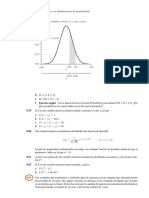
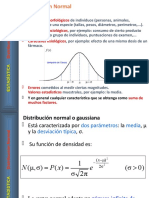
También podría gustarte
- Qué Es Una IntervenciónDocumento3 páginasQué Es Una IntervenciónAdriana RguezAún no hay calificaciones
- Plantilla para Documentar Reporte Inicial Inn ProductoDocumento7 páginasPlantilla para Documentar Reporte Inicial Inn ProductoAdriana RguezAún no hay calificaciones
- El Grupo SwatchDocumento5 páginasEl Grupo SwatchAdriana RguezAún no hay calificaciones
- Cómo Remover Tinta de Una Hoja de Papel Sin DañarlaDocumento4 páginasCómo Remover Tinta de Una Hoja de Papel Sin DañarlaAdriana Rguez33% (3)
- 3.3 Técnicas de Análisis InternoDocumento18 páginas3.3 Técnicas de Análisis InternoAdriana Rguez50% (6)
- 2.5 Analisis de Estructura de La IndustriaDocumento6 páginas2.5 Analisis de Estructura de La IndustriaAdriana Rguez0% (1)
- Conceptos Sociologia Como CienciaDocumento12 páginasConceptos Sociologia Como CienciaAdriana RguezAún no hay calificaciones
- 5.3 Recopilacion de Informacion-AdrianaDocumento9 páginas5.3 Recopilacion de Informacion-AdrianaAdriana RguezAún no hay calificaciones
- Constancia Ingresos 12-13-1Documento1 páginaConstancia Ingresos 12-13-1Adriana RguezAún no hay calificaciones
- En El Principio El Espíritu de DiosDocumento3 páginasEn El Principio El Espíritu de DiosAdriana RguezAún no hay calificaciones
- Parabola de Los TalentosDocumento2 páginasParabola de Los TalentosAdriana Rguez100% (1)
- Intervalo de Confianza para La VarianzaDocumento7 páginasIntervalo de Confianza para La VarianzaAdriana RguezAún no hay calificaciones
- 3.1.2. Antecedentes Del ProblemaDocumento1 página3.1.2. Antecedentes Del ProblemaAdriana RguezAún no hay calificaciones
- Sociedades CooperativasDocumento4 páginasSociedades CooperativasAdriana RguezAún no hay calificaciones
- Examen Parcial - Semana 4 - Diaz LucianoDocumento9 páginasExamen Parcial - Semana 4 - Diaz LucianoDaniela GuerreroAún no hay calificaciones
- Examen U. 2Documento8 páginasExamen U. 2TheDarknessAún no hay calificaciones
- Muestreo Del Trabajo MEJORADODocumento23 páginasMuestreo Del Trabajo MEJORADOOlson Archila Gomez100% (4)
- (Wackerly, Mendenhall, Scheaffer) Estadistica Matematica Con Aplicaciones pp182-183Documento2 páginas(Wackerly, Mendenhall, Scheaffer) Estadistica Matematica Con Aplicaciones pp182-183Room RootAún no hay calificaciones
- Como Interpretar Las DepDocumento6 páginasComo Interpretar Las DepDaniela Del PuertoAún no hay calificaciones
- CAPITULO11-ae - METODOS DE OBTENCION DE ESTIMADORES PDFDocumento24 páginasCAPITULO11-ae - METODOS DE OBTENCION DE ESTIMADORES PDFLuis Miguel VivancoAún no hay calificaciones
- Actividad 11 InformeDocumento7 páginasActividad 11 InformealejandraAún no hay calificaciones
- Inferencia PDFDocumento65 páginasInferencia PDFJorge RomeroAún no hay calificaciones
- Estadistica Inferencial Soluciones Selectividad PDFDocumento77 páginasEstadistica Inferencial Soluciones Selectividad PDFSteven NovoaAún no hay calificaciones
- Muest ReoDocumento32 páginasMuest ReoTomasHamAún no hay calificaciones
- Clase 23 de MarzoDocumento12 páginasClase 23 de MarzoMaico VargasAún no hay calificaciones
- Muestreo e Intervalos de ConfianzaDocumento64 páginasMuestreo e Intervalos de ConfianzaRoberto JulcaAún no hay calificaciones
- Distribucion T de StudentDocumento5 páginasDistribucion T de StudentJuly Sofia Rojas100% (1)
- Presentacion 4Documento15 páginasPresentacion 4Efn FletesAún no hay calificaciones
- Ejercicios Distribuciones de Probabilidad - SoluciónDocumento10 páginasEjercicios Distribuciones de Probabilidad - SoluciónLuis Valenzuela Herrera100% (3)
- Foro 11 - Semana 11Documento4 páginasForo 11 - Semana 11Brayan AtiroAún no hay calificaciones
- Distribución NormalDocumento6 páginasDistribución NormalMaricel Anahi Carbajal SantacruzAún no hay calificaciones
- Informe Analisis PredictivoDocumento10 páginasInforme Analisis PredictivoDayana RiveraAún no hay calificaciones
- Solucion Estadistica II - Richard WikiDocumento4 páginasSolucion Estadistica II - Richard WikiRichialfoAún no hay calificaciones
- Análisis Químico Conceptos BasicosDocumento7 páginasAnálisis Químico Conceptos BasicosErick ArcadiaAún no hay calificaciones
- Método de Diseño de La AASHTODocumento20 páginasMétodo de Diseño de La AASHTORamirez Pcivil100% (1)
- 07 - Inferencia EstadisticaDocumento32 páginas07 - Inferencia EstadisticaJorge Marcelo Barrientos VásquezAún no hay calificaciones
- Distribución NormalDocumento17 páginasDistribución NormalSofia N Pacheco SalazarAún no hay calificaciones
- Generacion de Variables AleatoriasDocumento21 páginasGeneracion de Variables AleatoriasErick ZamudioAún no hay calificaciones
- Se ApruebaDocumento191 páginasSe ApruebaSofíaAún no hay calificaciones
- Trabajo Final de ProbabiliadadDocumento12 páginasTrabajo Final de ProbabiliadadFercho RiosAún no hay calificaciones
- Práctica BioestadísticaDocumento47 páginasPráctica BioestadísticaMICHELL YULISSA ROMO CARDENASAún no hay calificaciones
- Actividad 4Documento7 páginasActividad 4Teddy AlarcónAún no hay calificaciones
- Guía Distribución Normal 2Documento2 páginasGuía Distribución Normal 2Esteban ZapataAún no hay calificaciones
- Estadistica Basica 2010 PDFDocumento164 páginasEstadistica Basica 2010 PDFjuan perez100% (1)