George100% (1)
- 01 Azuay Educacion Superior en Cifras Diciembre 2018Documento23 páginas01 Azuay Educacion Superior en Cifras Diciembre 2018rich7mcsAún no hay calificaciones
- Manual Normalizacion Tesis Version UMCE 2014Documento57 páginasManual Normalizacion Tesis Version UMCE 2014Fernando Christian CastroAún no hay calificaciones
- Linea Del Tiempo de Ing Industrial 1.1Documento3 páginasLinea Del Tiempo de Ing Industrial 1.1Luis MoraAún no hay calificaciones
- Merton. Funciones Manifiestas y LatentesDocumento70 páginasMerton. Funciones Manifiestas y LatentesTamaRa Ramos MerinoAún no hay calificaciones
- SandroJimenez - CurriculumPortafolio Julio 2007Documento8 páginasSandroJimenez - CurriculumPortafolio Julio 2007api-3714047Aún no hay calificaciones
- Ciencias SocialesDocumento1 páginaCiencias SocialesGibran Meza Castrejon100% (1)
- Recolección de datos emprendimientosDocumento3 páginasRecolección de datos emprendimientosKuskunku Makiruray100% (4)
- 6evaluación Segundo Parcial Estadística BásicaDocumento5 páginas6evaluación Segundo Parcial Estadística BásicaYamil Diego AgrAún no hay calificaciones
- Proyecto Agosto 2018 Wayra KillaDocumento6 páginasProyecto Agosto 2018 Wayra KillakarmelusAún no hay calificaciones