0% encontró este documento útil (0 votos)
25 vistas22 páginasMódulo 3 - Lectura 4
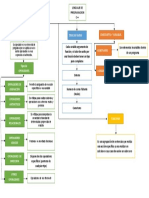
El documento aborda los algoritmos de ordenación, destacando su importancia en la organización de datos para facilitar procesos como la búsqueda. Se describen varios algoritmos, incluyendo ordenamiento por inserción, Shellsort, mergesort y quicksort, cada uno con sus características, procesos de ordenamiento y tiempos de ejecución. Se enfatiza que el rendimiento de estos algoritmos puede variar según el tamaño y el orden inicial de los datos.
Cargado por
Agus TamaDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como PDF, TXT o lee en línea desde Scribd
0% encontró este documento útil (0 votos)
25 vistas22 páginasMódulo 3 - Lectura 4
El documento aborda los algoritmos de ordenación, destacando su importancia en la organización de datos para facilitar procesos como la búsqueda. Se describen varios algoritmos, incluyendo ordenamiento por inserción, Shellsort, mergesort y quicksort, cada uno con sus características, procesos de ordenamiento y tiempos de ejecución. Se enfatiza que el rendimiento de estos algoritmos puede variar según el tamaño y el orden inicial de los datos.
Cargado por
Agus TamaDerechos de autor
© © All Rights Reserved
Nos tomamos en serio los derechos de los contenidos. Si sospechas que se trata de tu contenido, reclámalo aquí.
Formatos disponibles
Descarga como PDF, TXT o lee en línea desde Scribd