Documentos de Académico
Documentos de Profesional
Documentos de Cultura
Análisis de Datos 1
Cargado por
avelitoDescripción original:
Derechos de autor
Formatos disponibles
Compartir este documento
Compartir o incrustar documentos
¿Le pareció útil este documento?
¿Este contenido es inapropiado?
Denunciar este documentoCopyright:
Formatos disponibles
Análisis de Datos 1
Cargado por
avelitoCopyright:
Formatos disponibles
INTRODUCCIN La estadstica es la disciplina que nos proporciona una metodologa para recoger, organizar, resumir, analizar datos y hacer
inferencias a partir de ellas. Puede deducirse de la definicin que hay dos ramas claramente diferenciadas dentro de la estadstica: La Estadstica Descriptiva y La Inferencia Estadstica que es el punto a tratar en el presente trabajo. La inferencia Estadstica tiene como funcin inferir las caractersticas de un colectivo a partir de un subconjunto de ste. Referente al contraste de hiptesis, sabemos que un problema es investigable cuando existen dos o ms soluciones alternativas y tenemos dudas acerca de cual de ellas es la mejor. Esta situacin permite formular una o ms hiptesis de trabajo, ya que cada una de ellas destaca la conveniencia de una de las soluciones sobre las dems. Si nuestro propsito es comprobar una teora ella misma ser la hiptesis del trabajo, pero es importante destacar que al formular dicha o dichas hiptesis no significa que ya est resuelto el problema, al contrario, que nuestra duda nos impulsa a comprobar la verdad o falsedad de cada una de ellas. La decisin final partir de las decisiones previas de aceptar o rechazar las hiptesis de trabajo. CAPITULO I Contraste de Hiptesis Etapas Bsicas en Pruebas de Hiptesis. Al realizar pruebas de hiptesis, se parte de un valor supuesto (hipottico) en parmetro poblacional. Despus de recolectar una muestra aleatoria, se compara la estadstica muestral, as como la media (x), con el parmetro hipottico, se compara con una supuesta media poblacional (). Despus se acepta o se rechaza el valor hipottico, segn proceda. Se rechaza el valor hipottico slo si el resultado muestral resulta muy poco probable cuando la hiptesis es cierta. Etapa 1. Planear la hiptesis nula y la hiptesis alternativa. La hiptesis nula (H0) es el valor hipottico del parmetro que se compra con el resultado muestral resulta muy poco probable cuando la hiptesis es cierta. Etapa 2. Especificar el nivel de significancia que se va a utilizar. El nivel de significancia del 5%, entonces se rechaza la hiptesis nula solamente si el resultado muestral es tan diferente del valor hipottico que una diferencia de esa magnitud o mayor, pudiera ocurrir aleatoriamente con una probabilidad de 1.05 o menos. Etapa 3. Elegir la estadstica de prueba. La estadstica de prueba puede ser la estadstica muestral (el estimador no segado del parmetro que se prueba) o una versin transformada de esa estadstica muestral. Por ejemplo, para probar el valor hipottico de una media poblacional, se toma la media de una muestra aleatoria de esa distribucin normal, entonces es comn que se transforme la media en un valor z el cual, a su vez, sirve como estadstica de prueba. Tabla 10.1. Consecuencias de las Decisiones en Pruebas de Hiptesis. Situaciones Posibles Decisiones Posibles La hiptesis nula es verdadera La hiptesis nula es falsa 1
Aceptar la Hiptesis Nula Se acepta correctamente Rechazar la Hiptesis Error tipo I Nula
Error tipo II Se rechaza correctamente
Etapa 4. Establecer el valor o valores crticos de la estadstica de prueba. Habiendo especificado la hiptesis nula, el nivel de significancia y la estadstica de prueba que se van a utilizar, se produce a establecer el o los valores crticos de estadstica de prueba. Puede haber uno o ms de esos valores, dependiendo de si se va a realizar una prueba de uno o dos extremos. Etapa 5. Determinar el valor real de la estadstica de prueba. Por ejemplo, al probar un valor hipottico de la media poblacional, se toma una muestra aleatoria y se determina el valor de la media muestral. Si el valor crtico que se establece es un valor de z, entonces se transforma la media muestral en un valor de z. Etapa 6. Tomar la decisin. Se compara el valor observado de la estadstica muestral con el valor (o valores) crticos de la estadstica de prueba. Despus se acepta o se rechaza la hiptesis nula. Si se rechaza sta, se acepta la alternativa; a su vez, esta decisin tendr efecto sobre otras decisiones de los administradores operativos, como por ejemplo, mantener o no un estndar de desempeo o cul de dos estrategias de mercadotecnia utilizar. Conceptos Bsicos para el Procedimiento de Pruebas de Hiptesis. Hiptesis Estadstica: Al intentar alcanzar una decisin, es til hacer hiptesis (o conjeturas) sobre la poblacin aplicada. Tales hiptesis, que pueden ser o no ciertas, se llaman hiptesis estadsticas. Son, en general, enunciados acerca de las distribuciones de probabilidad de las poblaciones. Hiptesis Nula: En muchos casos formulamos una hiptesis estadstica con el nico propsito de rechazarla o invalidarla. As, si queremos decidir si una moneda est trucada, formulamos la hiptesis de que la moneda es buena ( o sea p = 0,5, donde p es la probabilidad de cara). Analgicamente, si deseamos decidir si un procedimiento es mejor que otro, formulamos la hiptesis de que no hay diferencia entre ellos (o sea. Que cualquier diferencia observada se debe simplemente a fluctuaciones en el muestreo de la misma poblacin). Tales hiptesis se suelen llamar hiptesis nula y se denotan por Ho. Hiptesis Alternativa. Toda hiptesis que difiere de una dada se llamar una hiptesis alternativa. Por ejemplo: Si una hiptesis es p = 0,5, hiptesis alternativa podran ser p = 0,7, p " 0,5 p > 0,5. Una hiptesis alternativa a la hiptesis nula se denotar por H1. Errores de tipo I y de tipo II. Si rechazamos una hiptesis cuando debiera ser aceptada, diremos que se ha cometido un error de tipo I. Por otra parte, si aceptamos una hiptesis que debiera ser rechazada, diremos que se cometi un error de tipo II. 2
En ambos casos, se ha producido un juicio errneo. Para que las reglas de decisin (o no contraste de hiptesis) sean buenas, deben disearse de modo que minimicen los errores de la decisin; y no es una cuestin sencilla, porque para cualquier tamao de la muestra, un intento de disminuir un tipo de error suele ir acompaado de un crecimiento del otro tipo. En la practica, un tipo de error puede ser ms grave que el otro, y debe alcanzarse un compromiso que disminuya el error ms grave. La nica forma de disminuir ambos a la vez es aumentar el tamao de la muestra que no siempre es posible. Niveles de Significacin. Al contrastar una cierta hiptesis, la mxima probabilidad con la que estamos dispuesto a correr el riesgo de cometern error de tipo I, se llama nivel de significacin. Esta probabilidad, denota a menudo por se, suele especificar antes de tomar la muestra, de manera que los resultados obtenidos no influyan en nuestra eleccin. En la practica, es frecuente un nivel de significacin de 0,05 0,01, si bien se une otros valores. Si por ejemplo se escoge el nivel de significacin 0,05 ( 5%) al disear una regla de decisin, entonces hay unas cinco (05) oportunidades entre 100 de rechazar la hiptesis cuando debiera haberse aceptado; Es decir, tenemos un 95% de confianza de que hemos adoptado la decisin correcta. En tal caso decimos que la hiptesis ha sido rechazada al nivel de significacin 0,05, lo cual quiere decir que tal hiptesis tiene una probabilidad 0,05 de ser falsa. Prueba de Uno y Dos Extremos. Cuando estudiamos ambos valores estadsticos es decir, ambos lados de la media lo llamamos prueba de uno y dos extremos o contraste de una y dos colas. Con frecuencia no obstante, estaremos interesados tan slo en valores extremos a un lado de la media (o sea, en uno de los extremos de la distribucin), tal como sucede cuando se contrasta la hiptesis de que un proceso es mejor que otro (lo cual no es lo mismo que contrastar si un proceso es mejor o peor que el otro) tales contrastes se llaman unilaterales, o de un extremo. En tales situaciones, la regin critica es una regin situada a un lado de la distribucin, con rea igual al nivel de significacin. La siguiente tabla de valores crticos de z para contraste de unos o dos extremos en varios niveles de significacin. Nivel de significacin 0.10 0.05 Valores crticos de z para 1.28 o 1.28 1.645 o 1.645 Test Unilaterales Valores Crticos de z 1.645 y 1.645 1.96 y 1.96 para Test Bilaterales Curva Caracterstica Operativa y Curva de Potencia. Hemos visto como limitar el error de tipo I eligiendo adecuadamente el nivel de significacin. Es posible evitar el riesgo de cometer error de tipo II simplemente no aceptado nunca hiptesis, pero en muchas aplicaciones prcticas esto es inviable. 0.01 2.33 o 2.33 2.58 y 2.58 0.005 2.58 o 2.58 2.81 y 2.81 0.02 2.88 o 2.88 3.08 y 3.08
En tales casos se suele recurrir a curvas de operacin caractersticas o curvas de OC, que son grficos que muestran las probabilidades de error de tipo II bajo diversas hiptesis. Proporcionan indicadores de hasta que punto un test dado nos permitir evitar un error de tipo II; es decir, nos indicar la potencia de un test a la hora de prevenir decisiones errneas. Son tiles en el diseo de experimentos porque sugieren entre otras cosas al tamao de muestra a manejar. Grados de Libertad. Para el clculo de un estadstico, es necesario emplear tanto observaciones de muestra como propiedades de ciertos parmetros de la poblacin. Si estos parmetros son desconocidos, hay que estimarlos a partir de la muestra el nmero de grados de libertad de un estadstico, generalmente denotado por v se define como el nmero N de observaciones independientes en la muestra (o sea, el tamao de la muestra) menos el nmero K de parmetros de la poblacin, que debe ser estimado a partir de observaciones mustrales. En smbolos, v = N k. Capitulo II Contraste de hiptesis referentes a la diferencia entre: Una media muestra y una media poblacin; utilizando la distribucin (z) El uso de la distribucin normal z se busca en las mismas condiciones que en el caso de una muestra excepto que ahora se tienen dos muestras independientes. La formula general para determinar el valor de z para probar la diferencia entre dos medidas, dependiendo de s se conocen los valores para las dos poblaciones, es:
Donde puede procederse a probar cualquier diferencia supuesta ( )0. Sin embargo la hiptesis nula que generalmente se prueba consiste en que las dos muestras se obtienen de poblaciones con medias iguales. En este caso ( )0 = 0, y las formulas anteriores se vuelven ms simples: Una media Muestral y una Media Poblacional. Una distribucin poblacional representa la distribucin de valores de una poblacin y una distribucin muestral representa la distribucin de los valores de una muestra. En contraste con las distribuciones de mediciones individuales, una distribucin muestral es una distribucin de probabilidad que se aplica a los valores posibles de una estadstica muestral. As, la distribucin muestral de la media es la distribucin de probabilidad de los valores posibles de la media muestral con base en un determinado tamao de muestra. Para cualquier tamao de muestra dado n, tomado de una poblacin con media , los valores de la media muestral varan de una muestra a otra. Esta variabilidad sirve de base para la distribucin muestral. La distribucin muestral de la media se describe determinando el valor esperado E () o media, de la distribucin y la desviacin estndar de la distribucin de las medias, . Como esta desviacin estndar indica la precisin de la media muestral como estimador puntual, por lo general se le denomina error estndar de la media. En general, se define el valor esperado de la media y el error estndar de la media de la siguiente manera: E
Ejemplo: Suponga que la media de una poblacin muy grande es = 50.0 y que la desviacin estndar es = 12.0. Se determina la poblacin muestral de las medias para una muestra de tamao n = 36, en trminos del valor esperado y del error estndar de la distribucin de la siguiente manera. E Cuando se muestra a partir de una poblacin finita, se debe incluir un factor de correccin por poblacin finita en la frmula para el error estndar de la media. Como regla general, la correccin es despreciable y puede omitirse cuando n < 0.05 N, es decir, cuando el tamao de la muestra es menos del 5% del tamao de la poblacin. Muchos textos y programas de computacin no incluyen esta correccin porque suponen que la poblacin siempre es muy grande, o quiz de tamao infinito. La frmula para el error estndar de le media, incluyendo el factor de correccin por la poblacin finita, es: Si no se conoce la desviacin estndar de la poblacin, puede estimarse el error estndar de la media utilizando la desviacin estndar muestral como estimador de la desviacin estndar de la poblacin. Para diferenciar este error estndar del que se basa en una o conocida, se le designa mediante el smbolo S (o mediante en algunos textos). La frmula del error estndar estimado de la media es: La frmula del error estndar estimado de la media, incluyendo el factor de correccin por poblacin finita es: Proposiciones Utilizando la definicin Chi Cuadrado (X2). Una media de la discrepancia existente entre las frecuentes observadas y esperadas viene proporcionada por el estadstico X2 dado por: Donde si la frecuencia total es N, Una expresin equivalente a la formula (1) : Si X2 = 0 Las frecuencias observadas y tericas coinciden completamente, mientras que si X2 > 0, no coinciden exactamente a valores ms grandes de X2, mayor discrepancia entre las frecuencias observadas y esperadas. La distribucin muestral de X2 se aproxima muy bien por la distribucin Chi Cuadrada. Distribucin Chi Cuadrado para la Bondad de Ajustes: El Test Chi Cuadrado puede utilizarse para determinar la calidad del ajuste mediante distribuciones tericas (como la distribucin normal o la binomial) de distribucin empricas (o sea las obtenidas de los datos de la muestra). Distribucin Chi Cuadrado y Tablas de Contingencia. Suceso Frecuencia Observada Frecuencia Esperada E1 01 e1 E2 02 e2 E3 03 e3 ... ... ... Ek 0k ek
En esta tabla las frecuencias observadas ocupan una sola fila y la llamamos tabla de calcificacin de entrada nica como el nmero de columnas es K tambin se llama una tablas 1 x K (Leido 1<<1 por k>>).
Extendiendo estas ideas, podemos llegar a tablas de doble entrada tablas h x k, en las que las frecuencias observadas ocupan h filas y k columnas tales tablas se suelen llamar tablas de contingencia. Correspondiendo a cada frecuencia observada en una tabla de contingencia h x k, hay una frecuencia esperada o terica que se calcula sujeta a ciertas hiptesis de acuerdo con las leyes de las probabilidades. Estas frecuencias que ocupan las celdas de una tabla de contingencia, se llaman frecuencias de celdas. La frecuencia total de cada fila o en cada columna se llama frecuencia marginal. Para investigar el acuerdo entre las frecuencias observadas y las frecuencias esperadas, calculamos el estadstico. Donde la suma de toma sobre todas las celdas de una tabla de contingencia y donde los smbolos Oj y ej representan respectivamente las frecuencias observadas y esperada de la j sima celda. La suma de todas las frecuencias observadas se denota por N y es igual a la suma de todas las frecuencias observadas se denota por N y es igual a la suma de todas las frecuencias esperadas. Como antes el estadstico (5) tiene una distincin muestral dada muy aproximadamente por (4), supuesto que las frecuencias esperadas no sean demasiado pequeas. El nmero de grado de libertad, v de esta distribucin chi cuadrado viene dado por h > 1 y k >1 por: 1. v = (h 1) (k 1) si las frecuencias esperadas se pueden calcular sin recurrir a estimaciones mustrales de los parmetros de la poblacin. 2. v = (h 1) (k 1) m. Si las frecuencias esperadas solo se pueden calcular mediante estimacin de m parmetros de la poblacin a partir de estadsticas de la muestra. Los contrastes de significacin para las tablas h x k son similares a los de las tablas 1 x k. Las frecuencias esperadas se hallan sujetas a una hiptesis particular h0. Las tablas de contingencia se pueden generalizar a ms dimensiones. As, por ejemplo, podemos tener tablas h x k x 1, donde estn presentes tres clasificaciones. Muestras. Es un subconjunto de la poblacin que contiene las mediciones obtenidas mediante un experimento. Dos varianzas Utilizando la razn de varianzas (f de fisher). Como hemos visto es importante conocer la distribucin de muestreo de la diferencia en medias de dos muestras. De la misma manera, podemos necesitar la distribucin de muestreo de la diferencia en varianzas (s21 s22). Resulta sin embargo, que esta distribucin es complicada, por lo que en lugar de eso, consideramos el estadstico s21 / s22, ya que en un cociente grande o pequeo indicar una gran diferencia, mientras un cociente cercano a 1 indica una pequea diferencia. Su distribucin de muestra se llama distribucin f, en honor a R. A. Fisher. Mas correctamente, sean dos muestras 1 y 2 de tamaos N1 Y N2, respectivamente, tomadas de dos poblaciones normales (o casi) con varianzas y , Definamos el estadstico. Donde Entonces la distribucin de muestreo de F se llama distribucin de F de Fisher o en breve, distribucin F, 6
con v1 = N1 1 y v2 = N2 1 grados de libertad. Esta distribucin viene dada por: Donde C es una constante que depende de v1 y v2 tal que el rea total bajo la curva es 1. La forma de esta curva puede variar considerablemente segn los valores de v1 y v2. Puede probarse que la distribucin F es el modelo de probabilidad por el cociente de las varianzas de muestras tomadas en forma independiente de la misma poblacin con distribucin normal y que existe una distribucin F diferente para cada combinacin de grados de libertad (g1) correspondiente al numero de muestra. Para todas las muestras, g1 = n 1 por ello, la estadstica que se utiliza para probar la hiptesis nula con respecto a la diferencia entre dos varianzas es: F= Aun cuando esta hiptesis nula sea cierta, no es probable que las varianzas muestras de cualquier par de muestras sean idnticas. Para datos Apareados y no Apareados. . Distribucin T Student. Definamos el estadstico: Que es anlogo al estadstico Z dado por: Si consideramos muestras de tamao N tomadas de una poblacin normal (o casi normal) con media y si para cada una calculamos t, usando la media muestral x y la desviacin tpica muestral S ^s, puede obtenerse la distribucin de muestreo para t. Esta distribucin viene dada por: Donde yo es una constante que depende de N tal que al rea total bajo la curva es 1, y donde la constante V = (n 1) se llama el nmero de grados de libertad (v es la letra griega nu). La distribucin (2) se llama distribucin t de Student en honor de su descubridor, W.S Gosset; para grandes valores de v o de N (ciertamente N " 30), las curvas (2) se ajustan mucho a las curva normal cannica. Muestras Grandes y Muestras Pequeas. Para muestras de tamao N > 30, llamadas grandes muestras, las distribuciones de muestreo de muchos estadsticos son aproximadamente normales, siendo la aproximacin tanto mejor cuanto mayor sea N. Para muestra de tamao menor que 30, llamadas pequeas muestras, esa aproximacin no es buena y empeora al decrecer N, de modo que son precisas ciertas modificaciones. El estudio de la distribucin de muestreo de estadsticos para pequeas muestras se llama teora de pequeas muestras, sin embargo un nombre ms apropiado seria teora exacta del muestreo, pues sus resultados son validos tanto para pequeas muestras como para grandes. Para datos Apareados y no Apareados. En muchas situaciones las muestras se extraen como pares de valores, tal como cuando se determina el nivel 7
de productividad de los trabajadores, antes y despus de un programa de capacitacin. A esta clase de datos se les denomina observaciones apareadas a pares asociados. Tambin a diferencia de las muestras independientes a dos muestras que contienen observaciones apareadas se les denomina dependientes. El mtodo apropiado para probar la diferencia entre observaciones apareadas consiste en determinar la diferencia d entre cada par de valores y despus probar la hiptesis nula de que la diferencia poblacional promedio es 0. por ello desde el punto de vista de los clculos, se aplica una prueba a una muestra de valores d. La diferencia promedio para el conjunto de observaciones apareadas es: La frmula de desviacin y la abreviada para la distribucin estndar y las diferencias entre datos apareados son: El error estndar del promedio de las diferencias entre datos apareados se obtiene mediante la frmula del error estndar de la media, excepto que se sustituye el por x: Como el error estndar del promedio de las diferencias se calcula con base a datos apareados y como por lo general, se supone que los valores d tienen una distribucin normal, la distribucin t resulta apropiada para probar la hiptesis nula de que d = 0. Una proporcin Muestral y una Poblacional: Muestras Grandes Distribucin Normal (z). Puede utilizarse la distribucin normal como aproximacin de la binomial cuando n " 30 y, tanto np " 5 como n (q) " 5, donde q = 1 p. Sin embargo en el caso de intervalos de confianza se requiere un tamao de muestra n =100. En pruebas de hiptesis, el valor del error estndar de la poblacin que se utiliza se basa en el valor hipottico . La formula del error estndar de la proporcin que incluye el factor de correccin por poblacin finita es: La formula para la distribucin normal z sera: Para determinar el tamao de la muestra que se requiere para probar el valor de una proporcin (antes de extraerla) especificando el valor hipottico de la proporcin, un valor alternativo especifico de la proporcin, de manera que la diferencia con respecto al valor hipottico nulo resulte considerable; el nivel de significacin que debe utilizar en la prueba, y la probabilidad del error tipo II que se permite. La frmula que determinar el tamao mnimo de las muestras que se requieren para probar dicho valor de la proporcin es: Donde z0 es el valor critico de z que se utiliza con el nivel especificado de significanca (nivel ) en tanto que z1. Es el valor que corresponde a la probabilidad designada del error tipo II (nivel ). Cuando se determina el tamao de la muestra para probar la media, z0 y z1 siempre tienen signos algebraicos opuestos. 8
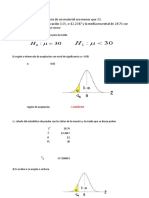
Ejercicios de Aplicacin: Para una Media Muestral y una Poblacional: La vida til promedio de una muestra aleatoria de n1 = 10 focos es x1 = 4.600 horas con s1 = 250 horas para otra marca de focos, la vida til promedio y la desviacin estndar para una muestra de n2 = 8 focos son x2 = 4.000 horas y s2 = 200 horas. Se asume que la vida til de los focos de ambas marcas tiene una distribucin normal. El intervalo de confianza de 90% para estimar la diferencia entre las vidas tiles de las dos marcas de focos es: Utilizando la Distribucin Z: El salario promedio mensual para una muestra de n1 = 30 empleados de una empresa manufacturera grande es x1 = $ 280,000, con desviacin estndar muestral de s1 = $ 14,000 en otra Empresa grande, una muestra aleatoria de n2 = 40 empleados, tiene un salario promedio de x2 = $ 270,000 con la desviacin estndar muestral de s2 = $ 10.000 no se supone que las desviaciones estndar de las dos poblaciones sean iguales. Se prueba la hiptesis de que no existe diferencia entre los salarios promedio mensuales de las dos empresas, utilizando un nivel de significacin de 5% de la siguiente manera: Errores Tipo I y Tipo II. Ejemplo 1. La hiptesis nula que se va a probar es que la media de todas las cuentas por cobrar es cuando menos $260.000, y esta prueba se llevar a cabo con un nivel de significancia del 5%. Adems, el auditor seala que considerara que una media real de $240.000 (o menos) constituye una diferencia material importante. Con respecto al valor hipottico de la media. Al igual que antes, = $43.000, y el tamao de la muestra es n = 36 cuentas. Para determinar la probabilidad del error tipo II, se requiere: 1. Plantear las hiptesis nula y alternativa para esta prueba. 2. Determinar el valor critico de la media muestral que debe utilizarse para probar la hiptesis nula con un nivel de significancia del 5%, 3. Identificar la probabilidad del error tipo I; correspondiente al valor crtico que se calculo antes, como base para la regla de decisin. 4. Identificar la probabilidad del error tipo II correspondiente a la regla de decisin, dada una media alternativa especifica de $240.000. La solucin completa es: 1. 2. 3. La probabilidad del error tipo I es igual a 0.05 (el nivel de significancia que se utiliza para probar la hiptesis nula). 4. la probabilidad del error tipo II es la probabilidad de que la media de la muestra aleatoria sea igual o superior a $248,210, dado que la media de todas las cuentas es en realidad $240.000.
En la figura 10 4 se ilustra el mtodo que se sigui en el ejemplo 5. En general, el valor crtico de la media que se determina con respecto a la hiptesis nula se reduce y se utiliza como valor critico con respecto a la hiptesis alternativa especifica. En el problema 10.13 se ilustra la forma de determinar la probabilidad del error tipo II para una prueba de dos extremos. Ejemplo 2. Puede verificarse la probabilidad del error tipo II que se determin en el ejemplo 5, haciendo referencia a la figura 10 5, de la siguiente manera: Tal como se determin en el ejemplo 5, = $ 260.000, = $240.00 y x = 7166,67. Por lo tanto, la diferencia entre los dos valores designados de la media en unidades del error estndar es Con referencia a la figura 10 5, la altura de la curva en el valor de 2.8 x sobre el eje horizontal est justamente sobre el 0.10, tal como se muestra en las lneas punteadas. El valor real calculado en el ejemplo 5 en 0.13. Al realizar pruebas de hiptesis, el concepto de potencia se refiere a la probabilidad de rechazar una hiptesis nula dado un valor alternativo especifico para el parmetro (en los ejemplos que se han revisado, es la media de la poblacin). Cuando se designa mediante la probabilidad del error tipo II, se sigue que la potencia de una prueba es 1 . Con referencia a la figura 10 5, puede observarse que la potencia para valores alternativos de la media es la diferencia entre el valor sealado por la curva C0 y 1.0 y , por ello, puede obtenerse una curva de potencia mediante Substraccin utilizando la curva C0. Ejemplo 3. Puede determinarse la potencia de la prueba con el valor alternativo especifico de la media de $ 240.000, de la siguiente manera: Como = p (error tipo II) = 0.13 (del ejemplo 5), Potencia = 1 = 1.00 013 = 0.87 (Nota: Esta es la probabilidad de rechazar la hiptesis, en la forma correcta, cuando = $ 240.000). Ejemplo 4. Un auditor desea probar la hiptesis nula de que el valor promedio de todas las cuentas por cobrar es de cuando menos $260.000. Considera que la diferencia entre este valor hipottico y un valor especifico alternativo de $ 240.000 (o menos) sera considerable. Los niveles aceptables de los errores tipo I () tipo II () son 0.05 y 0.10, respectivamente. se sabe que la desviacin estndar de los montos de las cuentas por cobrar es de = $43.000. El tamao de la muestra que debe extraerse, como mnimo, para llevar a cabo esta prueba es (Nota: Como z0 y z1 siempre tienen signos algebraicos contrarios, se tiene los dos valores zeta siempre se acumulan en el numerador. Si el valor acumulado es negativo, el proceso de elevar al cuadrado da como resultado valores positivos). Ejemplo 5. Suponga que el auditor del ejemplo anterior esta preocupado por una discrepancia en cualquier direccin con respecto al valor nulo hipottico de $26.000 en cualquier direccin sera importante. Considerando la otra informacin y las especificaciones del ejemplo 8, el tamao mnimo de la muestra que debe analizarse es. (Nota como las desviaciones con respecto a valor hipottico slo pueden darse en una direccin, se utilizan el valor de +1.96 o 1.96 como valor de z0, con el correspondiente valor de z1. Al igual que en el ejemplo 8, los dos valores de z se acumulan siempre antes de elevarlos al cuadrado.) Distribucin Student: 10
Prueba De un valor Hipottico de la media utilizando la distribucin de Student Se ha planteado la hiptesis nula de que la vida til promedio de los focos de una marca especifica es cuando menos de 4.200 horas. La vida til promedio para una vida aleatoria de n = 10 focos es x = 4000 horas, con desviacin estndar muestral de s = 200 horas. En trminos generales, se supone que la vida til de los focos tiene una distribucin normal. Se prueba la hiptesis nula con un nivel de significancia del 5%, de la siguiente manera: Como 3.16 se encuentra en la regin de rechazo del extremo izquierdo (a la izquierda del valor crtico 1.833), la hiptesis nula se rechaza y se acepta la alternativa de que la vida til promedio es inferior a 4.200 horas. Una Proporcin de la Poblacin Utilizando La Distribucin Normal ( Z ) Ejemplo 6. El director de la bolsa de trabajo afirmaba que cuando menos, el 50% de los egresados habra obtenido empleo hacia el primero de Marzo. Suponga que se entrevista a una muestra de n = 30 egresados, en vez de los 10 del ejemplo 5, y que slo 10 de ellos sealan haber obtenido empleo hacia el primero de Marzo. puede rechazarse la afirmacin del director con un nivel de significancia del 5%?. Se utiliza z como estadstica de prueba, de la siguiente manera: Estadstica Aplicada. Se justifica el uso de la distribucin normal porque Se supone que la muestra es menos del 5% del tamao de la poblacin, y por ello no se utiliza el factor de correccin por poblacin finita.) El valor calculado de z de 1.88 es menor que el valor crtico de 1.645 para esta prueba del extremo inferior por eso se rechaza la afirmacin del director en un nivel de significancia del 5%. Proporcin Muestral. Ejemplo 7. Un legislador desea probar la hiptesis de que, cuando menos, 60% de sus representados estn a cierta legislacin laboral que se est presentado en el congreso, utilizando el 5% como nivel de significancia con que una discrepancia importante con respecto a su hiptesis consistira en que slo el 50% (o menos) de las personas estuvieran a favor de la legislacin, y esta dispuesto a aceptar un riesgo del error del tipo II de = 0.05. El tamao de la muestra que debe extraer, como mnimo, para satisfacer esas especificaciones es: Ejemplo 8. Una muestra de 50 hogares de cierta comunidad arroja que solo 10 de ellos se encuentran viendo un programa especial de televisin. En una segunda comunidad, 15 hogares de una muestra aleatoria de 50 se encuentran observando el programa especial. Se prueba la hiptesis de que la proporcin global de televidentes en las dos comunidades no difieren, utilizando el nivel de significancia del 1%, de la siguiente manera: Pruebas Para La Diferencia Entre Dos Medias Utilizando La Distribucin Normal. Un constructor est considerando dos lugares alternativos para un centro comercial regional. Como los ingresos de los hogares de la comunidad son una consideracin importante en esa seleccin, desea probar la hiptesis nula de que no existe diferencia entre el ingreso promedio por hogar en las dos comunidades. Consistente con esta hiptesis supone que la desviacin estndar del ingreso por hogar es tambin igual en las dos comunidades. Para una muestra de n = 30 hogares de la primera comunidad, encuentra que el 11
ingreso diario promedio es x = $35.500, con desviacin estndar muestral de s1 = $1.800. Para una muestra de n2 = 40 hogares de la segunda comunidad, x2 = $34.600 s2 = $2.400. Probar la hiptesis nula en el nivel de significancia del 5%. (Se combina las varianzas debido a la suposicin de que los valores de las desviaciones estndar de las poblaciones son iguales). Otras Pruebas De Hiptesis. El valor calculado de z de +1.72 se encuentra en la regin de aceptacin de la hiptesis nula. Por ello, no es posible rechazar la hiptesis nula al nivel de significancia del 5%, y se acepta la hiptesis de que el ingreso promedio por hogar de las dos comunidades no es diferente. Con referencia al problema 11.1, antes de recolectar los datos, el constructor considero que el ingreso de la primera comunidad pudiera ser superior. Con el objeto de someter esta evaluacin a una prueba critica, le otorgo el beneficio de la duda a la otra posibilidad y planteo la hiptesis nula H0 : ( )" 0. Prueba esta hiptesis con un nivel de significancia del 5%, con la suposicin adicional de que los valores de la desviacin estndar para las dos poblaciones no son necesariamente iguales. El valor calculado z de +1.79 es mayor que el valor critico de +1.645 para esta prueba del extremo superior. Por ello, se rechaza la hiptesis nula a un nivel de significancia del 5%, y se acepta la hiptesis alternativa de que el ingreso promedio por hogar es mayor en la primera comunidad que en la segunda. Con respecto a los problemas 11.1 y 11.2, antes de recolectar los datos, el constructor considero que el ingreso promedio de la primera comunidad excede al promedio de la segunda comunidad en cuando menos $1.500 diarios. En este caso, concediendo a esta evaluacin el beneficio de la duda, pruebe esa suposicin como hiptesis nula utilizando un nivel de significancia del 5%. No se supone que las desviaciones estndar de las poblaciones son iguales. La prueba de ji cuadrada como Procedimiento para Prueba de Hiptesis Los procedimientos que se describen en este capitulo, implican la comparacin de frecuencias mustrales clasificadas en categoras definidas de datos, teniendo en todos los casos el patrn esperado de frecuencia que se basan en una hiptesis nula especifica. Por ello, los procedimientos son todos de prueba de hiptesis y en los anlisis se utilizan datos de muestras aleatorias. La distribucin de probabilidad x2 (jicuadrada) se describe en las secciones 9.6 y 11.8. La estadstica de prueba que se presenta en la seccin siguiente se distribuye como el modelo de probabilidad de jicuadrada y, como se trata de pruebas de hiptesis, se aplican tambin en este capitulo las etapas bsicas que se describieron en la seccin 10.1. En este capitulo se cubre el uso de la distribucin jicuadrada para pruebas de bondad del ajuste, pruebas de la independencia de dos variables y pruebas para hiptesis sobre proporciones. Una de las pruebas de proporciones consiste en probar las diferencias entre varias proporciones, lo cual es una extensin de la prueba para la diferencia de dos proporciones que se describi en la seccin 11.7. Pruebas de Bondad del Ajuste La hiptesis nula en una prueba de bondad del ajuste en una afirmacin sobre el patrn esperado de las frecuencias en un conjunto de categoras. El patrn esperado puede ajustarse a su suposicin de igualdad de probabilidades y puede, por ello, ser uniforme. O por otro lado, el patrn esperado puede ajustarse a distribuciones de probabilidad como la binomial, la Poisson y la normal. 12
Ejemplo 1. Un distribuidor regional de sistemas de aire acondicionado a subdividido su regln en cuatro territorios. A un posible comprador de una distribuidora se le dice que las instalaciones de equipo se distribuyen de manera aproximadamente igual en los cuatro territorios. El prospecto de comprador toma una muestra aleatoria de 40 instalaciones colocadas el ao anterior de los archivos de la compaa, y encuentra que el numero de las instalaciones en cada uno de los cuatro territorios son los que se enlistan en el primer regln de la tabla 12.1, (en donde o significa frecuencia observada) con base en la hiptesis de que las instalaciones estn distribuidas en forma equitativa, en el segundo regln de la tabla 12.1 se presenta la distribucin uniforme esperada de las instalaciones (en donde fe significa frecuencia esperada). Tabla 12.1 Nmero de Instalaciones de Sistema de Aire por Territorio Territorio A Nmero Instalado en la Muestra 6 f0 Nmero Esperado de 10 Instalaciones, fe 12 10 B 14 10 C 8 10 Total 40 40 D
Para aceptar la hiptesis nula, debe ser posible atribuir las diferencias entre las frecuencias observadas y la esperada a la variabilidad del muestreo y al nivel especificado de significancia. As la estadstica de prueba jicuadrada se basa en la magnitud de esta diferencia para cada una de las categoras de la distribucin de frecuencia. El valor de jicuadrada que se utiliza para probar la diferencia entre un patrn de frecuencia observado y otro esperado es: Se observa que, si las frecuencias observadas son muy cercanas a las frecuencias esperadas, entonces el valor calculado de la jicuadrada estar cercano a 0. Conforme las frecuencias observadas se alejan de las frecuencias esperadas el valor de jicuadrada se vuelve mayor. Por ello, se concluye que las pruebas de jicuadrada implican el uso de solamente el extremo superior, con el objeto de determinar si un patrn observado de frecuencias es diferente de un patrn esperado. Ejemplo 2. El clculo de la estadstica de prueba jicuadrada para el patrn de frecuencias observadas y esperadas de la tabla 12.1 es: El valor que se requiere de la estadstica de prueba ji cuadrada para rechazar la hiptesis nula depende del nivel de significancia que se especifique y de los grados de libertad. En pruebas de bondad del ajuste, los grados de libertad gl son iguales al nmero de categoras menos el nmero de estimadores de parmetros y menos 1. Los grados de libertad par una prueba e bondad del ajuste con ji . cuadrada son (en donde k = a nmero de categoras de datos y m = nmeros de parmetros estimados con base en la muestra): gl = k m 1 Ejemplo 3. En seguida se presenta un ejemplo completo del procedimiento de prueba de hiptesis para los datos de la tabla 12.1, probando la hiptesis nula a un nivel de significancia del 5% . H0: El nmero de instalaciones estn distribuidas de manera uniforme en los cuatro territorios. H1: El nmero de instalaciones no esta distribuida de manera uniforme en los cuatro territorios. gl = k m 1 = 401 = 3 x2 Crtica (gl = 3, = 0.05) = 7.81 (del apndice 7). 13
x2 Calculada = 4.00 (del ejemplo 2). Cmo el valor calculado de ji cuadrada de 4.00 no es mayor que el valor crtico de 7.81 no puede rechazarse la hiptesis nula de que las instalaciones estn distribuidas de forma equitativas entre los cuatro territorios, a un nivel de significancia del 5%. Pruebas de Bondad de Ajuste Alguien afirma que los clientes de una tienda de pantalones vaqueros son hombres y mujeres, en proporciones iguales. Se observa una muestra aleatoria de 40 clientes y 25 resultan ser hombres y 15 mujeres. Pruebe la hiptesis nula de que el nmero global de hombres y mujeres que son clientes en esa tienda es igual, aplicando la prueba de ji cuadrada, y utilizando el nivel de significancia del 5%. Tabla 12.10. Frecuencias Observadas y Esperadas para el Problema 12.1. Clientes Hombres Nmero en la Muestra (f0) 25 Nmero esperado (fe) 20 De la tabla 12.10 H0: El nmero de clientes hombres y mujeres es igual. H1: El nmero de clientes hombres y mujeres no es igual. gl = k m1 = 201 =1 x2 Crtica (gl = 1, = 0.05) = 3.84 La estadstica de prueba calculada, 2.50 no es mayor que el valor crtico de 3.84. Por lo tanto, no es posible rechazar la hiptesis nula a un nivel de significancia de un 5%. Ejemplo 4. Durante mucho tiempo, un fabricante de aparatos de televisin a tenido 40% de sus ventas en aparatos de pantallas pequeas (de menos de 1 pulgadas), 40% de tamao mediano (de 14 a 19 pulgadas) y el 20% en la categora de pantalla grande (de 21 pulgadas y ms). Para fijar los programas adecuados de produccin para el mes siguiente, se torna una muestra aleatoria de 100 ventas durante el periodo y se encuentra que 55 de los aparatos eran pequeos, 35 medianos y 10 grandes. En seguida, se prueba la hiptesis nula de que el patrn histrico de ventas sigue siendo igual, utilizando el nivel de significancia de 1%. H0 : Los porcentajes de compras de aparatos de televisin de pantalla pequea, mediana y grande son 40%, 40% y 20% respectivamente. H1: el patrn actual de ventas de televisores es diferente del patrn histrico planteado en H0. gl 0 k m 1 = 301 = 2 X2 Crtica (gl = 2, = 0.01) = 9.21 La X2 calculada (en la tabla 12.2 se encuentran las frecuencias observadas y esperadas) es: 14
Mujeres 15 20
Total 40 40
La estadstica ji cuadrada calculada de 11.25 es mayor que el valor crtico de 9.21. Por ello, se rechaza la hiptesis nula a un nivel de significancia de 1%. Comparando la frecuencias observadas y esperadas de la tabla 12.2, se encuentra que el cambio principal consiste en que se venden ms aparatos pequeos y menos grandes, con ciertas reduccin en las ventas de los aparatos de tamao mediano. Tabla 12.2 Compras Observadas y esperadas de aparatos de televisin, de acuerdo con el tamao de la pantalla. Tamao de la Pantalla Pequea Frecuencia Observada, f0 Patrn Histrico, fe 55 40 35 40
Mediana 10 20
Total 100 100
Grande
Tablas de Contingencia. Ejemplo 5. La tabla 12.3 es una reproduccin de la seccin 5.8 y es un ejemplo del formato ms simple posible de una tabla de contingencia, ya que las dos variables (Sexo y Edad) tiene solo dos niveles de clasificacin, o categoras. Por ello, se trata de una tabla de contingencia de 2 x2. Tabla 12.3 Tabla de contingencia para los clientes de la tienda de aparatos de sonidos. Sexo Edad Menor de 30 30 y ms Total 60 80 140 Hombre 50 10 60 Total 110 90 200 Mujer
Si se rechaza la hiptesis nula de independencia para datos clasificados como los de la Tabla 12.3, es seal de que las dos variables son dependientes y que existen una relacin entre ellas. Por ejemplo, para la tabla 12.3, esto indicara que existe una relacin entre la edad y el sexo para los clientes de la tienda de aparatos de sonido. Dada la hiptesis de independencia las dos variables, la frecuencia esperada correspondiente a cada una de las celdas de la tabla de contingencia debe ser proporcional al total de frecuencias observadas de columnas y de regln. Si fr es la frecuencia total de un regln determinado fx es la frecuencia total de una columna determinada, entonces una formula conveniente para determinar la frecuencia esperada para la celda de la tabla de contingencia que se encuentra en ese rengln y columna es: La formula general para los grados de libertad correspondiente a una prueba de independencia es: gl = (r 1) (k 1). Ejemplo 6. En la tabla 12.4 se presentan las frecuencias esperadas para los datos de la tabla 12.3. Por ejemplo para la celda de rengln 1 y columna 1, el calculo de la frecuencia esperada es: En este caso, las tres frecuencias esperadas restantes pueden obtenerse mediante substraccin de los totales de rengln y de columnas, como alternativas al uso de las formulas (12.3). Esta es una indicacin directa de que existe un grado de libertad para una tabla de contingencia de 2x2 y que solo la frecuencia de una celad tiene libertad para variar. 15
Tabla 12.4 Tabla de frecuencia esperadas para las frecuencias observadas que se reportan en la tabla 12.3. Sexo Edad Menor de 30 30 y ms Total 77 63 140 Hombres 33 27 60 Total 110 90 200
Mujer
La estadsticas de pruebas y cuadradas para tablas de contingencia se calcula exactamente de la misma manera que para las pruebas de bondad del ajuste (seccin 12.2). Ejemplo 7. Enseguida se realiza la prueba de la hiptesis nula de independencia para los datos de la tabla 12.3, utilizando un nivel de significancia del 1%. H0: El sexo y la edad de los clientes de la tienda es independiente. H1: El sexo y la edad son variables dependientes (existe una relacin entre las variables sexo y edad). La estadstica de prueba calculada de 27.8 excede el valor crtico de 6.63. Por ello, se rechaza la hiptesis nula de independencia a un nivel de significancia del 1%. Con referencia a la tabla 12.3, se observa que es ms probable que los clientes de sexo masculino tengan ms de 30 aos de edad, al tiempo que es ms probable que las mujeres tengan menos de 30 aos. El resultado de la prueba de ji cuadrada arroja que no puede pensarse que esa relacin observada en la muestra se debe al azar, a un nivel de significancia de 1%. Ejemplo 8. El gerente de un apartamento de personal estima que una proporcin de = 0.40 de los empleados de una empresa grande participara en un nuevo programa de inversin en acciones. Se entrevista a una muestra aleatoria de n = 50 empleados y 10 de ellos manifiestan su intencin de participar. Se podra probar el valor hipottico de la proporcin poblacional utilizando la distribucin normal de probabilidad tal como se describe en la seccin 11.5. En seguida, se ilustra el uso de la prueba de ji cuadrada para lograr ese mismo objetivo utilizando un nivel de significancia de 5%. H0 : = 0.40 H1 " 0.40 gl = k m 1 = 201 = 1 (Existen 2 categoras de frecuencias observadas, tal como se muestra en la tabla 12.5). X2 Crtica (gl = 1 = 0.05) = 3.84 La x2 calculada (en la tabla 12.5 se muestran las frecuencias observadas y las esperadas) es: Tabla 12.5 frecuencia observadas y esperadas para el ejemplo 8. Participacin en los programas Si No 10 40 20 30
Total 50 50
Nmero Observado en la muestra, f0 Nmero esperado en la muestra fe
La estadstica de prueba calculada de 8.33 excede el valor crtico de 3.84. Por ello se rechaza la hiptesis nula a un nivel de significancia de 5% y se concluye que la proporcin de participantes en el programa en 16
toda la empresa no es de 0.40. Ejemplo 9. Suponga que se muestren los hogares de cuatro comunidades y se investiga el nmero en los que se estaba viendo el programa especial de televisin. En la tabla 12.8 se presentan los datos mustrales observados, y en la tabla 12.9 se presentan las frecuencias esperadas, calculadas con la frmula (12.3). Enseguida se realiza la prueba de la hiptesis nula de que no existen diferencias entre las proposiciones poblacionales. H0 : = = = H0 : No todas = = = (Nota: El rechazo de la hiptesis nula no indica que todas las igualdades son falsas si no que cuando menos una es falsa). Tabla 12.8 audiencia del programa de televisin en cuatro comunidades. Comunidades 1 2 Nmero de Televidentes Nmero de no Televidentes Total 10 40 50 15 35 50
3 5 45 50
4 18 32 50
Total 48 152 200
Tabla 12.9 Frecuencias esperadas para los datos de la tabla 12.8. Comunidades 1 2 Nmero de Televidentes Nmero de no Televidentes Total 12.0 38.0 50 12.0 38.0 50
3 12.0 38.0 50
4 12.0 38.0 50
Total 48 152 200
El valor calculado de la estadstica ji cuadrada 10.75,no es mayor que el valor crtico de 11.35.Por ello, las diferencias en las proporciones de televidentes en las cuatro comunidades muestreadas no son lo suficientemente grande par rechazar la hiptesis nula a un nivel de significancia del 5%. Pruebas de Bondad del ajuste. Alguien afirma que los clientes de una tienda de pantalones vaqueros son hombres y mujeres en proporciones iguales. Se observa una muestra aleatoria de 40 clientes y 25 resultan ser hombres y 15 mujeres. Pruebe la hiptesis nula de que el nmero global de hombres y mujeres que son clientes en esa tienda es igual aplicando la prueba de ji cuadrada y utilizando el nivel de significancia del 5%. Tabla 12.10 Frecuencias observadas y esperadas para el problema 12.1. Clientes Hombres Nmero en la Muestra (f0) 25 15 Total 40 17 Mujeres
Nmero Esperado 20 (fe) De la tabla 12.10.
20
40
H0 : El nmero de clientes hombres y mujeres el igual. H1: El nmero de clientes hombres y mujeres no es igual. gl = k m 1 = 2 0 1 = 1 X2 crtica (gl = 1, = 0.05) = 3.84 La estadstica de prueba calculada, 2.50, no es mayor que el valor crtico de 3.84. Por lo tanto, no es posible rechazar la hiptesis nula a un nivel de significancia del 5%.
F Y F F 0.99 0.95
18
También podría gustarte
- Intro EstadisticaDocumento51 páginasIntro EstadisticaAnonymous OQxqdoAún no hay calificaciones
- Problemario de Estadistica AplicadaDocumento14 páginasProblemario de Estadistica Aplicadademiblackvato1Aún no hay calificaciones
- Suponga Que Una Compañía de Seguros Cuenta Con 200 Asegurados en El PaísDocumento1 páginaSuponga Que Una Compañía de Seguros Cuenta Con 200 Asegurados en El PaísJaun Alfredo Vilca LinaresAún no hay calificaciones
- Capitulo 11Documento38 páginasCapitulo 11serestadAún no hay calificaciones
- Prueba de HipotesisDocumento14 páginasPrueba de HipotesisChristian JH CosiAún no hay calificaciones
- Taller 2 EstadisticaDocumento15 páginasTaller 2 Estadisticajuan rojasAún no hay calificaciones
- TALLER 1 NOV. 05 Istribuciones de Muestreo de La Media y SimulacionesDocumento15 páginasTALLER 1 NOV. 05 Istribuciones de Muestreo de La Media y SimulacionesYOSHIRA LILIAN RIOS JIMENEZAún no hay calificaciones
- GRUPAL Estadistica Unidad 2 Tarea3Documento29 páginasGRUPAL Estadistica Unidad 2 Tarea3ximena sarmientoAún no hay calificaciones
- T Contin Gencia SDocumento13 páginasT Contin Gencia SDagoAún no hay calificaciones
- Prueba de Hipótesis PDFDocumento59 páginasPrueba de Hipótesis PDFFęrnåndö ŁùdêńäAún no hay calificaciones
- Departamento de Estadística y MatemáticasDocumento10 páginasDepartamento de Estadística y MatemáticasDeisy GomezAún no hay calificaciones
- Examen 23 Noviembre 2018 Preguntas y RespuestasDocumento5 páginasExamen 23 Noviembre 2018 Preguntas y RespuestasJOSE AUGUSTO QUISPE MUNARESAún no hay calificaciones
- 2.5 Ejercicios Prueba de Bondad de AjusteDocumento3 páginas2.5 Ejercicios Prueba de Bondad de AjustePaulina Andrea Canto SolísAún no hay calificaciones
- Semana03 BDocumento3 páginasSemana03 BDIEGO TOLENTINO0% (1)
- Presentación 14Documento22 páginasPresentación 14Clavely PirirAún no hay calificaciones
- ESTIMACIONESDocumento25 páginasESTIMACIONESElias Charcape OtinianoAún no hay calificaciones
- t3 Estimacion de ParametrosDocumento3 páginast3 Estimacion de ParametrosAnonymous vwftNc0qzAún no hay calificaciones
- Guia PHDocumento26 páginasGuia PHIvanOrdoñezAún no hay calificaciones
- Practico 1Documento15 páginasPractico 1Isaias Balderrama HerediaAún no hay calificaciones
- Taller-Plan - Pruebas Esta I - HipotesisDocumento6 páginasTaller-Plan - Pruebas Esta I - Hipotesisrosita61Aún no hay calificaciones
- Lo 2Documento17 páginasLo 2Joel SuarezAún no hay calificaciones
- Prueba de Hipótesis Media 2Documento11 páginasPrueba de Hipótesis Media 2Mery Fernández HurtadoAún no hay calificaciones
- Estdistic Deber 3Documento12 páginasEstdistic Deber 3Roberth SanchezAún no hay calificaciones
- Estimación Estadística - A Estadistica Inferencial 1920 2890Documento6 páginasEstimación Estadística - A Estadistica Inferencial 1920 2890Sebastian LadinoAún no hay calificaciones
- Practica Nro 1 Pronosticos para Los ProyectosDocumento22 páginasPractica Nro 1 Pronosticos para Los ProyectosHugo PinoAún no hay calificaciones
- Modulo III - Sesión 11.01.prueba de HipotesisDocumento54 páginasModulo III - Sesión 11.01.prueba de HipotesisElena LostaunauAún no hay calificaciones
- Tarea 2Documento8 páginasTarea 2Monii Robledo67% (3)
- Inferencia Estadística - LaboratorioDocumento9 páginasInferencia Estadística - LaboratorioYURIAún no hay calificaciones
- Ejemplo de Solucion de Ejercicios ADA1Documento4 páginasEjemplo de Solucion de Ejercicios ADA1jose kaka100% (1)
- 05-Análisis de DecisionesDocumento26 páginas05-Análisis de DecisionesErick MontesAún no hay calificaciones
- Unidad3 Inf EstadisticaDocumento63 páginasUnidad3 Inf Estadisticajor_jurAún no hay calificaciones
- Pruebas No ParametricasDocumento47 páginasPruebas No ParametricasGabriela AguileraAún no hay calificaciones
- Ejercicios Varios de Prueba de HipotesisDocumento3 páginasEjercicios Varios de Prueba de HipotesisLuis Alfons Beltrán RíosAún no hay calificaciones
- Resumen Primer Capítulo 1 Análisis Financiero Petersen and PlenborgDocumento7 páginasResumen Primer Capítulo 1 Análisis Financiero Petersen and PlenborgDavid AlejandroAún no hay calificaciones
- Apuntes Estadistica IIDocumento16 páginasApuntes Estadistica IIPablito Amurrio NavarroAún no hay calificaciones
- Prueba de HipótesisDocumento22 páginasPrueba de HipótesisGerardo ConisllaAún no hay calificaciones
- Prueba de Hipótesis Acerca de Una Proporción: N X N X ... X X PDocumento5 páginasPrueba de Hipótesis Acerca de Una Proporción: N X N X ... X X PSegundo Elvis Huanca FloresAún no hay calificaciones
- Formulas para El Muestreo Aleatorio SimpleDocumento7 páginasFormulas para El Muestreo Aleatorio SimpleAnabel RuizAún no hay calificaciones
- Actividad de Aprendizaje Autónomo 2 - SoluciónDocumento4 páginasActividad de Aprendizaje Autónomo 2 - SoluciónAnalisisRisk2012Aún no hay calificaciones
- Prueba de Hipótesis CDDocumento23 páginasPrueba de Hipótesis CDCarlos Caruajulca TigllaAún no hay calificaciones
- TALLER Unidad 3 - Actividad 4Documento2 páginasTALLER Unidad 3 - Actividad 4William Orlando HERRERA MESAAún no hay calificaciones
- Tarea 1 PDFDocumento2 páginasTarea 1 PDFNancy Paola Sanchez GonzalezAún no hay calificaciones
- FRPB Das Plantilla Especificacion Diseno2022 (Final)Documento168 páginasFRPB Das Plantilla Especificacion Diseno2022 (Final)carlos parkerAún no hay calificaciones
- 3 TemaDocumento13 páginas3 TemaSasuke UchihaaAún no hay calificaciones
- Practica Dirigida Unidad 3 - Prueba de Hipótesis-Medias - Sig. DesconocidaDocumento6 páginasPractica Dirigida Unidad 3 - Prueba de Hipótesis-Medias - Sig. DesconocidaAngel Inconfundible Povis OreAún no hay calificaciones
- EjercvariablesaleatoriasymodelosrespuestasDocumento18 páginasEjercvariablesaleatoriasymodelosrespuestasBenjamin Enoc67% (3)
- Taller Grupal 2 - Grupo 7Documento26 páginasTaller Grupal 2 - Grupo 7DeiviAún no hay calificaciones
- Hipotesis Estadisitica 2 UsacDocumento5 páginasHipotesis Estadisitica 2 UsacMiguel Bedoya0% (1)
- Regresion y Correlacion PDFDocumento9 páginasRegresion y Correlacion PDFDana M. TAún no hay calificaciones
- Taller 4 Pruebas H. ProporcionesDocumento2 páginasTaller 4 Pruebas H. ProporcionesSergio CorreaAún no hay calificaciones
- Tarea 3 Semana 4 Estadistica Aplicada 2Documento5 páginasTarea 3 Semana 4 Estadistica Aplicada 2Valenzuela OlgaAún no hay calificaciones
- Ev. 2 EQ.2Documento19 páginasEv. 2 EQ.2Luis fernando CRAún no hay calificaciones
- Hipergeométrica y Poisson.Documento25 páginasHipergeométrica y Poisson.EMANUEL RUIZ HERNANDEZAún no hay calificaciones
- Taller Práctico en RDocumento7 páginasTaller Práctico en RmarilynAún no hay calificaciones
- Ejercicios de Est Imac Ion Por IntervalosDocumento11 páginasEjercicios de Est Imac Ion Por IntervalosManuel Alvariño Torres0% (2)
- Asignacion - Unidad 3 - Parte 3Documento3 páginasAsignacion - Unidad 3 - Parte 3William miguel Herrera rodriguezAún no hay calificaciones
- Taller 1 - Estadistica Inferencial1 - SolucionadoDocumento5 páginasTaller 1 - Estadistica Inferencial1 - Solucionadocarlos mario Maestre100% (1)
- Aproximacion Paola..Documento19 páginasAproximacion Paola..Darwin Darwin Jaya CarpioAún no hay calificaciones
- Etapas Básicas en Pruebas de HipótesisDocumento3 páginasEtapas Básicas en Pruebas de HipótesisAntonio BrambilaAún no hay calificaciones
- Psicometria YashiDocumento6 páginasPsicometria YashiavelitoAún no hay calificaciones
- Prob Dist Muestral MediasDocumento10 páginasProb Dist Muestral MediasavelitoAún no hay calificaciones
- COESI Diagramas de Dispersion y Series de TiempoDocumento2 páginasCOESI Diagramas de Dispersion y Series de Tiempoavelito67% (3)
- Desarrollo de Instrumentos PsicologicospdfDocumento5 páginasDesarrollo de Instrumentos PsicologicospdfavelitoAún no hay calificaciones
- 9 Conceptos EstDocumento14 páginas9 Conceptos EstavelitoAún no hay calificaciones
- Taller 7 Prueba Hipo SpssDocumento2 páginasTaller 7 Prueba Hipo SpssavelitoAún no hay calificaciones