También podría gustarte
- Comportamiento Organizacional EjxdDocumento5 páginasComportamiento Organizacional EjxdJuan BreAún no hay calificaciones
- Carta de Aceptacion de Practicas Pre ProfesionalesDocumento2 páginasCarta de Aceptacion de Practicas Pre ProfesionalesJuan BreAún no hay calificaciones
- Analisis Rio ChilcaDocumento22 páginasAnalisis Rio ChilcaJuan BreAún no hay calificaciones
- Acuerdo de Promoción Comercial PERÚ-EEDocumento33 páginasAcuerdo de Promoción Comercial PERÚ-EEJuan BreAún no hay calificaciones
- Shirley IndiceDocumento26 páginasShirley IndiceJuan BreAún no hay calificaciones
- Agenda Jon OchoaDocumento12 páginasAgenda Jon OchoaJuan BreAún no hay calificaciones
- Informe 1Documento12 páginasInforme 1Juan BreAún no hay calificaciones
- Areas Como ItemDocumento30 páginasAreas Como ItemJuan BreAún no hay calificaciones
- Ejemplo SecuenciaciónDocumento7 páginasEjemplo SecuenciaciónJuan BreAún no hay calificaciones
- Talleres Algebra LinealDocumento15 páginasTalleres Algebra LinealMiguel CruzAún no hay calificaciones
- Nutricion e HigieneDocumento4 páginasNutricion e HigieneYazmilda DiazAún no hay calificaciones
- Guia Autonoma - 2Documento5 páginasGuia Autonoma - 2Gislaynne GJAún no hay calificaciones
- BMCDocumento4 páginasBMCRocío Gutiérrez de CabiedesAún no hay calificaciones
- Paredes Rolando Estudio de Pre-Factibilidad para Implementar Una Empresa Exportadora de Prendas de Vestir Elaboradas Con Fibras NaturalesDocumento113 páginasParedes Rolando Estudio de Pre-Factibilidad para Implementar Una Empresa Exportadora de Prendas de Vestir Elaboradas Con Fibras NaturalessharonAún no hay calificaciones
- Aspecto LiterarioDocumento7 páginasAspecto LiterarioMoni PimientoAún no hay calificaciones
- Material 13 EstrategiaDocumento5 páginasMaterial 13 EstrategiaJaime Mauricio Caceres LealAún no hay calificaciones
- Encuentro de Empresarias Campaña 8Documento243 páginasEncuentro de Empresarias Campaña 8kittyAún no hay calificaciones
- LV-03 Lista Verificacion Instrumentos de MedicionDocumento1 páginaLV-03 Lista Verificacion Instrumentos de MedicionFabian FloresAún no hay calificaciones
- Laboratorio-1. MedicionesDocumento9 páginasLaboratorio-1. MedicionesCarlos Lara B.Aún no hay calificaciones
- 4 Informe de Laboratorio - Dogma Central de La Biología Molecular y Secuencia NucleótidaDocumento12 páginas4 Informe de Laboratorio - Dogma Central de La Biología Molecular y Secuencia NucleótidaAndrews DiestraAún no hay calificaciones
- Las Relaciones Entre España Y China, Una Larga HistoriaDocumento13 páginasLas Relaciones Entre España Y China, Una Larga HistoriaLaura AbrilAún no hay calificaciones
- Economía II. Bloque II. Actividades 6, 7, 8 y 9.Documento6 páginasEconomía II. Bloque II. Actividades 6, 7, 8 y 9.Gustavo MartínezAún no hay calificaciones
- Contrato de Prestacin de Servicios Con Ingreso Asimilable A SalariosDocumento4 páginasContrato de Prestacin de Servicios Con Ingreso Asimilable A SalariosGuilledelarosaAún no hay calificaciones
- Conalbos02 02Documento20 páginasConalbos02 02DERECHOTK.COMAún no hay calificaciones
- Curso ManoloDocumento1 páginaCurso ManoloJosé Fernando Villatoro LópezAún no hay calificaciones
- A Homenaje Dia de La BanderaDocumento3 páginasA Homenaje Dia de La BanderaRosalinda TrujilloAún no hay calificaciones
- Los Coacervados de OparinDocumento2 páginasLos Coacervados de OparinRamzenyGonzalezAún no hay calificaciones
- Autoestima y AgresividadDocumento64 páginasAutoestima y AgresividadH Billy Bustamante100% (2)
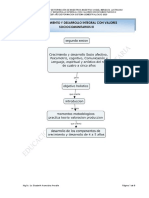
- U.F Crecimiento Y Desarrollo Integral Con Valores Sociocomunitarios IiiDocumento8 páginasU.F Crecimiento Y Desarrollo Integral Con Valores Sociocomunitarios IiiPriscila PardoAún no hay calificaciones
- Generos Discurcivos 1Documento2 páginasGeneros Discurcivos 1Tachi HaMAún no hay calificaciones
- MANUAL de Habilidades 8 11Documento99 páginasMANUAL de Habilidades 8 11AnyelaMeviAún no hay calificaciones
- Clase 1 Introduccion A La Gastronomia Historia y Evolucion de La Cocina Terminos y Principios Basicos de La GastronomiaDocumento20 páginasClase 1 Introduccion A La Gastronomia Historia y Evolucion de La Cocina Terminos y Principios Basicos de La GastronomiaMafer Zaid25% (4)
- Directorio Medios de TransporteDocumento38 páginasDirectorio Medios de TransporteAlexandra FerreiraAún no hay calificaciones
- AnclasDocumento5 páginasAnclasRoy San100% (1)
- Herpes Zoster y Medicina AlternativaDocumento7 páginasHerpes Zoster y Medicina AlternativaHM1468078100% (1)
- Problemas Sección BDocumento5 páginasProblemas Sección BRené ParedesAún no hay calificaciones
- Actividad 6 - Susana TepepaDocumento7 páginasActividad 6 - Susana TepepaSusana Tepepa ArenasAún no hay calificaciones
- PERSONALIDADESDocumento2 páginasPERSONALIDADESCristian BlancoAún no hay calificaciones
- Estrategias de Publicidad Bolsa Biodegradables.Documento3 páginasEstrategias de Publicidad Bolsa Biodegradables.Iván Márquez GuevaraAún no hay calificaciones