También podría gustarte
- Infografías - Samuel MirandaDocumento7 páginasInfografías - Samuel MirandaSamuel MirandaAún no hay calificaciones
- Taller 1 Cifras Significativas Redondeo Not CientDocumento2 páginasTaller 1 Cifras Significativas Redondeo Not CientSamuel MirandaAún no hay calificaciones
- Argumentación y PersuasiónDocumento4 páginasArgumentación y PersuasiónSamuel MirandaAún no hay calificaciones
- La Argumentacion EscritaDocumento6 páginasLa Argumentacion EscritaSamuel MirandaAún no hay calificaciones
- Ambiente de FormacionDocumento1 páginaAmbiente de FormacionSamuel MirandaAún no hay calificaciones
- Ejercicio Actividad Número 3Documento1 páginaEjercicio Actividad Número 3Samuel MirandaAún no hay calificaciones
- Guia Retroalimentación - Ciclo 24 - La IlustraciónDocumento7 páginasGuia Retroalimentación - Ciclo 24 - La IlustraciónSamuel MirandaAún no hay calificaciones
- Piense y Hágase RicoDocumento9 páginasPiense y Hágase RicoSamuel MirandaAún no hay calificaciones
- Actividad Número 2 Motores Diesel Samuel MirandaDocumento9 páginasActividad Número 2 Motores Diesel Samuel MirandaSamuel MirandaAún no hay calificaciones
- Actividad 1 Mecanica DieselDocumento3 páginasActividad 1 Mecanica DieselSamuel MirandaAún no hay calificaciones
- Joy El Nombre Del ExitoDocumento2 páginasJoy El Nombre Del ExitoSamuel MirandaAún no hay calificaciones
- Cuestionario de Hidraulica 2020Documento2 páginasCuestionario de Hidraulica 2020Samuel MirandaAún no hay calificaciones
- Articulo de Opinion PDFDocumento1 páginaArticulo de Opinion PDFSamuel MirandaAún no hay calificaciones
- Importación y Exportación Tabla de ComparaciónDocumento2 páginasImportación y Exportación Tabla de ComparaciónSamuel MirandaAún no hay calificaciones
- Instrucciones de Instalacion de Correo en Outlook-2013Documento4 páginasInstrucciones de Instalacion de Correo en Outlook-2013artur gascaAún no hay calificaciones
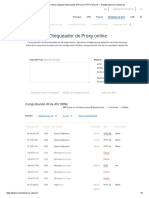
- Chequeadore Proxy Online, Chequea Online Listas de Proxys HTTP y SOCKS - HideMy - Name (Ex IncloakDocumento4 páginasChequeadore Proxy Online, Chequea Online Listas de Proxys HTTP y SOCKS - HideMy - Name (Ex IncloakAbdis Henrry Turpo QuinchoAún no hay calificaciones
- Configura Un Servidor SSH en Ubuntu para Acceder A Tu Equipo de Forma RemotaDocumento5 páginasConfigura Un Servidor SSH en Ubuntu para Acceder A Tu Equipo de Forma RemotaFernando VergaraAún no hay calificaciones
- Hablame Ejemplo Sms BasicoDocumento1 páginaHablame Ejemplo Sms Basicoblock chairAún no hay calificaciones
- F5 LTM Configuring BIG-IP v11Documento127 páginasF5 LTM Configuring BIG-IP v11davidokb100% (1)
- Cómo Configurar Tu Red Ante Bloqueos de CantvDocumento9 páginasCómo Configurar Tu Red Ante Bloqueos de CantvjagerobbaireAún no hay calificaciones
- 2.2 El Protocolo HTTPDocumento9 páginas2.2 El Protocolo HTTPBry RosAún no hay calificaciones
- Manual DNS UbuntuDocumento3 páginasManual DNS Ubuntuolo_2429_92Aún no hay calificaciones
- PRTG Network MonitorDocumento31 páginasPRTG Network MonitorLuis Reyes VenturaAún no hay calificaciones
- PWA 5.4.4 Cookies Httponly y SecureDocumento8 páginasPWA 5.4.4 Cookies Httponly y SecureLuis Mario Ek UcAún no hay calificaciones
- Practica PKA Cap 8-SSHDocumento2 páginasPractica PKA Cap 8-SSHAlbert PérezAún no hay calificaciones
- Protocolo SSH, FTP, TFTP, HTTP, HttpsDocumento23 páginasProtocolo SSH, FTP, TFTP, HTTP, HttpsBetzi FloresAún no hay calificaciones
- SSL TLSDocumento2 páginasSSL TLSFernanda Calderon PerezAún no hay calificaciones
- Cómo Configuro Mi Cuenta de Email en OutlookDocumento5 páginasCómo Configuro Mi Cuenta de Email en OutlookDomingo G. Brito RAún no hay calificaciones
- Guia para Levantar Un Servidor WebDocumento4 páginasGuia para Levantar Un Servidor WebJoaquin AguilarAún no hay calificaciones
- 03 - Laboratorio Habilitar Video LlamadasDocumento7 páginas03 - Laboratorio Habilitar Video LlamadasCarlos BravoAún no hay calificaciones
- 04-Middleware para Aplicaciones Web (HTTP)Documento22 páginas04-Middleware para Aplicaciones Web (HTTP)Luis Flores PuchetaAún no hay calificaciones
- Controlador de Dominio y Compartición de Ficheros - Documentación de Zentyal 6.2Documento1 páginaControlador de Dominio y Compartición de Ficheros - Documentación de Zentyal 6.2Hansel ValdesAún no hay calificaciones
- DHCPDocumento9 páginasDHCPkate lopezAún no hay calificaciones
- CORTECS Shield RP18 Column, 90Å, 2.7 M, 4.6 MM X 150 MM Columna para HPLC PDFDocumento6 páginasCORTECS Shield RP18 Column, 90Å, 2.7 M, 4.6 MM X 150 MM Columna para HPLC PDFratigerAún no hay calificaciones
- Fundamentos TeóricosDocumento11 páginasFundamentos TeóricosJose Milton Guardia MamaniAún no hay calificaciones
- Payload AnalyticsDocumento2 páginasPayload AnalyticsHenry SalinasAún no hay calificaciones
- 020 Instalación de Xampp + SVN + ApacheTo (1) ...Documento17 páginas020 Instalación de Xampp + SVN + ApacheTo (1) ...Fernando Gutiérrez ParamioAún no hay calificaciones
- SMR AOF08 Contenidos 2022 VIDocumento47 páginasSMR AOF08 Contenidos 2022 VIParrot Bebop 2 DroneAún no hay calificaciones
- URL y Dominio.Documento2 páginasURL y Dominio.meybolAún no hay calificaciones
- Redes y Aplicaciones p2pDocumento15 páginasRedes y Aplicaciones p2pFer JavierAún no hay calificaciones
- Practica ACL GNS3 y VirtualBoxDocumento12 páginasPractica ACL GNS3 y VirtualBoxDanny GarzónAún no hay calificaciones
- 8.5.1 Lab - Configure DHCPv6 - ILMDocumento19 páginas8.5.1 Lab - Configure DHCPv6 - ILMLILIANA GUTIERREZ RANCRUELAún no hay calificaciones
- Protocolos Capa SuperiorDocumento11 páginasProtocolos Capa SuperiorAndy ComaAún no hay calificaciones
- Ejercicio CabecerasDocumento14 páginasEjercicio CabecerasSony EscriAún no hay calificaciones
- Influencia. La psicología de la persuasiónDe EverandInfluencia. La psicología de la persuasiónCalificación: 4.5 de 5 estrellas4.5/5 (14)
- Ciencia de datos: La serie de conocimientos esenciales de MIT PressDe EverandCiencia de datos: La serie de conocimientos esenciales de MIT PressCalificación: 5 de 5 estrellas5/5 (1)
- 7 tendencias digitales que cambiarán el mundoDe Everand7 tendencias digitales que cambiarán el mundoCalificación: 4.5 de 5 estrellas4.5/5 (87)
- Inteligencia artificial: Lo que usted necesita saber sobre el aprendizaje automático, robótica, aprendizaje profundo, Internet de las cosas, redes neuronales, y nuestro futuroDe EverandInteligencia artificial: Lo que usted necesita saber sobre el aprendizaje automático, robótica, aprendizaje profundo, Internet de las cosas, redes neuronales, y nuestro futuroCalificación: 4 de 5 estrellas4/5 (1)
- Sistema de gestión lean para principiantes: Fundamentos del sistema de gestión lean para pequeñas y medianas empresas - con muchos ejemplos prácticosDe EverandSistema de gestión lean para principiantes: Fundamentos del sistema de gestión lean para pequeñas y medianas empresas - con muchos ejemplos prácticosCalificación: 4 de 5 estrellas4/5 (16)
- Cultura y clima: fundamentos para el cambio en la organizaciónDe EverandCultura y clima: fundamentos para el cambio en la organizaciónAún no hay calificaciones
- EL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.De EverandEL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.Calificación: 4 de 5 estrellas4/5 (51)
- Clics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaDe EverandClics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaCalificación: 4.5 de 5 estrellas4.5/5 (117)
- Guía para la aplicación de ISO 9001 2015De EverandGuía para la aplicación de ISO 9001 2015Calificación: 4 de 5 estrellas4/5 (1)
- Guía de aplicacion de la ISO 9001:2015De EverandGuía de aplicacion de la ISO 9001:2015Calificación: 5 de 5 estrellas5/5 (3)
- Inteligencia artificial: Una exploración filosófica sobre el futuro de la mente y la concienciaDe EverandInteligencia artificial: Una exploración filosófica sobre el futuro de la mente y la concienciaAna Isabel Sánchez DíezCalificación: 4 de 5 estrellas4/5 (3)
- Excel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másDe EverandExcel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Electrónica básica: INGENIERÍA ELECTRÓNICA Y DE LAS COMUNICACIONESDe EverandElectrónica básica: INGENIERÍA ELECTRÓNICA Y DE LAS COMUNICACIONESCalificación: 5 de 5 estrellas5/5 (16)
- Reparar (casi) cualquier cosa: Cómo ajustar los objetos de uso cotidiano con la electrónica y la impresora 3DDe EverandReparar (casi) cualquier cosa: Cómo ajustar los objetos de uso cotidiano con la electrónica y la impresora 3DCalificación: 5 de 5 estrellas5/5 (6)
- Excel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteDe EverandExcel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteCalificación: 1 de 5 estrellas1/5 (1)
- GuíaBurros Microsoft Excel: Todo lo que necesitas saber sobre esta potente hoja de cálculoDe EverandGuíaBurros Microsoft Excel: Todo lo que necesitas saber sobre esta potente hoja de cálculoCalificación: 3.5 de 5 estrellas3.5/5 (6)
- Toma de decisiones en las empresas: Entre el arte y la técnica: Metodologías, modelos y herramientasDe EverandToma de decisiones en las empresas: Entre el arte y la técnica: Metodologías, modelos y herramientasAún no hay calificaciones