También podría gustarte
- Intervalos de ConfianzaDocumento5 páginasIntervalos de ConfianzaSusan Guillermo Mayta60% (10)
- Regresión Lineal SimpleDocumento47 páginasRegresión Lineal SimpleNixonloloAún no hay calificaciones
- MiFee - CL - Inferencia Modelo MultipleDocumento18 páginasMiFee - CL - Inferencia Modelo MultiplepaquebotttAún no hay calificaciones
- Pruebas de HipótesisDocumento27 páginasPruebas de HipótesisHenry MolinaAún no hay calificaciones
- Econometrics - 04 - SimpleRegression (1) 2Documento16 páginasEconometrics - 04 - SimpleRegression (1) 2Shair TroyaAún no hay calificaciones
- Regresion Lineal 34165Documento26 páginasRegresion Lineal 34165juan rodolfo soncco apafataAún no hay calificaciones
- Regresion Lineal Múltiple: Parte IIDocumento34 páginasRegresion Lineal Múltiple: Parte IIJOSE FRANCISCO JAVIER OLIVOS VALENZUELAAún no hay calificaciones
- 03.4.3 Pruebas de SignificanciaDocumento8 páginas03.4.3 Pruebas de SignificanciaJaneAún no hay calificaciones
- Control 4 D PautaDocumento5 páginasControl 4 D PautaNicole HerreraAún no hay calificaciones
- 4 Modelo de Regresion Lineal Simple Inferencia EstadisticaDocumento36 páginas4 Modelo de Regresion Lineal Simple Inferencia EstadisticaAlejandro Sebastián Piñeiro CaroAún no hay calificaciones
- Regresión Lineal SimpleDocumento26 páginasRegresión Lineal SimpleCm JiMy Huaman100% (1)
- Apuntes EconometríaDocumento16 páginasApuntes EconometríaMarc PalauAún no hay calificaciones
- S1 - Apunte 3 - EconomnetríaDocumento14 páginasS1 - Apunte 3 - EconomnetríacRISTIANAún no hay calificaciones
- Solucionario2016 IIDocumento8 páginasSolucionario2016 IIsaisisis100% (1)
- Regresion Lineal Simple IIDocumento40 páginasRegresion Lineal Simple IItomas claverieAún no hay calificaciones
- Repaso de EstadisticaDocumento29 páginasRepaso de EstadisticaDarwin UberuagaAún no hay calificaciones
- Analisis de Regresion LinealDocumento13 páginasAnalisis de Regresion Linealanon_516027180Aún no hay calificaciones
- Transparencias Tema III: Modelo Básico de Regresión Lineal Múltiple IIDocumento52 páginasTransparencias Tema III: Modelo Básico de Regresión Lineal Múltiple IIEmilyAún no hay calificaciones
- Con Apuntes de ClaseDocumento23 páginasCon Apuntes de ClasehayddemacahuachiestebanAún no hay calificaciones
- Modelos de RegresionDocumento53 páginasModelos de RegresionArturo SempérteguiAún no hay calificaciones
- Ayudantía 3 (Enunciado)Documento8 páginasAyudantía 3 (Enunciado)Rodrigo VillenaAún no hay calificaciones
- ALEKS8Documento4 páginasALEKS8César CastilloAún no hay calificaciones
- Ajuste de Curva - Método Del Mínimo CuadradoDocumento11 páginasAjuste de Curva - Método Del Mínimo CuadradoMaricel Anahi Carbajal SantacruzAún no hay calificaciones
- Regresion LinealDocumento16 páginasRegresion Linealdemon RAún no hay calificaciones
- Guia. Análisis Con SPSS y R.Documento6 páginasGuia. Análisis Con SPSS y R.Pierre KebudiAún no hay calificaciones
- CorrelaciónDocumento22 páginasCorrelaciónERIKA TATIANA PATINO JIMENEZAún no hay calificaciones
- Regresion LinealDocumento18 páginasRegresion Linealcesar vasquez trejoAún no hay calificaciones
- Preguntas Teoricas-Tema7 - Corregidas (11-5-20)Documento3 páginasPreguntas Teoricas-Tema7 - Corregidas (11-5-20)Trabajos y Algo MásAún no hay calificaciones
- Pauta EDocumento6 páginasPauta EMarco Sandoval QuidelAún no hay calificaciones
- Guia 15. Inferencia para La Regresión PDFDocumento8 páginasGuia 15. Inferencia para La Regresión PDFMaykol Daniel Leon ArdilaAún no hay calificaciones
- Tema 4 Inferencia Estadistica en El Analisis de Regresion 476511Documento45 páginasTema 4 Inferencia Estadistica en El Analisis de Regresion 476511JaAún no hay calificaciones
- Teoría - Regresión Lineal Simple - SoluciónDocumento8 páginasTeoría - Regresión Lineal Simple - SoluciónjessicaAún no hay calificaciones
- Inferencia EstadísticaDocumento28 páginasInferencia EstadísticaJoel ParcoAún no hay calificaciones
- Modelo de Regresion Lineal General 2Documento22 páginasModelo de Regresion Lineal General 2marielaramirezparraAún no hay calificaciones
- Modelo Lineal General Eco I - FormatosDocumento17 páginasModelo Lineal General Eco I - FormatosJesus Coila apazaAún no hay calificaciones
- EnsayoDocumento18 páginasEnsayoomaxvetAún no hay calificaciones
- Regresión Lineal Simple (Con Minitab)Documento25 páginasRegresión Lineal Simple (Con Minitab)Cristhian Serra AlburquequeAún no hay calificaciones
- Modelo de Regresión Lineal SimpleDocumento8 páginasModelo de Regresión Lineal SimpleBYRON FERNANDO SIGUENZA PAGUAYAún no hay calificaciones
- RLM Regresión Lineal MúltipleDocumento11 páginasRLM Regresión Lineal MúltipleMas Kuc LksAún no hay calificaciones
- EST407 Regresion Multiple InferenciaDocumento18 páginasEST407 Regresion Multiple InferenciaRoberto Jalon GardellaAún no hay calificaciones
- EconometriaDocumento7 páginasEconometriaANDRESAún no hay calificaciones
- Regresión Lineal Simple y CorrelaciónDocumento57 páginasRegresión Lineal Simple y CorrelaciónCesar OliveraAún no hay calificaciones
- Regresión LinealDocumento24 páginasRegresión LinealIngrid RoveloAún no hay calificaciones
- Bioest 2.4 - Regresión Simple y CorrelaciónDocumento37 páginasBioest 2.4 - Regresión Simple y CorrelaciónFabricio Freire YepezAún no hay calificaciones
- Regresion Lineal EjemploDocumento47 páginasRegresion Lineal EjemploQuetz Que SantiagoAún no hay calificaciones
- Estadística Descriptiva Unidad 7Documento15 páginasEstadística Descriptiva Unidad 7Víctor Hugo FernándezAún no hay calificaciones
- Pruebas de Hipótesis MRLDocumento29 páginasPruebas de Hipótesis MRLDavid AyalaAún no hay calificaciones
- Sesión 5Documento18 páginasSesión 5José AguilarAún no hay calificaciones
- Problema 2 Del Control A La Fabricacion de TornillosDocumento8 páginasProblema 2 Del Control A La Fabricacion de Tornillosjean carlosAún no hay calificaciones
- Modelo Potencial CorregidoDocumento12 páginasModelo Potencial CorregidoRenuevix CelestialAún no hay calificaciones
- TYCPPS - Sesión 16-17. Sensibilidad y Especificidad. Regresión LogísticaDocumento29 páginasTYCPPS - Sesión 16-17. Sensibilidad y Especificidad. Regresión Logísticaantonio muñozAún no hay calificaciones
- Semana 15-S1-AQPDocumento5 páginasSemana 15-S1-AQPGustavo DelgadoAún no hay calificaciones
- Tema 4Documento14 páginasTema 4Marc Pastor PouAún no hay calificaciones
- Regresion Lineal SimpleDocumento14 páginasRegresion Lineal SimplefacenunaAún no hay calificaciones
- Econometría Cap 4 y 5Documento24 páginasEconometría Cap 4 y 5KAREN DANIELA FAJARDO MATALLANAAún no hay calificaciones
- Unidad-IV-regresion y Correlacion 10115 2022-1Documento14 páginasUnidad-IV-regresion y Correlacion 10115 2022-1valentina belenAún no hay calificaciones
- Inferencia Estadistica - Un ParametroDocumento26 páginasInferencia Estadistica - Un Parametroj.oswaldochanAún no hay calificaciones
- Parcial 1 CsolDocumento13 páginasParcial 1 CsolksutolorenyzAún no hay calificaciones
- Inferencia en Regresion Lineal SimpleDocumento15 páginasInferencia en Regresion Lineal SimpleDani A' CarvajalAún no hay calificaciones
- Desarrollo Clase de EjerciciosDocumento7 páginasDesarrollo Clase de EjerciciosCarlos Vargas RodríguezAún no hay calificaciones
- Exportación PizarraDocumento2 páginasExportación PizarraCarlos Vargas RodríguezAún no hay calificaciones
- Gestión Del Activo CorrienteDocumento4 páginasGestión Del Activo CorrienteCarlos Vargas RodríguezAún no hay calificaciones
- Administración Del Capital de TrabajoDocumento2 páginasAdministración Del Capital de TrabajoCarlos Vargas RodríguezAún no hay calificaciones
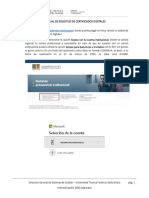
- Manual Solicitud CertificadoDocumento9 páginasManual Solicitud CertificadoCarlos Vargas RodríguezAún no hay calificaciones
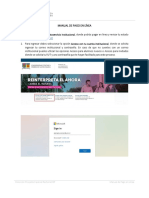
- ManualesDocumento8 páginasManualesCarlos Vargas RodríguezAún no hay calificaciones
- Plan de Capacitacion Suspel Codelco 2018 PDFDocumento22 páginasPlan de Capacitacion Suspel Codelco 2018 PDFCarlos Vargas RodríguezAún no hay calificaciones
- Armas Carabineros de ChileDocumento2 páginasArmas Carabineros de ChileCarlos Vargas RodríguezAún no hay calificaciones
- Actividad EstimaciònDocumento2 páginasActividad EstimaciònBarack ObamaAún no hay calificaciones
- TP19 Resueltos EstimacionDocumento31 páginasTP19 Resueltos EstimacionAdri MaidanaAún no hay calificaciones
- Taller #06Documento2 páginasTaller #06Karen DelgadoAún no hay calificaciones
- Cuestionario Resuelto Teoria de SistemasDocumento12 páginasCuestionario Resuelto Teoria de SistemasDhayanara Abilia Cardenas HuamanAún no hay calificaciones
- Ordinario Estadistica1Documento7 páginasOrdinario Estadistica1Bon NbAún no hay calificaciones
- Intervalos de Confianza TAREADocumento1 páginaIntervalos de Confianza TAREAdaniela peña hernandez0% (4)
- Ejercicios Del Tamao de La Muestra CompressDocumento12 páginasEjercicios Del Tamao de La Muestra CompressLuyo LeslieAún no hay calificaciones
- Tarea N°5 - Aguilar FloresDocumento4 páginasTarea N°5 - Aguilar FloresArthur AlbertAún no hay calificaciones
- Semana 13 Prueba de HipotesisDocumento49 páginasSemana 13 Prueba de Hipotesissantiago jaraAún no hay calificaciones
- Sustentacion Estadistica 2Documento5 páginasSustentacion Estadistica 2Ivo NaizirAún no hay calificaciones
- Ejercicios IC Relacionado Con La MediaDocumento5 páginasEjercicios IC Relacionado Con La Mediaadi martinezzarateAún no hay calificaciones
- S04.s2 - Material IC VARIANZA EIDocumento15 páginasS04.s2 - Material IC VARIANZA EIJesús CruzAún no hay calificaciones
- Tema V Estadisticas InferencialDocumento29 páginasTema V Estadisticas InferencialDiego MejíasAún no hay calificaciones
- Propuesta Estadística IIDocumento3 páginasPropuesta Estadística IIjonathan bldkAún no hay calificaciones
- Enunciado Producto Académico N°1Documento53 páginasEnunciado Producto Académico N°1mizaelAún no hay calificaciones
- Tarea 1Documento8 páginasTarea 1Cinthia Melendez100% (1)
- Laboratorio 1Documento2 páginasLaboratorio 1Milton Alfonso Gomez GonzalezAún no hay calificaciones
- Sesión 21 Regresión Bivariada Los Supuestos 27.10.20 XDocumento37 páginasSesión 21 Regresión Bivariada Los Supuestos 27.10.20 XCristóbal Karle SaavedraAún no hay calificaciones
- Grupo N°2: Modelo de Regresion Lineal: EstudiantesDocumento33 páginasGrupo N°2: Modelo de Regresion Lineal: EstudiantesLuz MontecinosAún no hay calificaciones
- Guías de Trabajos Prácticos de FisicoquímicaDocumento30 páginasGuías de Trabajos Prácticos de FisicoquímicaMelina AlvezAún no hay calificaciones
- Introducción A La Regresión Lineal PDFDocumento78 páginasIntroducción A La Regresión Lineal PDFFranco Germán BaroneAún no hay calificaciones
- Valores Extremos TesisDocumento101 páginasValores Extremos TesisAlejandro Patricio Maureira GomezAún no hay calificaciones
- Tema 4Documento10 páginasTema 4David GraterolAún no hay calificaciones
- Ejercicios de Repaso Parte 2Documento4 páginasEjercicios de Repaso Parte 2nelcy0% (1)
- Anexo Plantamiento Del TrabajoDocumento9 páginasAnexo Plantamiento Del TrabajoCarlos MoralesAún no hay calificaciones
- Datos CategóricosDocumento4 páginasDatos CategóricosJAIRO HERNAN ESPINOZA ANDRADEAún no hay calificaciones
- Teoria ProbabilidadDocumento8 páginasTeoria ProbabilidadMilagros ScarinciAún no hay calificaciones
- Análisis Multivariable de Los Efectos de La Variación de Precio y Métodos de Resolución en El Tiempo de Resolucion Del Cubo de RubikDocumento19 páginasAnálisis Multivariable de Los Efectos de La Variación de Precio y Métodos de Resolución en El Tiempo de Resolucion Del Cubo de RubikalessxavismAún no hay calificaciones
- Lectura 05 de Estadistica PDFDocumento15 páginasLectura 05 de Estadistica PDFjose ruizAún no hay calificaciones