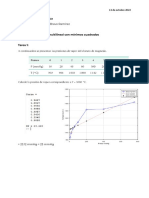
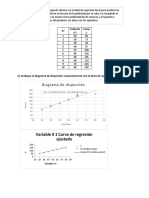
También podría gustarte
- Ejemplo Funcion Iteracion Punto FijoDocumento5 páginasEjemplo Funcion Iteracion Punto FijoMaximiliano Vaca MontejanoAún no hay calificaciones
- Programas Implementacion en Matlab ProyectoDocumento6 páginasProgramas Implementacion en Matlab ProyectoNALLELY CECILIA CORREA ARIZMENDIAún no hay calificaciones
- Diseño de Actividades Semana 6Documento2 páginasDiseño de Actividades Semana 6antonioAún no hay calificaciones
- Bondad Del AjusteDocumento7 páginasBondad Del AjusteRodrigo Loira Del RioAún no hay calificaciones
- Planeación Unidad 2 Análisis NuméricoDocumento10 páginasPlaneación Unidad 2 Análisis NuméricoManuel MontalvoAún no hay calificaciones
- Trabajo de Las Unidades 5 y 6.metodos CuantitativosDocumento18 páginasTrabajo de Las Unidades 5 y 6.metodos CuantitativosAngela0% (1)
- Modelos ProbabilisticosDocumento22 páginasModelos ProbabilisticosMARCO ANTONIO LUIS RAMIREZAún no hay calificaciones
- Teorema de CookDocumento33 páginasTeorema de CookAlejo AquiliAún no hay calificaciones
- Senales Sistemas DiscretosDocumento3 páginasSenales Sistemas DiscretosAngel FernandezAún no hay calificaciones
- TareaMinimosCuadrados2 ZabdiBravoDocumento8 páginasTareaMinimosCuadrados2 ZabdiBravoZabdi Bravo RamirezAún no hay calificaciones
- Algoritmos de Integracion NumericaDocumento21 páginasAlgoritmos de Integracion NumericaLilibeth ReyesAún no hay calificaciones
- Algoritmos AdaptativosDocumento3 páginasAlgoritmos AdaptativosAlexia PadillaAún no hay calificaciones
- CAPITULO8Documento43 páginasCAPITULO8TroxterPS3Aún no hay calificaciones
- Ejercicios 2.0Documento3 páginasEjercicios 2.0HEIDI FERNANDA AYTE BACAAún no hay calificaciones
- Guia. Introducción A JFLAP y Creación de AutómatasDocumento22 páginasGuia. Introducción A JFLAP y Creación de AutómatasAkademus GalileoAún no hay calificaciones
- Guía RedesDocumento5 páginasGuía RedesJuan-Pablo ContrerasAún no hay calificaciones
- Informe Redes NeuronalesDocumento18 páginasInforme Redes NeuronalesLuisAlfredoSullcaHuaraccaAún no hay calificaciones
- Cuestionario N°3Documento5 páginasCuestionario N°3ANA MELGARAún no hay calificaciones
- INVESTIGACION OPERATIVA (40537) Autoevalucion 1Documento5 páginasINVESTIGACION OPERATIVA (40537) Autoevalucion 1PUDDINAún no hay calificaciones
- Análisis de Los Métodos DescritosDocumento6 páginasAnálisis de Los Métodos DescritosMaria Fernanda Parra CardenasAún no hay calificaciones
- Resumen Metodos NumericosDocumento5 páginasResumen Metodos NumericosrrvvAún no hay calificaciones
- Problemas de Optimización y Diferencial de Una FunciónDocumento14 páginasProblemas de Optimización y Diferencial de Una FunciónJuan ChrAún no hay calificaciones
- 01 Uni 2023 I Segunda Prueba Admisión Universidad Ingeniería Matemática Respuestas Solucionario 2023-1 Claves PDFDocumento5 páginas01 Uni 2023 I Segunda Prueba Admisión Universidad Ingeniería Matemática Respuestas Solucionario 2023-1 Claves PDFvanhalenfernando123Aún no hay calificaciones
- Reconocimiento de Voz Usando Redes Neuron Ales ArtificialesDocumento24 páginasReconocimiento de Voz Usando Redes Neuron Ales ArtificialesFernando Vidal HerreraAún no hay calificaciones
- Actividad de Clase 1 3 Er ParcialDocumento18 páginasActividad de Clase 1 3 Er ParcialRube :vAún no hay calificaciones
- Mias U4 Ac LufaDocumento8 páginasMias U4 Ac LufaLuis DanielAún no hay calificaciones
- 1820776-Edson Raul Cepeda MarquezDocumento1 página1820776-Edson Raul Cepeda Marquezedson cepedaAún no hay calificaciones
- 1 1 2 PPT Generando Un AlgoritmoDocumento12 páginas1 1 2 PPT Generando Un AlgoritmoArquimides Larraguibel ArceAún no hay calificaciones
- Lagrange MultiplicadoresDocumento7 páginasLagrange MultiplicadoresEduardo SánchezAún no hay calificaciones
- MatlabDocumento12 páginasMatlabRodney PachacamaAún no hay calificaciones