También podría gustarte
- Aprende a Desarrollar con Spring FrameworkDe EverandAprende a Desarrollar con Spring FrameworkCalificación: 3 de 5 estrellas3/5 (1)
- + Pentesting A Nivel Perimetral +Documento23 páginas+ Pentesting A Nivel Perimetral +Brian GarateAún no hay calificaciones
- Programación Java - Una Guía para Principiantes para Aprender Java Paso a PasoDe EverandProgramación Java - Una Guía para Principiantes para Aprender Java Paso a PasoCalificación: 3 de 5 estrellas3/5 (7)
- Introducción A Spring Boot Aplicación Web Con Servicios REST y Spring Data JPADocumento26 páginasIntroducción A Spring Boot Aplicación Web Con Servicios REST y Spring Data JPARafaVlack Barrientos HolderAún no hay calificaciones
- Diccionario de CompetenciasDocumento12 páginasDiccionario de CompetenciasSilvana ValentinAún no hay calificaciones
- Inyección SQL Con SqlmapDocumento13 páginasInyección SQL Con SqlmapAhida Ospina MendozaAún no hay calificaciones
- Prueba Mecánicos E11 y d6Documento17 páginasPrueba Mecánicos E11 y d6leonardo acostaAún no hay calificaciones
- Titulos de Credito USACDocumento16 páginasTitulos de Credito USACAlejandro Mendoza100% (1)
- Tutorial CRUD Usando Node JS, Express, React JS y MySQL (Full-Stack)Documento27 páginasTutorial CRUD Usando Node JS, Express, React JS y MySQL (Full-Stack)Rubiela CifuentesAún no hay calificaciones
- ARMAGEDDON (Linux)Documento5 páginasARMAGEDDON (Linux)Mi BahiaAún no hay calificaciones
- Paper Metasploitable3 Practice LabsDocumento23 páginasPaper Metasploitable3 Practice LabsAndres MartinezAún no hay calificaciones
- 02 - ThD3 - Pentesting Con Kali 2021.2Documento36 páginas02 - ThD3 - Pentesting Con Kali 2021.2cristian solarte100% (1)
- Angular Typescript PDFDocumento250 páginasAngular Typescript PDFGerardo MartinezAún no hay calificaciones
- Cronograma de Obra - Multifamiliar Andrea PDFDocumento1 páginaCronograma de Obra - Multifamiliar Andrea PDFKaren Moreno SánchezAún no hay calificaciones
- Desarrollo Rápido de Aplicaciones Web. 2ª EdiciónDe EverandDesarrollo Rápido de Aplicaciones Web. 2ª EdiciónAún no hay calificaciones
- RubertduckiDocumento10 páginasRubertduckiEdwin RamírezAún no hay calificaciones
- Nodejs - Express - Manejo de EstadoDocumento5 páginasNodejs - Express - Manejo de EstadootakunAún no hay calificaciones
- DocumenyguyftDocumento18 páginasDocumenyguyftHelen OtisAún no hay calificaciones
- Forma A Ssy6102Documento20 páginasForma A Ssy6102Alexander LambrechtAún no hay calificaciones
- Desarrollo Seguro Caso Practico Ruth Lopez PDFDocumento18 páginasDesarrollo Seguro Caso Practico Ruth Lopez PDFXlemMarioAún no hay calificaciones
- TR2-Azure-Christian Adrian Diaz GarciaDocumento16 páginasTR2-Azure-Christian Adrian Diaz Garciamatecomu314Aún no hay calificaciones
- Desencriptar Password WeblogicDocumento3 páginasDesencriptar Password WeblogicDavid Díaz100% (1)
- Tutorial API REST Con Python y FlaskDocumento8 páginasTutorial API REST Con Python y FlaskEmmanuel RodriguezAún no hay calificaciones
- Nodejs - Express - Bootstrap: RecursosDocumento3 páginasNodejs - Express - Bootstrap: RecursosotakunAún no hay calificaciones
- Monemto 3Documento22 páginasMonemto 3Uriel Garzon SanchezAún no hay calificaciones
- RmiDocumento6 páginasRmiqqccfaceAún no hay calificaciones
- Ejercicio 3.1 SoluciónDocumento24 páginasEjercicio 3.1 SoluciónDaniel Roman CarrilloAún no hay calificaciones
- Uso ModsecurityDocumento7 páginasUso ModsecurityAneudy Hernandez PeñaAún no hay calificaciones
- Django PythonDocumento2 páginasDjango PythonJavi JavierAún no hay calificaciones
- Laboratorio WAFDocumento6 páginasLaboratorio WAFWilmer EspinosaAún no hay calificaciones
- Taller Final Evaluación de SistemasDocumento19 páginasTaller Final Evaluación de SistemasMarco Silva SegoviaAún no hay calificaciones
- Documentacion SwarmDocumento8 páginasDocumentacion SwarmJorge Luis Villavicencio MezaAún no hay calificaciones
- Documentacion de La Aplicacion Rmi-MysqlDocumento20 páginasDocumentacion de La Aplicacion Rmi-MysqlZeivier Contreras100% (1)
- Ejercicio GuiadoDocumento5 páginasEjercicio GuiadoBenjaminAún no hay calificaciones
- HCK CfiDocumento32 páginasHCK CfialfredobslAún no hay calificaciones
- TPRG17 Miiisii S03 Ej01Documento3 páginasTPRG17 Miiisii S03 Ej01Emanuel morenoAún no hay calificaciones
- Comando de La Semana 4 GOLISMERO - 1Documento14 páginasComando de La Semana 4 GOLISMERO - 1Luis Alejandro Cáceres FaúndezAún no hay calificaciones
- Driver CTDDocumento5 páginasDriver CTDcarlosAún no hay calificaciones
- DR Edwin Ivan Farro PacificoDocumento43 páginasDR Edwin Ivan Farro PacificoGia CernaAún no hay calificaciones
- Manual de MVC: (1) Frontcontroller: Entendiendo El Patrón Arquitectónico Modelo-Vista-ControladorDocumento8 páginasManual de MVC: (1) Frontcontroller: Entendiendo El Patrón Arquitectónico Modelo-Vista-ControladorJhonny Jose Arana NievesAún no hay calificaciones
- Tutorial Sencillo Yii FrameworkDocumento8 páginasTutorial Sencillo Yii FrameworkJorge Andrés Fuentes ZambranoAún no hay calificaciones
- Requisitos de Los Escenarios para Realización de Las PrácticasDocumento5 páginasRequisitos de Los Escenarios para Realización de Las PrácticasMiguel GlezAún no hay calificaciones
- Musi 010 T 2 Trab 2Documento8 páginasMusi 010 T 2 Trab 2Jorge LopezAún no hay calificaciones
- Entregable 1 Anggelo PozoDocumento15 páginasEntregable 1 Anggelo PozoFaker :DAún no hay calificaciones
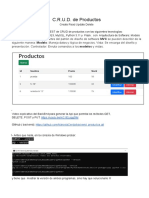
- CRUD de Productos y Servicios en Django AdminDocumento13 páginasCRUD de Productos y Servicios en Django AdminAgustin FleitasAún no hay calificaciones
- Apache Derby Servidor BBDDDocumento6 páginasApache Derby Servidor BBDDArturo MotaAún no hay calificaciones
- P5. 2023-01 ClusterHadoop - AplicacionDocumento13 páginasP5. 2023-01 ClusterHadoop - AplicacionGerson Yarce FrancoAún no hay calificaciones
- Uso ModsecurityDocumento6 páginasUso ModsecurityXavi LunaAún no hay calificaciones
- Ejemplo de Lectura BD ScalaDocumento3 páginasEjemplo de Lectura BD ScalaIlán Antoni Horna GomezAún no hay calificaciones
- Codigos Desarrollo WebDocumento8 páginasCodigos Desarrollo WebLucenith MejiaAún no hay calificaciones
- InformeDocumento11 páginasInformeJonathan SolisAún no hay calificaciones
- HACKING ETICO 32.1practica-14-Clase-PublicaDocumento11 páginasHACKING ETICO 32.1practica-14-Clase-PublicaTeressa Michelen100% (1)
- 6.2.7 Lab - Build A Sample Web App in A Docker Container - Es XLDocumento12 páginas6.2.7 Lab - Build A Sample Web App in A Docker Container - Es XLJuan Carlos Moreno HenaoAún no hay calificaciones
- Analisis Maze RansomwareDocumento14 páginasAnalisis Maze RansomwareSeba FloresAún no hay calificaciones
- Mexmasi 09 T 2 Trab 2Documento8 páginasMexmasi 09 T 2 Trab 2darkness51250% (1)
- Padin Devesa-Perez RodriguezDocumento3 páginasPadin Devesa-Perez RodriguezPablo Pérez RodríguezAún no hay calificaciones
- Integración Zimbra v1.0Documento3 páginasIntegración Zimbra v1.0Dinkar Rios MacedoAún no hay calificaciones
- TomcatDocumento10 páginasTomcatCristhianAún no hay calificaciones
- 22 Práctica Docker Compose Mean StackDocumento12 páginas22 Práctica Docker Compose Mean StackBrando Jahir Toma la VincesAún no hay calificaciones
- Manual Ténico - CXR Covid DetectorDocumento9 páginasManual Ténico - CXR Covid DetectorFelipe Buitrago CarmonaAún no hay calificaciones
- Consumir Un Web Service NuSOAP en Android Usando KSOAP2Documento3 páginasConsumir Un Web Service NuSOAP en Android Usando KSOAP2César Cuauhtémoc Salazar GonzálezAún no hay calificaciones
- Ejemplo 01 Registro de Datos Con Java en PostgresDocumento3 páginasEjemplo 01 Registro de Datos Con Java en PostgresEswin Valiente ObandoAún no hay calificaciones
- Caso 500Documento15 páginasCaso 500Alexander Ale Vilcape33% (3)
- REGALIASDocumento67 páginasREGALIASJulian Morales VargasAún no hay calificaciones
- Derecho Penal AduaneroDocumento26 páginasDerecho Penal AduaneroCristalita Miranda100% (1)
- Desinstalacion Cliente OSCE 10 - XDocumento15 páginasDesinstalacion Cliente OSCE 10 - XJimmy Washington Ortega RodriguezAún no hay calificaciones
- DEMUNA Ministerio EconomiaDocumento28 páginasDEMUNA Ministerio EconomiaguillebentuAún no hay calificaciones
- Presentacion Mte 2017Documento20 páginasPresentacion Mte 2017dianischAún no hay calificaciones
- Ensayo ReiDocumento3 páginasEnsayo ReiGALO FERNANDO GUANOCHANGA MOROCHOAún no hay calificaciones
- Practica 5 ScilabDocumento10 páginasPractica 5 ScilabDaniel MirelesAún no hay calificaciones
- Tipos de Señales en Control de ProcesosDocumento14 páginasTipos de Señales en Control de ProcesosPedro Nuñez RamirezAún no hay calificaciones
- Sílabo - Competencias-FORMATODocumento5 páginasSílabo - Competencias-FORMATOEDWARD MEDINAAún no hay calificaciones
- Criba de EratóstenesDocumento4 páginasCriba de EratóstenesgdsdfgsfahsfhAún no hay calificaciones
- Plan de ActividadesDocumento4 páginasPlan de ActividadesEstefany UgazAún no hay calificaciones
- Unidad 6-SUCESIONES-Y-CUENTA-PARTICIONARIA-Y-OTROS1Documento29 páginasUnidad 6-SUCESIONES-Y-CUENTA-PARTICIONARIA-Y-OTROS1Luuli DiambraAún no hay calificaciones
- Diagrama de Fusibles Ford Serie E E-150Documento6 páginasDiagrama de Fusibles Ford Serie E E-150EDUARDo GILAún no hay calificaciones
- Tesis Zona Francas PDFDocumento127 páginasTesis Zona Francas PDFJaime Santos0% (2)
- RRHH Declaracion Drogas FuncionariosDocumento3 páginasRRHH Declaracion Drogas FuncionariosjaramilloAún no hay calificaciones
- Res 2021006440191921000880632Documento10 páginasRes 2021006440191921000880632Yoshio Muñoz HamasakiAún no hay calificaciones
- ProcessingDocumento94 páginasProcessingkassan4791Aún no hay calificaciones
- Recursos Que Se Deben Cuidar en El EcuadorDocumento4 páginasRecursos Que Se Deben Cuidar en El EcuadorIndustrial actAún no hay calificaciones
- Métodos Alternativos No Podrá Ser Divulgada, Por Lo Que Será Intransferible eDocumento9 páginasMétodos Alternativos No Podrá Ser Divulgada, Por Lo Que Será Intransferible eFernando ArroyoAún no hay calificaciones
- Solucion de Ejercicio de Cifrado HillDocumento3 páginasSolucion de Ejercicio de Cifrado HillIvan Felipe ReinaAún no hay calificaciones
- Evaluacion Diagnostico Taller de Obras de Edificacion e InfraestructurasDocumento5 páginasEvaluacion Diagnostico Taller de Obras de Edificacion e InfraestructurasErwin Enrique saravia palmaAún no hay calificaciones
- Ojs - Revista ElectronicaDocumento14 páginasOjs - Revista ElectronicaJorge Isaac ZeballosAún no hay calificaciones
- Ficha Técnica BMW 330i 2021Documento2 páginasFicha Técnica BMW 330i 2021Cay MartínezAún no hay calificaciones
- Designan A Jorge Arguello Como Embajador de Estados UnidosDocumento2 páginasDesignan A Jorge Arguello Como Embajador de Estados UnidosCrónicaAún no hay calificaciones
- 2.1 - Actividad 2.1 Foro de DiscusiónDocumento2 páginas2.1 - Actividad 2.1 Foro de Discusiónjose merinoAún no hay calificaciones