También podría gustarte
- Plan de Mantenimiento Preventivo y Correctivo de Vehículos y EquiposDocumento13 páginasPlan de Mantenimiento Preventivo y Correctivo de Vehículos y EquiposAngel Wladimir Osorio Rodriguez75% (4)
- Java 2: Manual de Usuario y Tutorial. 5ª EdiciónDe EverandJava 2: Manual de Usuario y Tutorial. 5ª EdiciónAún no hay calificaciones
- Diseño de Experimentos: Estrategias y análisis en ciencias e ingenieríasDe EverandDiseño de Experimentos: Estrategias y análisis en ciencias e ingenieríasAún no hay calificaciones
- Producción Musical Con REAPERDocumento4 páginasProducción Musical Con REAPERHeraldo Lizama DassoAún no hay calificaciones
- Scripts en Linux 01Documento66 páginasScripts en Linux 01Mario RoblesAún no hay calificaciones
- Pa 03 - Laboratorio de Innovacion EnviarDocumento8 páginasPa 03 - Laboratorio de Innovacion EnviarZAIDA YUDY HUARANCCA TAPARAAún no hay calificaciones
- Soluciones Ejercicios de LinuxDocumento4 páginasSoluciones Ejercicios de Linuxlolomano2Aún no hay calificaciones
- Especificaciones Tecnicas EquipamientoDocumento38 páginasEspecificaciones Tecnicas EquipamientoJorge Malaga Villanueva100% (1)
- Apuntes Arduino Nivel EnterailloDocumento28 páginasApuntes Arduino Nivel EnterailloRey Arturo100% (7)
- Programación Básica Pseudocódigo - PSeIntDocumento32 páginasProgramación Básica Pseudocódigo - PSeIntAndres Felipe VelezAún no hay calificaciones
- Apuntes Arduino Nivel PardilloDocumento30 páginasApuntes Arduino Nivel PardilloMario Peña100% (4)
- Modelo de Datos Ga3 220501113 Aa2 Ev01Documento7 páginasModelo de Datos Ga3 220501113 Aa2 Ev01Fernando Granados100% (1)
- PortfolioDocumento36 páginasPortfolioarielsrojas24Aún no hay calificaciones
- La Educacion Basada en Competencias Magda Cejas PDFDocumento22 páginasLa Educacion Basada en Competencias Magda Cejas PDFEdvin OrellanaAún no hay calificaciones
- Tutorial RubyDocumento14 páginasTutorial RubyMarco AntAún no hay calificaciones
- Estándar de Codificación en PLSQLDocumento11 páginasEstándar de Codificación en PLSQLGaby TrunsoAún no hay calificaciones
- C AvanzadoDocumento22 páginasC AvanzadoPedro PalaciosAún no hay calificaciones
- GUIAMATLABDocumento19 páginasGUIAMATLABhitomisan01Aún no hay calificaciones
- Certificación SAP TAW10 - 1 Capitulos 7 & 8Documento14 páginasCertificación SAP TAW10 - 1 Capitulos 7 & 8HikaruKirishimaAún no hay calificaciones
- Microprocesadores y Unidades de MedidaDocumento20 páginasMicroprocesadores y Unidades de MedidaDonaldo Leonel Vargas AnguloAún no hay calificaciones
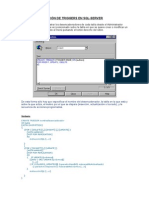
- Guia para Creación de Triggers en SQL-serverDocumento5 páginasGuia para Creación de Triggers en SQL-serverrafa3084Aún no hay calificaciones
- ORACLE Les03 Funciones de Una Sola FilaDocumento47 páginasORACLE Les03 Funciones de Una Sola FilaJonatan SanchezAún no hay calificaciones
- EWAN Lab 3 5 1Documento25 páginasEWAN Lab 3 5 1Raul GomezAún no hay calificaciones
- Enunciado Ejercicios MIPS 1Documento4 páginasEnunciado Ejercicios MIPS 1Fabiola JaldinAún no hay calificaciones
- Guia 10Documento13 páginasGuia 10Restom7Aún no hay calificaciones
- Sistemas Lineales para AutomatizacionDocumento14 páginasSistemas Lineales para AutomatizacionAlejandro González GonzálezAún no hay calificaciones
- Manual Referencia Qcad PDFDocumento119 páginasManual Referencia Qcad PDFfagonzalez1958Aún no hay calificaciones
- (1library - Co) Metodos Numericos Aplicados A La MineriaDocumento61 páginas(1library - Co) Metodos Numericos Aplicados A La MineriaWILMAN AULLA CARDENASAún no hay calificaciones
- Manual PHP ResumidoDocumento30 páginasManual PHP Resumidojoseluis93mlg100% (1)
- IptablesDocumento15 páginasIptablesAguedo HuamaniAún no hay calificaciones
- Crear Un Webservice Básico Con PHP y SoapDocumento3 páginasCrear Un Webservice Básico Con PHP y SoapMarco Antonio LetelierAún no hay calificaciones
- CDocumento47 páginasCsheya2Aún no hay calificaciones
- Práctica CHAMELEON - Jacerong & TlozanoaDocumento5 páginasPráctica CHAMELEON - Jacerong & TlozanoajuandkpaAún no hay calificaciones
- Práctica de Laboratorio 7.4.1 - Configuración Básica de DHCP y NATDocumento9 páginasPráctica de Laboratorio 7.4.1 - Configuración Básica de DHCP y NATAlan JuárezAún no hay calificaciones
- Paper PHPDocumento21 páginasPaper PHPHenry FernandezAún no hay calificaciones
- Comandos Basicos Terminal UbuntuDocumento34 páginasComandos Basicos Terminal UbuntuMarcelino MartinezAún no hay calificaciones
- Quick SortDocumento10 páginasQuick SortLuis Alvarez VargasAún no hay calificaciones
- SPSS Apuntes y TrabajosDocumento44 páginasSPSS Apuntes y Trabajosvelisa815986Aún no hay calificaciones
- Apuntes Arduino Nivel PardilloDocumento30 páginasApuntes Arduino Nivel PardilloAlfonso FernándezAún no hay calificaciones
- Grafos de PrecedenciaDocumento27 páginasGrafos de PrecedenciaMatias SerapioAún no hay calificaciones
- Funciones Cal y While FANUC LR Mate 200icDocumento3 páginasFunciones Cal y While FANUC LR Mate 200icserolfitnas100% (1)
- Pract 1 RDocumento29 páginasPract 1 RMario AlvarezAún no hay calificaciones
- Manual PHPDocumento19 páginasManual PHPminodragoAún no hay calificaciones
- POO Punteros en CDocumento29 páginasPOO Punteros en CCristian Javier ArtosAún no hay calificaciones
- Que Es Una VariableDocumento42 páginasQue Es Una VariableJosué RomeroAún no hay calificaciones
- CS 11-6-1 B Grupo 5Documento19 páginasCS 11-6-1 B Grupo 5Anderson Joel Navarro YarlequeAún no hay calificaciones
- Eliminar Numero Par de La Cola y Retornar Los Valores InmvertidosDocumento7 páginasEliminar Numero Par de La Cola y Retornar Los Valores InmvertidosOscar Benites SkarlataAún no hay calificaciones
- Principios Básicos de Las SubRedesDocumento3 páginasPrincipios Básicos de Las SubRedesAlfonso VarelaAún no hay calificaciones
- Ruby Cucumber Automation 1.2-20130831Documento74 páginasRuby Cucumber Automation 1.2-20130831Nico DziubanAún no hay calificaciones
- 3 PHP BasicoDocumento30 páginas3 PHP BasicoanderAún no hay calificaciones
- Estadística y Programación LinealDocumento4 páginasEstadística y Programación LinealegbaquelaAún no hay calificaciones
- Metodos para Hackear Wifi WpaDocumento7 páginasMetodos para Hackear Wifi WpaNobitoPlayAún no hay calificaciones
- Nat CiscoDocumento7 páginasNat CiscoErly Joel Flores PerezAún no hay calificaciones
- Tutorial JSONDocumento12 páginasTutorial JSONjace1960Aún no hay calificaciones
- Comandos OSIDocumento3 páginasComandos OSIAlfredAún no hay calificaciones
- Ojos que no ven, corazón que no siente: Relocalización territorial y conflictividad social: un estudio sobre los barrios ciudades de CórdobaDe EverandOjos que no ven, corazón que no siente: Relocalización territorial y conflictividad social: un estudio sobre los barrios ciudades de CórdobaAún no hay calificaciones
- La inversión por atención y su efecto en los rendimientos bursátilesDe EverandLa inversión por atención y su efecto en los rendimientos bursátilesAún no hay calificaciones
- Medios InformáticosDocumento2 páginasMedios InformáticosJose EsquivelAún no hay calificaciones
- Como Instalar Roundcube Webmail en CentOS - ProgramaciónDocumento4 páginasComo Instalar Roundcube Webmail en CentOS - ProgramaciónAlexander Paredes SaraviaAún no hay calificaciones
- Investigacion de ASPOVITDocumento47 páginasInvestigacion de ASPOVITJEZZICA JOSEFA GRAJALES OSORIOAún no hay calificaciones
- Presentación AduanasDocumento8 páginasPresentación Aduanasangelica sotoAún no hay calificaciones
- CVND Im JCD 2022Documento12 páginasCVND Im JCD 2022Javier Raul Cardenas DuranAún no hay calificaciones
- Reactivos de Examen Diagnóstico Uso Eficiente de La EnergíaDocumento3 páginasReactivos de Examen Diagnóstico Uso Eficiente de La Energíamaria DiLaurentisAún no hay calificaciones
- Indice de Un Econegocio CacaoDocumento19 páginasIndice de Un Econegocio CacaodianaakeAún no hay calificaciones
- Libro Texto Alexis LabarcaDocumento96 páginasLibro Texto Alexis LabarcaDante Gonzalo Sacravilca Narciso100% (1)
- Articulo Analisis Frecuencia (400-2400) MHZ en EcuadorDocumento8 páginasArticulo Analisis Frecuencia (400-2400) MHZ en EcuadorEfra AlcoserAún no hay calificaciones
- Ep2 Adrianno VallejosDocumento3 páginasEp2 Adrianno VallejosAdrianno VallejosAún no hay calificaciones
- Modelo Dimensional de La InnovaciónDocumento3 páginasModelo Dimensional de La InnovaciónMario michea cortesAún no hay calificaciones
- INFORME DE LABORATORIO No 1. MANEJO DE PHET, TINKERCAD Y SOLVE ELECDocumento9 páginasINFORME DE LABORATORIO No 1. MANEJO DE PHET, TINKERCAD Y SOLVE ELECOLNEDYS DEL CARMEN MILLAN POLOAún no hay calificaciones
- U4 Act 2 Técnicas Marín Carbajal Luis ArhamDocumento3 páginasU4 Act 2 Técnicas Marín Carbajal Luis ArhamLuis Arham Marin CarbajalAún no hay calificaciones
- Adquisicion de Datos Con LabviewDocumento19 páginasAdquisicion de Datos Con LabviewrubenAún no hay calificaciones
- Grupo 5 - Lab 8 y 9Documento20 páginasGrupo 5 - Lab 8 y 9paulAún no hay calificaciones
- Ejercicios de Ingeniería de SoftwareDocumento11 páginasEjercicios de Ingeniería de SoftwareFrancisco ReinaAún no hay calificaciones
- POSFIXDocumento18 páginasPOSFIXCristian Matus FierroAún no hay calificaciones
- Dibujo de Ingenieria - 16-01 - Tarea 1Documento12 páginasDibujo de Ingenieria - 16-01 - Tarea 1Laura ReyesAún no hay calificaciones
- Comunicación Digital y AnalógicaDocumento2 páginasComunicación Digital y AnalógicaEduardo FernandezAún no hay calificaciones
- Codigos de Servicio Impresoras HP, Acceso A MantenimientoDocumento17 páginasCodigos de Servicio Impresoras HP, Acceso A MantenimientoIngeniería Proyectos y Servicios CarupanoAún no hay calificaciones
- Trabajo de Exposición #01Documento4 páginasTrabajo de Exposición #01Ronaldo Estrada MamaniAún no hay calificaciones
- Catalogo Vertical 2014 PDFDocumento24 páginasCatalogo Vertical 2014 PDFStgAún no hay calificaciones
- Conexion Mysql y PHPDocumento47 páginasConexion Mysql y PHPjesus gabriel gutierrezAún no hay calificaciones
- Practica Laboratorio Analisis ForenseDocumento3 páginasPractica Laboratorio Analisis ForenseFERNANDO APAZAAún no hay calificaciones