También podría gustarte
- Seccion 2.7 y 2.8Documento15 páginasSeccion 2.7 y 2.8Josehiner Guerrero0% (1)
- Regresion No LinealDocumento10 páginasRegresion No LinealSan Marcos Estadistica80% (5)
- Distribucion Hipergeometrica AlumnoDocumento13 páginasDistribucion Hipergeometrica AlumnoSara Elena Cruz Román0% (1)
- Apuntes Probabilidad EstadisticaDocumento49 páginasApuntes Probabilidad EstadisticaRaulAún no hay calificaciones
- Variables Aleatorias Continuas... SimulacionDocumento16 páginasVariables Aleatorias Continuas... SimulacionLucero GonMunAún no hay calificaciones
- Problema 11.104 (Dinámica Beer 8ed)Documento2 páginasProblema 11.104 (Dinámica Beer 8ed)Miguel Antonio Bula Picón80% (5)
- Lineal Matrices PDFDocumento25 páginasLineal Matrices PDFLuis AndradeAún no hay calificaciones
- Regresion y Correlacion LinealDocumento24 páginasRegresion y Correlacion LinealYariko Chie100% (1)
- Regresion y Correlacion 2022-1Documento14 páginasRegresion y Correlacion 2022-1HeydiAún no hay calificaciones
- Regresion No LinealDocumento32 páginasRegresion No LinealEdson Valery Ramos PeñalozaAún no hay calificaciones
- Regresión No LinealDocumento23 páginasRegresión No Linealdanielbox21Aún no hay calificaciones
- Regresión No Lineal Logarítmica y Exponencial PDFDocumento9 páginasRegresión No Lineal Logarítmica y Exponencial PDFMireya LuctualaAún no hay calificaciones
- Regresion No Lineal...Documento44 páginasRegresion No Lineal...Edwin Quispe100% (2)
- Estadistica Descriptiva-ConceptosDocumento27 páginasEstadistica Descriptiva-Conceptoscgolivos9764100% (1)
- Aplicaciones de La DerivadaDocumento7 páginasAplicaciones de La DerivadaSebastian RamosAún no hay calificaciones
- Conceptos de Bocos 2 UnidadDocumento30 páginasConceptos de Bocos 2 UnidadAnonymous C5BinIaEqd100% (1)
- Intervalos de Confianza para La Diferencia de ProporcionesDocumento17 páginasIntervalos de Confianza para La Diferencia de Proporcionesel_javi1100% (1)
- Inecuaciones Cuadráticas o de Segundo GradoDocumento4 páginasInecuaciones Cuadráticas o de Segundo Gradosantiagomustiga73% (11)
- Ruta Gastronomica Tlatlauquitepec Proyecto FinalDocumento62 páginasRuta Gastronomica Tlatlauquitepec Proyecto FinalRoman Carmona GuerreroAún no hay calificaciones
- Etapa de Análisis e Interpretación de Datos Medidas de ResumenDocumento41 páginasEtapa de Análisis e Interpretación de Datos Medidas de ResumenBrayan Chopra100% (1)
- Estadistica en Una EmpresaDocumento4 páginasEstadistica en Una EmpresaSebastian Cruz HernandezAún no hay calificaciones
- DISTRIBUCIONES MUESTRALES SemifinalDocumento22 páginasDISTRIBUCIONES MUESTRALES SemifinalDavidCalleAlamoAún no hay calificaciones
- Distribuciones de ProbabilidadDocumento57 páginasDistribuciones de ProbabilidadMona VegaoliAún no hay calificaciones
- 417 - Modelos de RegresiónDocumento16 páginas417 - Modelos de RegresiónpuanAún no hay calificaciones
- Semana 10 Medidas de DispersiónDocumento48 páginasSemana 10 Medidas de DispersiónCamila Tam100% (1)
- Regresion PoissonDocumento22 páginasRegresion PoissonFran ChristianAún no hay calificaciones
- Variables Aleatorias Discretas y ContinuasDocumento9 páginasVariables Aleatorias Discretas y ContinuasImelda BarrazaAún no hay calificaciones
- 1.-Teoria - Analisis de Regresion Lineal y Multiple PDFDocumento36 páginas1.-Teoria - Analisis de Regresion Lineal y Multiple PDFEstefani Herrera CerrónAún no hay calificaciones
- Prueba de HipotesisDocumento21 páginasPrueba de HipotesisFátima VegaAún no hay calificaciones
- Regresión No LinealDocumento47 páginasRegresión No LinealMaría Melissa López TorresAún no hay calificaciones
- Esperanza MatemáticaDocumento4 páginasEsperanza MatemáticaEmily Belén Aguilar VeraAún no hay calificaciones
- Vector Tangente, Normal, Binormal y CurvaturaDocumento9 páginasVector Tangente, Normal, Binormal y CurvaturaMaryli DAún no hay calificaciones
- Metodos Regresion CuadraticaDocumento19 páginasMetodos Regresion CuadraticaJavier Serrepe GuevaraAún no hay calificaciones
- Covarianza EstudiantesDocumento3 páginasCovarianza EstudiantesYeison delgadoAún no hay calificaciones
- Gauss, Jordan, Inversa de Una Matriz y Regla de Cramer JORGE EDUARDO HDZ CHAVEZ PDFDocumento15 páginasGauss, Jordan, Inversa de Una Matriz y Regla de Cramer JORGE EDUARDO HDZ CHAVEZ PDFsara catalina velazquez garciaAún no hay calificaciones
- Distribuciones BidimensionalesDocumento12 páginasDistribuciones BidimensionalesKarinaAún no hay calificaciones
- Prueba de Kolmogorov-SmirnovDocumento10 páginasPrueba de Kolmogorov-SmirnovIgnacioAún no hay calificaciones
- Números ÍndicesDocumento64 páginasNúmeros ÍndicesMaricel Anahi Carbajal SantacruzAún no hay calificaciones
- 3cera Edi 6 Libro Estadistica y Diseno de ExperimentosDocumento24 páginas3cera Edi 6 Libro Estadistica y Diseno de ExperimentoshaiderenriqueAún no hay calificaciones
- Variables Aleatorias Discretas Y2 PDFDocumento56 páginasVariables Aleatorias Discretas Y2 PDFluisAún no hay calificaciones
- Probabilidad ClasicaDocumento4 páginasProbabilidad ClasicaAlejandraAún no hay calificaciones
- Modelos No LinealesDocumento14 páginasModelos No LinealesDaniel AcuñaAún no hay calificaciones
- Unmsm REGRESIONESDocumento9 páginasUnmsm REGRESIONESJose AntonioAún no hay calificaciones
- Función Escalón UnitarioDocumento11 páginasFunción Escalón UnitarioCoral Guzman GuzmanAún no hay calificaciones
- EstadisticaDocumento20 páginasEstadisticaLibertad MachucaAún no hay calificaciones
- Minimos CuadradosDocumento7 páginasMinimos CuadradosDiana SanchezAún no hay calificaciones
- Unidad 2 Intervalos de ConfianzaDocumento34 páginasUnidad 2 Intervalos de ConfianzaShei MoranAún no hay calificaciones
- Analisis de La Operaciones Los Diez Enfoques PrimariosDocumento10 páginasAnalisis de La Operaciones Los Diez Enfoques PrimariosSTALTHAM99Aún no hay calificaciones
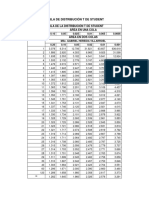
- Tabla de Distribución T de StudentDocumento1 páginaTabla de Distribución T de StudentGabriel Heredia100% (1)
- Números Índices - Agregación PonderadaDocumento4 páginasNúmeros Índices - Agregación PonderadaMaricel Anahi Carbajal SantacruzAún no hay calificaciones
- Silabo EconomiaDocumento12 páginasSilabo EconomiaGeorge Castillo FarfánAún no hay calificaciones
- Prueba de Hipotesis Distribucion Normal y Distribucion TDocumento4 páginasPrueba de Hipotesis Distribucion Normal y Distribucion TKarly Aguirre86% (7)
- Sesión 3.3 Medidas de Dispersión y FormaDocumento29 páginasSesión 3.3 Medidas de Dispersión y FormaLuis Manuel Huaman MartinesAún no hay calificaciones
- HCRL Unidad 5Documento22 páginasHCRL Unidad 5hannia rdzAún no hay calificaciones
- Eficiencia de Los Estimadores. Muestreo SistemáticoDocumento7 páginasEficiencia de Los Estimadores. Muestreo SistemáticoJuan Carlos TalaveraAún no hay calificaciones
- ESTADÍSTICA NO PARAMÉTRICA - LibrosDocumento9 páginasESTADÍSTICA NO PARAMÉTRICA - LibrosIluminada Martínez AlbaladejoAún no hay calificaciones
- Numeros ComplejosDocumento16 páginasNumeros ComplejosFelipe AndreauAún no hay calificaciones
- Clase Bioestadistica Normal 10Documento46 páginasClase Bioestadistica Normal 10Alejandro DiazAún no hay calificaciones
- Métodos Cerrados para Solucionar Ecuaciones No Lineales.Documento17 páginasMétodos Cerrados para Solucionar Ecuaciones No Lineales.AlejandraAún no hay calificaciones
- Tema 5 EstadísticaDocumento4 páginasTema 5 EstadísticaPilar MuÑoz100% (1)
- Análisis de Regresión-1Documento7 páginasAnálisis de Regresión-1San Marcos EstadisticaAún no hay calificaciones
- Tema 2. Construcción Modelo EstocásticoDocumento5 páginasTema 2. Construcción Modelo EstocásticoAuri OrozcoAún no hay calificaciones
- Estadistica Inferencial LSGDocumento18 páginasEstadistica Inferencial LSGGrace PetroAún no hay calificaciones
- 3 TAREA FUNCIÓN LINEAL (Segunda Parte) ABRIL 2021 Denise ShiguangoDocumento17 páginas3 TAREA FUNCIÓN LINEAL (Segunda Parte) ABRIL 2021 Denise ShiguangoREBECA CABRERAAún no hay calificaciones
- Gráficas de Funciones y Puntos de Retorno 2BGUDocumento9 páginasGráficas de Funciones y Puntos de Retorno 2BGUJoelAún no hay calificaciones
- ARI Tema 5 Generación de Trayectorias PDFDocumento16 páginasARI Tema 5 Generación de Trayectorias PDFJuan Aguilar GomezAún no hay calificaciones
- Ondas Viajeras UnidimensionalesDocumento5 páginasOndas Viajeras UnidimensionalesJHON BAYRON MARTINEZ RAMOSAún no hay calificaciones
- Integración de Funciones Reales PDFDocumento7 páginasIntegración de Funciones Reales PDFAdry MorrilloAún no hay calificaciones
- Inecuaciones Parte 6Documento7 páginasInecuaciones Parte 6ariel diazAún no hay calificaciones
- Formulario Matematicas Fime 2014Documento6 páginasFormulario Matematicas Fime 2014arnoldjovanyAún no hay calificaciones
- Método Simple de Iteración de Punto Fijo.Documento6 páginasMétodo Simple de Iteración de Punto Fijo.Miguel Colin0% (1)
- InvoperacionesDocumento48 páginasInvoperacionesWill Velazco0% (1)
- Numeros RealesDocumento9 páginasNumeros RealesAlexis Omar Poicon CornejoAún no hay calificaciones
- Proyecciones CartograficasDocumento24 páginasProyecciones CartograficasEdgardo Andrés Oviedo DíazAún no hay calificaciones
- Cap 02 FMDocumento26 páginasCap 02 FMMaria FernandezAún no hay calificaciones
- Activida 1 Fundamentos MatematicosDocumento5 páginasActivida 1 Fundamentos MatematicosFATIMA ORNELAS OROZCOAún no hay calificaciones
- Act 7 Ejercicios Ecuaciones DiferencialesDocumento7 páginasAct 7 Ejercicios Ecuaciones DiferencialesGUADALUPE CAMACHOAún no hay calificaciones
- Tarea 2 - EST IDocumento5 páginasTarea 2 - EST IEdison CarrascoAún no hay calificaciones
- Teorema de VarignónDocumento3 páginasTeorema de VarignónClaudia Dominguez0% (1)
- Integración de Funciones RacionalesDocumento9 páginasIntegración de Funciones RacionalesMiguel SánchezAún no hay calificaciones
- Práctica ÁLGEBRA TEMA 1Documento2 páginasPráctica ÁLGEBRA TEMA 1Alex Tapara Mantilla0% (1)
- Planificación Didáctica MM411 P2 2018Documento20 páginasPlanificación Didáctica MM411 P2 2018Alejandra NuñezAún no hay calificaciones
- CALCULO Unidad I Clase N°3Documento16 páginasCALCULO Unidad I Clase N°3Karen Berrios SotoAún no hay calificaciones
- Semana 2-T-24-IDocumento30 páginasSemana 2-T-24-IAngel Andres Rodriguez CarrilloAún no hay calificaciones
- AE+1+Metodo de Cuarta Integración 13 AGODocumento23 páginasAE+1+Metodo de Cuarta Integración 13 AGOAbel BenegasAún no hay calificaciones
- FICHA1.Progresión AritméticaDocumento8 páginasFICHA1.Progresión AritméticaDAVIDAún no hay calificaciones
- Practica 3 VA CONTINUA PDFDocumento12 páginasPractica 3 VA CONTINUA PDFDaniel Tres de JulioAún no hay calificaciones
- Ecuaciones de Primer Grado SextoDocumento77 páginasEcuaciones de Primer Grado SextoEthel xiomara Lara cortézAún no hay calificaciones