También podría gustarte
- Caso Clinico de Cetoacidosis DiabeticaDocumento32 páginasCaso Clinico de Cetoacidosis DiabeticaOlenka Peralta100% (1)
- Diagrama de Flujo Del CaféDocumento9 páginasDiagrama de Flujo Del CaféAlexCajasAún no hay calificaciones
- Toyota 3TDocumento4 páginasToyota 3Tromeo83% (6)
- Triptico La Señalizacion y Zonas Seguras 1 ComprimidoDocumento2 páginasTriptico La Señalizacion y Zonas Seguras 1 ComprimidoHêrrerâ Vhågnër100% (1)
- Bioètica & Debat Principios de Ética Biomédica Beauchamp-ChildressDocumento20 páginasBioètica & Debat Principios de Ética Biomédica Beauchamp-ChildressdanmercAún no hay calificaciones
- El Lugar Del Hombre PDFDocumento10 páginasEl Lugar Del Hombre PDFElderAún no hay calificaciones
- Principios de ética biomédica de Beauchamp y ChildressDocumento22 páginasPrincipios de ética biomédica de Beauchamp y ChildressFernanda Rubio Ferrada0% (1)
- Dig Manual de Habilidades Comunicacionales UDELAR 1Documento87 páginasDig Manual de Habilidades Comunicacionales UDELAR 1PattySanchez100% (1)
- Estudios de Casos y ControlesDocumento13 páginasEstudios de Casos y ControlesClaudiaa QuinteroAún no hay calificaciones
- El Mundo Arabe y La MedicinaDocumento13 páginasEl Mundo Arabe y La MedicinaJose Rafael CeballosAún no hay calificaciones
- Patogenia y Tratamiento de Las Enfermedades Gingivo-PeriodontalesDocumento23 páginasPatogenia y Tratamiento de Las Enfermedades Gingivo-PeriodontalesmiltonlafebreAún no hay calificaciones
- Bioetica en Odontologia@Documento18 páginasBioetica en Odontologia@Virginia NavarroAún no hay calificaciones
- PDF Caliban y La BrujaDocumento376 páginasPDF Caliban y La BrujaGeorgina Méndez100% (1)
- Metodo de Bioetica Diego Gracia PDFDocumento21 páginasMetodo de Bioetica Diego Gracia PDFEduardo A. Roca Oliver100% (2)
- Determinantes sociales y su relación con caries en niños de 1 a 5 añosDocumento11 páginasDeterminantes sociales y su relación con caries en niños de 1 a 5 añosmiltonlafebreAún no hay calificaciones
- Sobre La Salud ColectivaDocumento6 páginasSobre La Salud ColectivamiltonlafebreAún no hay calificaciones
- V28n2a06 PDFDocumento24 páginasV28n2a06 PDFmiltonlafebreAún no hay calificaciones
- Alma AtaDocumento8 páginasAlma AtamiltonlafebreAún no hay calificaciones
- Plan Nacional de Salud Bucal EcuadorDocumento35 páginasPlan Nacional de Salud Bucal EcuadorPablo Andrés ErazoAún no hay calificaciones
- Ministerio de Salud - PlataformaDocumento2 páginasMinisterio de Salud - PlataformamiltonlafebreAún no hay calificaciones
- Cap 2Documento6 páginasCap 2Pablo SantibañezAún no hay calificaciones
- Lecciones del MCC para mejorar la atención obstétrica y neonatalDocumento63 páginasLecciones del MCC para mejorar la atención obstétrica y neonatalKaro Flores Oquendo50% (2)
- Revista Facultad Nacional de Salud Pública 0120-386X: Issn: Revistasaludpublica@udea - Edu.coDocumento10 páginasRevista Facultad Nacional de Salud Pública 0120-386X: Issn: Revistasaludpublica@udea - Edu.comiltonlafebreAún no hay calificaciones
- U Sos y Límites de La Reflexividad en La Obra de A Nthony G IddensDocumento23 páginasU Sos y Límites de La Reflexividad en La Obra de A Nthony G IddensmiltonlafebreAún no hay calificaciones
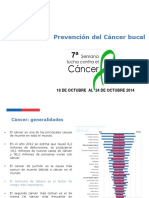
- 7ma Semana Cancer - Prevención Cáncer Bucal 2014Documento31 páginas7ma Semana Cancer - Prevención Cáncer Bucal 2014miltonlafebreAún no hay calificaciones
- UploadDocumento6 páginasUploadmiltonlafebreAún no hay calificaciones
- Mujer Embarazada en El Consul To RioDocumento5 páginasMujer Embarazada en El Consul To RiopactyAún no hay calificaciones
- Para VicentaDocumento7 páginasPara VicentamiltonlafebreAún no hay calificaciones
- Numero 31Documento4 páginasNumero 31miltonlafebreAún no hay calificaciones
- 08 Articulo7 PDFDocumento28 páginas08 Articulo7 PDFmiltonlafebreAún no hay calificaciones
- La Atencion Primaria de Salud, Mas Necesaria Que Nunca (Libro de La OPS) PDFDocumento154 páginasLa Atencion Primaria de Salud, Mas Necesaria Que Nunca (Libro de La OPS) PDFValeria GarciaAún no hay calificaciones
- Revista Facultad Nacional de Salud Pública 0120-386X: Issn: Revistasaludpublica@udea - Edu.coDocumento10 páginasRevista Facultad Nacional de Salud Pública 0120-386X: Issn: Revistasaludpublica@udea - Edu.comiltonlafebreAún no hay calificaciones
- Normas de Redaccion Editorial 2015-1Documento3 páginasNormas de Redaccion Editorial 2015-1miltonlafebreAún no hay calificaciones
- John Wesley y La EconomíaDocumento3 páginasJohn Wesley y La EconomíaAntony Morales RojasAún no hay calificaciones
- Hisopado de ManosDocumento2 páginasHisopado de ManosMario Alexander GómezAún no hay calificaciones
- Efemerides de Enero, Febrero, Marzo y Abril. Zoraida España Abono 110Documento25 páginasEfemerides de Enero, Febrero, Marzo y Abril. Zoraida España Abono 110Milagros E Avila RagaAún no hay calificaciones
- Seguridad en Redes PDFDocumento16 páginasSeguridad en Redes PDFMIGUEL ANGEL VELASQUEZ HOLGUINAún no hay calificaciones
- Noticias AlimarketDocumento13 páginasNoticias AlimarketCcoo MahouAún no hay calificaciones
- Prueba Modelos AtomicosDocumento4 páginasPrueba Modelos AtomicosSergiopoli ValdiviaAún no hay calificaciones
- DD - Inspección Preoperacional de Tracto CamiónDocumento1 páginaDD - Inspección Preoperacional de Tracto CamiónGILMA DIAZAún no hay calificaciones
- Actividad 8 Taller FinalDocumento14 páginasActividad 8 Taller FinalNatalia MosqueraAún no hay calificaciones
- Modelar puente con derivadasDocumento7 páginasModelar puente con derivadasEduardo MedinaAún no hay calificaciones
- Ciclo Del AzufreDocumento8 páginasCiclo Del AzufreYohandri PalacioAún no hay calificaciones
- Presentacion BiorremediaciónDocumento16 páginasPresentacion BiorremediaciónJesus hernadezAún no hay calificaciones
- Elementos de Máquinas - AulasDocumento577 páginasElementos de Máquinas - AulasPedro Rhoden100% (1)
- Psicologia Social-Febrero 2001A 1S (Apuntes Examenes Psicologia Uned Esquemas Resumen)Documento7 páginasPsicologia Social-Febrero 2001A 1S (Apuntes Examenes Psicologia Uned Esquemas Resumen)ppedrooAún no hay calificaciones
- Clase 12 Décimo Antropologia AristotelicaDocumento6 páginasClase 12 Décimo Antropologia Aristotelicaisabella boteroAún no hay calificaciones
- Informe Desafectacion - Flores de Valle HermosoDocumento6 páginasInforme Desafectacion - Flores de Valle HermosoPaul Benavides VargasAún no hay calificaciones
- Formato Control para Alcohol y DrogasDocumento2 páginasFormato Control para Alcohol y DrogasRockataAún no hay calificaciones
- Componentes de Electronicos de RiesgoDocumento4 páginasComponentes de Electronicos de RiesgoRyan Rangel AmadorAún no hay calificaciones
- El Don de VolarDocumento284 páginasEl Don de VolarMaria Claudia Munevar GoldsteinAún no hay calificaciones
- DF18 Final LR SpanishDocumento61 páginasDF18 Final LR Spanishramon perezAún no hay calificaciones
- Modulo 3 Kelly SamillanDocumento7 páginasModulo 3 Kelly SamillankellyAún no hay calificaciones
- Proceso de Elaboración Del CalzadoDocumento6 páginasProceso de Elaboración Del CalzadoKerin rubi Zapata santistebanAún no hay calificaciones
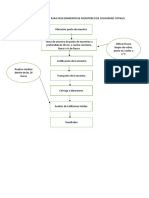
- Diagrama de Bloque para Procedimiento de Monitoreo de Coliformes TotalesDocumento3 páginasDiagrama de Bloque para Procedimiento de Monitoreo de Coliformes TotalesRoberto BrunaAún no hay calificaciones
- 10 Soluciones QuímicasDocumento4 páginas10 Soluciones QuímicasIlbar JohnnyAún no hay calificaciones
- 2007 InformeTecnico POI GR12 Cuenca Casma Yacimientos Acosta PDFDocumento32 páginas2007 InformeTecnico POI GR12 Cuenca Casma Yacimientos Acosta PDFjenyn silvestre chavarriaAún no hay calificaciones
- Patakines IneditosDocumento419 páginasPatakines IneditosAlejandro PerezAún no hay calificaciones
- CHILCORROFIN - Chilcourea 285Documento2 páginasCHILCORROFIN - Chilcourea 285Cristóbal BerríosAún no hay calificaciones