0% encontró este documento útil (0 votos)
996 vistas31 páginasCaminos Óptimos
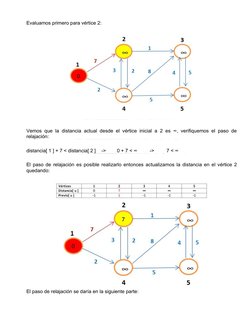
Este documento trata sobre los caminos óptimos en grafos. Explica los antecedentes de la teoría de grafos y define lo que es un camino óptimo. Luego, describe los tres problemas principales de encontrar el camino más corto: entre dos nodos específicos, desde un nodo origen, y entre todos los pares de nodos. También define conceptos clave como caminos mínimos y hamiltonianos. Finalmente, resume varios algoritmos importantes para resolver problemas de caminos óptimos, incluyendo los algoritmos de Bellman-Ford, Dijkstra, Johnson
Cargado por
Lizeth VargasDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como DOCX, PDF, TXT o lee en línea desde Scribd
0% encontró este documento útil (0 votos)
996 vistas31 páginasCaminos Óptimos
Este documento trata sobre los caminos óptimos en grafos. Explica los antecedentes de la teoría de grafos y define lo que es un camino óptimo. Luego, describe los tres problemas principales de encontrar el camino más corto: entre dos nodos específicos, desde un nodo origen, y entre todos los pares de nodos. También define conceptos clave como caminos mínimos y hamiltonianos. Finalmente, resume varios algoritmos importantes para resolver problemas de caminos óptimos, incluyendo los algoritmos de Bellman-Ford, Dijkstra, Johnson
Cargado por
Lizeth VargasDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como DOCX, PDF, TXT o lee en línea desde Scribd