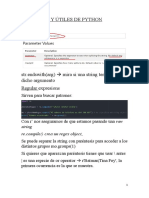
También podría gustarte
- DHL 2179792635Documento3 páginasDHL 2179792635Aaron AguilarAún no hay calificaciones
- Aprende a Programar en MATLABDe EverandAprende a Programar en MATLABCalificación: 3.5 de 5 estrellas3.5/5 (11)
- Diseño y Calculo de Una CalderaDocumento91 páginasDiseño y Calculo de Una CalderaAlex Sāpes100% (1)
- Brochure SSI Aeration ESDocumento16 páginasBrochure SSI Aeration ESJosé Luis Nava RebollarAún no hay calificaciones
- Conceptos Basicos en Dev C ++Documento18 páginasConceptos Basicos en Dev C ++Zayra Salas0% (1)
- Ejercicios Guiados de Punteros en C++, 6 HojasDocumento6 páginasEjercicios Guiados de Punteros en C++, 6 Hojasjuliocesarmota50% (2)
- Ciencia Datos Phyton Modulo2 Unidad1Documento18 páginasCiencia Datos Phyton Modulo2 Unidad1WALYS VERA HERRERA100% (1)
- Diseño de Trampa de GrasaDocumento12 páginasDiseño de Trampa de Grasarodolfo granizo100% (1)
- Octave TrucosDocumento5 páginasOctave Trucosjgarcia177Aún no hay calificaciones
- Resumen PC Segundo ParcialDocumento12 páginasResumen PC Segundo ParcialMilagros BustosAún no hay calificaciones
- Practica PythonDocumento7 páginasPractica PythoncamiAún no hay calificaciones
- Arreglos BidimensionalesDocumento8 páginasArreglos BidimensionalesMiguel ParraAún no hay calificaciones
- Pequeño Paseo Por La Biblioteca Estándar - Parte II - Documentación de Python - 3.10.8 PDFDocumento7 páginasPequeño Paseo Por La Biblioteca Estándar - Parte II - Documentación de Python - 3.10.8 PDFrodrigo algoAún no hay calificaciones
- Guia Lab0 1 PDS 2018 2Documento8 páginasGuia Lab0 1 PDS 2018 2davidt1516Aún no hay calificaciones
- Dev C++Documento13 páginasDev C++Johanna Negrete SanchezAún no hay calificaciones
- Apuntes de PythonDocumento49 páginasApuntes de Pythonrudyard2021Aún no hay calificaciones
- Practica 7Documento32 páginasPractica 7manuelfr99Aún no hay calificaciones
- Octave TrucosDocumento6 páginasOctave Trucosjgarcia177Aún no hay calificaciones
- Practica Cluster 2Documento6 páginasPractica Cluster 2Alejandro Fernández PeralAún no hay calificaciones
- Guia Lab1 1Documento8 páginasGuia Lab1 1Barba RojaAún no hay calificaciones
- Visualización y Análisis de Datos Con PythonDocumento32 páginasVisualización y Análisis de Datos Con Pythonsantiagoromo10Aún no hay calificaciones
- P10 - Edai Franciso JavierDocumento7 páginasP10 - Edai Franciso JavierPaulina Bastida GarciaAún no hay calificaciones
- Modulos de ScipyDocumento15 páginasModulos de ScipyWalter OrdoñezAún no hay calificaciones
- Scrib Es Una Ladilla CapitalistaDocumento10 páginasScrib Es Una Ladilla CapitalistaMaria V B GuerraAún no hay calificaciones
- El Lenguaje Python - Libro Web2py v1 Documentation-3Documento9 páginasEl Lenguaje Python - Libro Web2py v1 Documentation-3Fernando JaboneroAún no hay calificaciones
- 04 8 Python 0Documento22 páginas04 8 Python 0Oscar Jhin LSGAún no hay calificaciones
- Es DatosDocumento44 páginasEs Datosrodri2507Aún no hay calificaciones
- Repaso de ProgramacionDocumento3 páginasRepaso de ProgramacionLorena GuerreroAún no hay calificaciones
- Introduccion A CPP (Basico)Documento26 páginasIntroduccion A CPP (Basico)Juan Jose Ramirez LamaAún no hay calificaciones
- Introduccion A CPPDocumento26 páginasIntroduccion A CPPJuan Jose Ramirez LamaAún no hay calificaciones
- Matrices y Listas PythonDocumento6 páginasMatrices y Listas Pythonavigail ceballosAún no hay calificaciones
- Guia No.5 JDocumento15 páginasGuia No.5 JArmando LucianoAún no hay calificaciones
- Asignacion de Memoria Dinamica y Estructuras en CDocumento6 páginasAsignacion de Memoria Dinamica y Estructuras en CmardospazAún no hay calificaciones
- Elementos de Dev C++Documento11 páginasElementos de Dev C++Adan LiceaAún no hay calificaciones
- Programacion Orientada A Objetos - Archivos de DatosDocumento19 páginasProgramacion Orientada A Objetos - Archivos de DatosMiguel CarreonAún no hay calificaciones
- 4.1. Numpy - Computación Científica Con Python para Módulos de Evaluación Continua en Asignaturas de Ciencias AplicadasDocumento5 páginas4.1. Numpy - Computación Científica Con Python para Módulos de Evaluación Continua en Asignaturas de Ciencias AplicadasFABIANCHO2210Aún no hay calificaciones
- Entrada y Salida - Documentación de Python - 3.10.8Documento8 páginasEntrada y Salida - Documentación de Python - 3.10.8rodrigo algoAún no hay calificaciones
- Trabajo Final FuncionesDocumento16 páginasTrabajo Final FuncionesJuan jose Alcalá FajardoAún no hay calificaciones
- Apuntes de PythonDocumento15 páginasApuntes de PythonPablo Perez Martin100% (1)
- Resumen Parcial 02Documento9 páginasResumen Parcial 02Milagros BustosAún no hay calificaciones
- Laboratorio NumpyDocumento9 páginasLaboratorio NumpyRemigio Rodríguez A.Aún no hay calificaciones
- Tarea 2Documento13 páginasTarea 2Mariana SánchezAún no hay calificaciones
- 101.2. Procesar Cadenas de Texto Por Medio de FiltrosDocumento7 páginas101.2. Procesar Cadenas de Texto Por Medio de FiltrosDaniel Sánchez Jiménez-PajareroAún no hay calificaciones
- Practica de Python - DianaPerezAcostaDocumento23 páginasPractica de Python - DianaPerezAcostaDIANA CAROLINA PEREZ ACOSTAAún no hay calificaciones
- 4.1. Numpy: 4.1.1. Carga de Un Archivo de DatosDocumento3 páginas4.1. Numpy: 4.1.1. Carga de Un Archivo de DatosGabriel David Quispe SanesAún no hay calificaciones
- PythonDocumento14 páginasPythonCarlos YusteAún no hay calificaciones
- Cadenas de CaracteresDocumento6 páginasCadenas de CaracteresnicolasAún no hay calificaciones
- Manipulación de Datos en RDocumento47 páginasManipulación de Datos en ROscar Javier Ojeda GomezAún no hay calificaciones
- Entrada y SalidasDocumento3 páginasEntrada y SalidasOpen Box LaptopsAún no hay calificaciones
- Clase 13Documento13 páginasClase 13ArielAún no hay calificaciones
- Clase R PrimeraDocumento12 páginasClase R PrimeraAlexiaAún no hay calificaciones
- 3 3.1.4.6 Lab - Descriptive Statistics in Python MarkDocumento8 páginas3 3.1.4.6 Lab - Descriptive Statistics in Python MarkmarkAún no hay calificaciones
- Modulo 9 - Estructuras de Datos DinámicasDocumento7 páginasModulo 9 - Estructuras de Datos DinámicasJuan Martin BiedmaAún no hay calificaciones
- GuerraDocumento5 páginasGuerraJean CarloAún no hay calificaciones
- Python 4Documento6 páginasPython 4Nivardo romero huaytaAún no hay calificaciones
- 07 Entradas-y-salidas-en-RDocumento19 páginas07 Entradas-y-salidas-en-RJLMAún no hay calificaciones
- Python ModulosDocumento12 páginasPython ModulosJuanAún no hay calificaciones
- Unidad 2 ArreglosDocumento3 páginasUnidad 2 ArreglosLuis RodriguezAún no hay calificaciones
- Lab06 - Integración Con Hojas de CálculoDocumento15 páginasLab06 - Integración Con Hojas de CálculoNacho TobíaAún no hay calificaciones
- Factores y VectoresDocumento13 páginasFactores y Vectoresjimenezriverajosealfredo6Aún no hay calificaciones
- Programacion en C Ejemplos PracticosDocumento42 páginasProgramacion en C Ejemplos PracticosaneudyhAún no hay calificaciones
- Generar Un Archivo DLL Matlab para Aplicarlo en LabviewDocumento10 páginasGenerar Un Archivo DLL Matlab para Aplicarlo en LabviewGuillermo ZubietaAún no hay calificaciones
- Estadística Descriptiva - Jupyter NotebookDocumento14 páginasEstadística Descriptiva - Jupyter NotebookJosé DanielAún no hay calificaciones
- Karen Osorio - Técnico Laboral en Contabilidad y FinanzasDocumento5 páginasKaren Osorio - Técnico Laboral en Contabilidad y Finanzaskaren cardonaAún no hay calificaciones
- Prevencion de Los Trastornos Musculares de Origen LaboralDocumento41 páginasPrevencion de Los Trastornos Musculares de Origen LaboralYO TE LO RESUMOAún no hay calificaciones
- Curriculum MarioDocumento2 páginasCurriculum MarioPamelaAlejandraImpresionadoAún no hay calificaciones
- Informe 01Documento8 páginasInforme 01Franklin Alarcon SilvaAún no hay calificaciones
- TruchaDocumento21 páginasTruchaPaola Abello RamirezAún no hay calificaciones
- Trabajo de Coso IIIDocumento41 páginasTrabajo de Coso IIIElvis Jhoel Antonio PerezAún no hay calificaciones
- El Canal de Panamá y Su Influencia Económica Con El EcuadorDocumento19 páginasEl Canal de Panamá y Su Influencia Económica Con El EcuadorCarlitos SalgadoAún no hay calificaciones
- Contrato PiomachDocumento3 páginasContrato PiomachKevin CaizaAún no hay calificaciones
- Analisis Del Comportamiento de MoraDocumento163 páginasAnalisis Del Comportamiento de MoraChris AC100% (1)
- Implementacion Del ISM Y PBIPDocumento1 páginaImplementacion Del ISM Y PBIPPaulAún no hay calificaciones
- 2.2 Tarea SemanaDocumento10 páginas2.2 Tarea SemanaMARIA FERNANDA GONZALEZ GARAYAún no hay calificaciones
- PRESENTACIONDocumento11 páginasPRESENTACIONAndreAún no hay calificaciones
- PracticasIO1 R LPDocumento3 páginasPracticasIO1 R LPjorgemtz_91Aún no hay calificaciones
- Unidad I Conta BancosDocumento8 páginasUnidad I Conta BancosLucia100% (1)
- Actividad ShodanDocumento4 páginasActividad Shodandaniel rodriguezAún no hay calificaciones
- Tarea Variables Aleatorias Juan JiyeDocumento9 páginasTarea Variables Aleatorias Juan JiyeJorge Gustavo Santiago SotoAún no hay calificaciones
- Presentación 1 Algoritmo 1Documento18 páginasPresentación 1 Algoritmo 1Eliana ZangrandiAún no hay calificaciones
- WSADocumento86 páginasWSAAngieRosalesAún no hay calificaciones
- Brochure COPARCO SACDocumento9 páginasBrochure COPARCO SACAlexAún no hay calificaciones
- GA C!Ta Judicial: SerieDocumento268 páginasGA C!Ta Judicial: Seriesteven tumbacoAún no hay calificaciones
- Vehículos Eléctricos Híbridos y La BateríaDocumento6 páginasVehículos Eléctricos Híbridos y La BateríaPedro HernándezAún no hay calificaciones
- Informe Rocard (Castellano)Documento17 páginasInforme Rocard (Castellano)manuelmchAún no hay calificaciones
- Codigo Diciplinario Del AbogadoDocumento48 páginasCodigo Diciplinario Del AbogadoadrianaAún no hay calificaciones
- Matriz FodaDocumento1 páginaMatriz FodaDesiré CamachoAún no hay calificaciones
- Analisis de Rstricciones en ObrasDocumento1 páginaAnalisis de Rstricciones en ObrasDaniel Zadam CMAún no hay calificaciones
- Briefcase El Ojo 2022 - Concurso Nuevos - Tu También Eres Artista AlternativoDocumento3 páginasBriefcase El Ojo 2022 - Concurso Nuevos - Tu También Eres Artista AlternativoAgustin FugazzaAún no hay calificaciones