También podría gustarte
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Farmacometría:Curvas dosis-respuesta de tipo gradual. Volumen 1De EverandFarmacometría:Curvas dosis-respuesta de tipo gradual. Volumen 1Aún no hay calificaciones
- Curva ROC y la teoría de las decisiones en las Ciencias de la SaludDe EverandCurva ROC y la teoría de las decisiones en las Ciencias de la SaludAún no hay calificaciones
- Informe AnovaDocumento11 páginasInforme AnovaJani LagosAún no hay calificaciones
- Anestesicos y AnalgesicoDocumento10 páginasAnestesicos y Analgesicoluisdaniel molinaAún no hay calificaciones
- Metabolismo de LípidosDocumento43 páginasMetabolismo de LípidosBELLA TANIA LLAMO DIAZAún no hay calificaciones
- 9-Marketing de Contenidos (Content Marketing)Documento22 páginas9-Marketing de Contenidos (Content Marketing)Ángela Arias LópezAún no hay calificaciones
- Ejercicios Multiples de ProbabilidadDocumento17 páginasEjercicios Multiples de ProbabilidadMelissa CastellanosAún no hay calificaciones
- La HomocedasticidadDocumento6 páginasLa HomocedasticidadItati Murillo AnchundiaAún no hay calificaciones
- Actividad6 DefiniciónymedicióndesistemasdecalidadDocumento12 páginasActividad6 DefiniciónymedicióndesistemasdecalidadalfredoAún no hay calificaciones
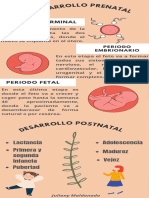
- Infografia Desarrollo Prenatal y PostnatalDocumento5 páginasInfografia Desarrollo Prenatal y PostnatalJuliany Maldonado100% (2)
- Prueba DuncanDocumento21 páginasPrueba DuncanDayann BernalAún no hay calificaciones
- Examen Metodologia de La InvestigacionDocumento4 páginasExamen Metodologia de La InvestigacionPower Bank100% (1)
- Medidas de VariabilidadDocumento11 páginasMedidas de VariabilidadJuan Carlos RivasAún no hay calificaciones
- Actividad 7 Modelos Con Múltiples Variables ExplicativasDocumento7 páginasActividad 7 Modelos Con Múltiples Variables ExplicativasJeimmie Espino RamírezAún no hay calificaciones
- La Cortesia MonografiaDocumento18 páginasLa Cortesia MonografiaKaren Castro CabreraAún no hay calificaciones
- Analisis Parametrico y No ParamétricoDocumento10 páginasAnalisis Parametrico y No Paramétricogioyauro100% (1)
- La Metamorfosis de NarcisoDocumento7 páginasLa Metamorfosis de NarcisoManu Wa1K3RAún no hay calificaciones
- GL OsarioDocumento19 páginasGL Osariofeliza CarbajalAún no hay calificaciones
- Teoria EstadisticaDocumento3 páginasTeoria EstadisticaEMMANUEL ANASTACIO HERNANDEZ RAMIREZAún no hay calificaciones
- Cuestionario AnovaDocumento5 páginasCuestionario AnovaDhayanara Abilia Cardenas HuamanAún no hay calificaciones
- Estimación de ParametrosDocumento61 páginasEstimación de ParametrosEdgardo MolinaAún no hay calificaciones
- Esta Di SticaDocumento12 páginasEsta Di SticaHarold La Fuente PalominoAún no hay calificaciones
- Analisis de La Varianza FinalDocumento19 páginasAnalisis de La Varianza Finalpaloma100% (1)
- Estadistica InferencialDocumento7 páginasEstadistica InferencialKatia CervantesAún no hay calificaciones
- Teoría EstadísticaDocumento74 páginasTeoría Estadísticajoseee.27Aún no hay calificaciones
- Distribuciones MuestralesDocumento25 páginasDistribuciones MuestralesFrancisco JavierAún no hay calificaciones
- Diseño de Experimentos de Un FactorDocumento7 páginasDiseño de Experimentos de Un FactorAbigail ZuñigaAún no hay calificaciones
- Grados de Libertad y Analisis de VarianzaDocumento13 páginasGrados de Libertad y Analisis de VarianzaRafael BarónAún no hay calificaciones
- ¿Qué Es Un Modelo Estadístico LinealDocumento5 páginas¿Qué Es Un Modelo Estadístico LinealJose Alberto Sobrino MarAún no hay calificaciones
- Glosario Estadistica InferencialDocumento4 páginasGlosario Estadistica InferencialMariana Catalina Piza CastanedaAún no hay calificaciones
- AnovaDocumento5 páginasAnovaAlexander LoaizaAún no hay calificaciones
- Estimación Puntual y Por IntervalosDocumento8 páginasEstimación Puntual y Por IntervalosJorge Luis LlerenaAún no hay calificaciones
- 10 Testcom1v - Et PDFDocumento9 páginas10 Testcom1v - Et PDFHerbertMendozaAroAún no hay calificaciones
- Tarea 4Documento8 páginasTarea 4Alex ZamoraAún no hay calificaciones
- ADEVADocumento5 páginasADEVAIñaky ChalampuenteAún no hay calificaciones
- MODULO 3 - ResumenDocumento8 páginasMODULO 3 - ResumenDaniel de Oliveira CorrêaAún no hay calificaciones
- Unidad 5 Estadistica AplicadaDocumento8 páginasUnidad 5 Estadistica AplicadaJ Manuel Haü KüAún no hay calificaciones
- Capítulo 1Documento114 páginasCapítulo 1Vidal Emmanuel Jaquehua MasiasAún no hay calificaciones
- Información de EstadísticaDocumento6 páginasInformación de EstadísticaAlexander MartínezAún no hay calificaciones
- RAUDRYDocumento13 páginasRAUDRYOmarAún no hay calificaciones
- Evaluacion de Datos AnaliticosDocumento27 páginasEvaluacion de Datos AnaliticosCondorAliagaHenryAún no hay calificaciones
- Análisis de La VarianzaDocumento20 páginasAnálisis de La VarianzaGerman RiveraAún no hay calificaciones
- Modulo 1 Actividad 2Documento6 páginasModulo 1 Actividad 2Miguel Angel CamposAún no hay calificaciones
- Proyecto Final CasiDocumento25 páginasProyecto Final CasiMathews RodriguezAún no hay calificaciones
- Residual EsDocumento5 páginasResidual EsOscar HerediaAún no hay calificaciones
- El Problema de La Estimación de La Media de La PoblaciónDocumento9 páginasEl Problema de La Estimación de La Media de La PoblaciónmarcoantonioramoscarAún no hay calificaciones
- Examen MultivarianteDocumento12 páginasExamen MultivariantePablo Fernández CarballeiraAún no hay calificaciones
- Inferencial, Chi CuadradaDocumento3 páginasInferencial, Chi CuadradaGabriela Isabel Roca MenesesAún no hay calificaciones
- EXCEL en Química AnalíticaDocumento47 páginasEXCEL en Química AnalíticaJuan Cho100% (1)
- Unidad I Teoria Estadistica Inferencial IIDocumento9 páginasUnidad I Teoria Estadistica Inferencial IIanaafloresAún no hay calificaciones
- Glosario de Analisis EstadisticoDocumento22 páginasGlosario de Analisis EstadisticoAlfonso Caracuel RomeroAún no hay calificaciones
- Supuestos Análisis de La VarianzaDocumento6 páginasSupuestos Análisis de La Varianzaestadistico17100% (1)
- VARIANZADocumento16 páginasVARIANZAdarylunaAún no hay calificaciones
- Investigación - PRUEBAS DE LA SIGNIFICACIÓN PARA LA REGRESIÓN LINEALDocumento7 páginasInvestigación - PRUEBAS DE LA SIGNIFICACIÓN PARA LA REGRESIÓN LINEALMARIA JOSE SOLIS DURANAún no hay calificaciones
- Estadística Descriptiva E Inferencial: Capítulo 22Documento12 páginasEstadística Descriptiva E Inferencial: Capítulo 22Dannsy BelenAún no hay calificaciones
- Actividad 1 Diseño de FármacosDocumento8 páginasActividad 1 Diseño de FármacosPaulina VegaAún no hay calificaciones
- Informe de EstadisticaDocumento9 páginasInforme de EstadisticaWexdran EnglishAún no hay calificaciones
- Deber para YaDocumento18 páginasDeber para YaAMANDA GRACIELA NINABANDA AGUALONGOAún no hay calificaciones
- Informe Prueba de LeveneDocumento12 páginasInforme Prueba de LeveneYulis Yulieth Llanes HernandezAún no hay calificaciones
- Trabajo de Investigación 2Documento9 páginasTrabajo de Investigación 2Manuel LantiguaAún no hay calificaciones
- Trinidad Keyla Ensayo..Documento19 páginasTrinidad Keyla Ensayo..danielasoberano46Aún no hay calificaciones
- Parcial #1 Econometria I 2.0Documento12 páginasParcial #1 Econometria I 2.0pruebaAún no hay calificaciones
- Probab I LidaDocumento23 páginasProbab I LidaJavier TorresAún no hay calificaciones
- CLASIFICACIONDocumento33 páginasCLASIFICACIONMIGUEL ANGEL CERVANTES BULEJEAún no hay calificaciones
- Glosario Segundo Parcial Estadistica IIDocumento6 páginasGlosario Segundo Parcial Estadistica IIIRIS JOSSELYN ESCOBAR MORALES IRIS JOSSELYN ESCOBAR MORALESAún no hay calificaciones
- Práctica Prueba de Hipótesis. 2019-0251, 0335, 0025Documento8 páginasPráctica Prueba de Hipótesis. 2019-0251, 0335, 0025jimenezscarlen12Aún no hay calificaciones
- Practica Iii Dis. de ExperimentosDocumento11 páginasPractica Iii Dis. de Experimentosjimenezscarlen12Aún no hay calificaciones
- Actividad 1 InvestigaciónDocumento15 páginasActividad 1 Investigaciónjimenezscarlen12Aún no hay calificaciones
- Examen Práctica - Mediciones VectoresDocumento8 páginasExamen Práctica - Mediciones Vectoresjimenezscarlen12Aún no hay calificaciones
- Brasil y México: Regímenes Duales en Transición Divergente: Carlos Barba Solano y Enrique Valencia LomelíDocumento51 páginasBrasil y México: Regímenes Duales en Transición Divergente: Carlos Barba Solano y Enrique Valencia Lomelíalondra.marquez2115Aún no hay calificaciones
- Ética UtpDocumento5 páginasÉtica UtpOscar Espejo LanzaraAún no hay calificaciones
- Examen Final Logico Matemática (1) Cecilia Velez LaraDocumento6 páginasExamen Final Logico Matemática (1) Cecilia Velez LaraBrigith BebaAún no hay calificaciones
- Fase 1 - CuestionarioDocumento3 páginasFase 1 - CuestionarioJaider Coronel Rojas0% (1)
- SAGA CRONICAS LUNARES - Stars Above - 0.8. La MecánicaDocumento4 páginasSAGA CRONICAS LUNARES - Stars Above - 0.8. La MecánicaMartínez Mayerlin100% (1)
- Informe N°3Documento10 páginasInforme N°3Andre Becerra CancinoAún no hay calificaciones
- Cesar Vallejo LiberaciónDocumento23 páginasCesar Vallejo LiberaciónycarpioguAún no hay calificaciones
- Laboratorio 6Documento12 páginasLaboratorio 6kathia jaenAún no hay calificaciones
- Reporte 9 BioDocumento19 páginasReporte 9 BioJennifer Elizabeth Maldonado MataAún no hay calificaciones
- Jakobson, Roman - Lingüística y PoéticaDocumento29 páginasJakobson, Roman - Lingüística y Poéticaapi-26172668100% (8)
- Componentes de La Prótesis Removible ExpoDocumento78 páginasComponentes de La Prótesis Removible ExpoAdrianAnChav100% (2)
- Reseña Crítica Del Capítulo 1-El Sector Público en Una Economía Mixta.Documento2 páginasReseña Crítica Del Capítulo 1-El Sector Público en Una Economía Mixta.HazielAún no hay calificaciones
- APARATO RESPIRATORIO - Fosas NasalesDocumento49 páginasAPARATO RESPIRATORIO - Fosas NasalesJuanca PradoAún no hay calificaciones
- Curriculum Vitae Dr. Juan Francisco CabelloDocumento3 páginasCurriculum Vitae Dr. Juan Francisco Cabellojuan carlosAún no hay calificaciones
- Agentes AntimicrobianosDocumento6 páginasAgentes AntimicrobianosemilyAún no hay calificaciones
- BrucelosisDocumento31 páginasBrucelosismichell rodriguezAún no hay calificaciones
- NavidadDocumento27 páginasNavidadANGELA TEJADAAún no hay calificaciones
- La Planificacion Estrategica (Electiva)Documento3 páginasLa Planificacion Estrategica (Electiva)Maria Jose lopezAún no hay calificaciones
- Folletos y Practicas Por Tema - Prácticas - Matrices Sistemas DeterminantesDocumento43 páginasFolletos y Practicas Por Tema - Prácticas - Matrices Sistemas DeterminantesRafael SalazarAún no hay calificaciones
- Libros para Leer en Casa PDFDocumento9 páginasLibros para Leer en Casa PDFDanielaAún no hay calificaciones
- Reporte Práctica Presión HidrostáticaDocumento6 páginasReporte Práctica Presión Hidrostáticamagdalena100% (1)