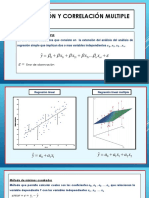
También podría gustarte
- 2 RegLMulDocumento21 páginas2 RegLMulManuel De Jesús Salas Salas50% (2)
- Regresion y Correlacion Lineal MultipleDocumento110 páginasRegresion y Correlacion Lineal MultipleWilliams Ramos SalgueroAún no hay calificaciones
- Ecuaciones Diferenciales Capítulo IIDocumento64 páginasEcuaciones Diferenciales Capítulo IIReene CorttezAún no hay calificaciones
- Ecuaciones Diferenciales (Ejercicios 1.1)Documento7 páginasEcuaciones Diferenciales (Ejercicios 1.1)maynorAún no hay calificaciones
- Ejercicios Soluciones Original MasterDocumento95 páginasEjercicios Soluciones Original Masteraurelio.fdezAún no hay calificaciones
- Regresión Lineal MultipleDocumento29 páginasRegresión Lineal MultiplejaiderAún no hay calificaciones
- Teoría de Los Mundos ParalelosDocumento11 páginasTeoría de Los Mundos ParalelosSteven MuñozAún no hay calificaciones
- Ejemplo de Cómo Realizar Una Prueba de Hipótesis BásicaDocumento7 páginasEjemplo de Cómo Realizar Una Prueba de Hipótesis BásicaCarlosAún no hay calificaciones
- t2 100402 116Documento9 páginast2 100402 116rupestrearth33% (3)
- Regresion Multiple-Estimación 2022 1Documento12 páginasRegresion Multiple-Estimación 2022 1Dannis Omar Campos ZavaletaAún no hay calificaciones
- Reresion Lineal Multiple MDDocumento12 páginasReresion Lineal Multiple MDNelyda Ayde CondoriAún no hay calificaciones
- FinalDocumento14 páginasFinalHugo JaraAún no hay calificaciones
- Documento deDocumento14 páginasDocumento deHugo JaraAún no hay calificaciones
- Modelo Lineal GeneralDocumento16 páginasModelo Lineal GeneralcesarcalleAún no hay calificaciones
- REGRESION MULTILINEAlDocumento8 páginasREGRESION MULTILINEAlManuel CornejoAún no hay calificaciones
- Especificación Del ModeloDocumento4 páginasEspecificación Del ModeloIago Fole CortegosoAún no hay calificaciones
- Ayudantía N°1 (Segundo Semestre 2014)Documento7 páginasAyudantía N°1 (Segundo Semestre 2014)David AhumadaAún no hay calificaciones
- Tema 4Documento21 páginasTema 4MauricioAún no hay calificaciones
- Regresion Lineal MultipleDocumento16 páginasRegresion Lineal MultipleMatias Varas AlarconAún no hay calificaciones
- Apoyo 2Documento5 páginasApoyo 2Damaris Priscila MamaniAún no hay calificaciones
- Unidad 1 - BibliografíaDocumento12 páginasUnidad 1 - BibliografíaSebastian AlvarezAún no hay calificaciones
- Lección 2 Modelo de Regresion MultipleDocumento48 páginasLección 2 Modelo de Regresion Multiple- Daniel Von Zedlitz -Aún no hay calificaciones
- Modelos de Regresión Lineal-Variables Ficticias - 1Documento36 páginasModelos de Regresión Lineal-Variables Ficticias - 1David BobadillaAún no hay calificaciones
- Regresión MúltipleDocumento25 páginasRegresión MúltipleDaryl De Valière-Reyes Y HabsburgoAún no hay calificaciones
- Tema 2 - Econ 1Documento23 páginasTema 2 - Econ 1Santiago TorricoAún no hay calificaciones
- Regresion Lineal MultipleDocumento37 páginasRegresion Lineal MultipleEldo Agustin BaumannAún no hay calificaciones
- 5 - Modelo Lineal GeneralDocumento22 páginas5 - Modelo Lineal GeneralARIEL FUENTES FORONDAAún no hay calificaciones
- Funciones Especiales CDocumento10 páginasFunciones Especiales Cjf.vilaAún no hay calificaciones
- Estadística AplicadaDocumento4 páginasEstadística AplicadaCarlos Rincón100% (1)
- Analisis Regresion MultipleDocumento23 páginasAnalisis Regresion MultipleANDRE RENATO VALENTIN FRANCO CORTEZAún no hay calificaciones
- Unidad #5 Regresión y CorrelaciónDocumento25 páginasUnidad #5 Regresión y CorrelaciónJORGE FREJA MACIASAún no hay calificaciones
- 03 VAEIE Inferencia Estadística PDFDocumento71 páginas03 VAEIE Inferencia Estadística PDFVictor HernandezAún no hay calificaciones
- Tabla Ede Datos TunaDocumento19 páginasTabla Ede Datos TunaJulio Coronado AguirreAún no hay calificaciones
- Análisis de VolátilesDocumento52 páginasAnálisis de VolátilesJosimar PasquelAún no hay calificaciones
- Regresion y CorrelacionDocumento52 páginasRegresion y CorrelacionAnonymous 8GWv4y0qjEAún no hay calificaciones
- DiapositivasRegresión (Samuel2012)Documento40 páginasDiapositivasRegresión (Samuel2012)SktSlayerAún no hay calificaciones
- (Compilado Omitiendo Errores) PDFDocumento14 páginas(Compilado Omitiendo Errores) PDFKylie PayneAún no hay calificaciones
- Trabajo 3 Metodos NumericosDocumento3 páginasTrabajo 3 Metodos NumericosOscar CopzAún no hay calificaciones
- Ecuaciones Diferenciales Por Separación de VariablesDocumento5 páginasEcuaciones Diferenciales Por Separación de VariablesEdson HuanachinAún no hay calificaciones
- Regresiòn Multiple AlumnosDocumento38 páginasRegresiòn Multiple AlumnosAbner PerezsorianoAún no hay calificaciones
- Resumen de Ecuaciones DiferencialesDocumento28 páginasResumen de Ecuaciones Diferencialesproduc cion 1Aún no hay calificaciones
- Wuolah Free Examen Espacio Afin CorregidoDocumento7 páginasWuolah Free Examen Espacio Afin CorregidoachrafelalimiAún no hay calificaciones
- Apuntes Ecuaciones Diferenciales TEMA 1Documento45 páginasApuntes Ecuaciones Diferenciales TEMA 1uzielv48Aún no hay calificaciones
- Chi CuadradoDocumento40 páginasChi CuadradoKevin P RuizAún no hay calificaciones
- EconometriaDocumento32 páginasEconometriaSandrita RamosAún no hay calificaciones
- Resolución de Los Ejercicios Del Makarenko 1.1Documento67 páginasResolución de Los Ejercicios Del Makarenko 1.1oscarAún no hay calificaciones
- VarianzaDocumento4 páginasVarianzaSara DiSuAún no hay calificaciones
- Unidad 1 - Distribuciones MuestralesDocumento4 páginasUnidad 1 - Distribuciones MuestralesDavid VivasAún no hay calificaciones
- CONICASDocumento4 páginasCONICASValentina GonzálezAún no hay calificaciones
- BesselDocumento35 páginasBesselBarbara LarreaAún no hay calificaciones
- Aplicaciones de La Chi-CuadradoDocumento38 páginasAplicaciones de La Chi-CuadradoJavier PumaAún no hay calificaciones
- Matrices GaussianasDocumento19 páginasMatrices Gaussianas58aee0836f3d5Aún no hay calificaciones
- Clase Econometría en FIUBADocumento56 páginasClase Econometría en FIUBAAgustin CrocciAún no hay calificaciones
- 3era ActividadDocumento6 páginas3era ActividadnakassyAún no hay calificaciones
- Tema 1Documento42 páginasTema 1angelo Ruiz100% (1)
- Tema 3Documento22 páginasTema 3Marc Pastor PouAún no hay calificaciones
- Correlacion y Regresion Multiple 01 S15Documento32 páginasCorrelacion y Regresion Multiple 01 S15DIANA CAMILA FERNANDEZ MEDINAAún no hay calificaciones
- D Distrib Normal FGM Media VarianzaDocumento7 páginasD Distrib Normal FGM Media Varianzadiegomonti247Aún no hay calificaciones
- Conometríai: Tema 3: Modelo de Regresión Lineal MúltipleDocumento6 páginasConometríai: Tema 3: Modelo de Regresión Lineal MúltipleMaider Perea ValienteAún no hay calificaciones
- Diseño Completo Al AzarDocumento12 páginasDiseño Completo Al Azardilmer salcedo malcaAún no hay calificaciones
- Circular 03341 Cronograma Visitas FSE Octubre 2023Documento3 páginasCircular 03341 Cronograma Visitas FSE Octubre 2023Manuel Esteban LermaAún no hay calificaciones
- Circular 02124 Capacitacion Industria y ComercioDocumento1 páginaCircular 02124 Capacitacion Industria y ComercioManuel Esteban LermaAún no hay calificaciones
- Circular 4143.020.22.2.1020.004082 Cumplimiento Resolucion N°172 de Junio 13 de 2023 - 0001Documento6 páginasCircular 4143.020.22.2.1020.004082 Cumplimiento Resolucion N°172 de Junio 13 de 2023 - 0001Manuel Esteban LermaAún no hay calificaciones
- Res - 000162 de 31-10-2023 - Pág - 1 - 92 - 2024Documento92 páginasRes - 000162 de 31-10-2023 - Pág - 1 - 92 - 2024Manuel Esteban LermaAún no hay calificaciones
- Cascada Pptal Ejecucion MensualDocumento2 páginasCascada Pptal Ejecucion MensualManuel Esteban LermaAún no hay calificaciones
- Proyecto Circular Externa Obligatoriedad Secopii 2023 Rev. DG FDocumento13 páginasProyecto Circular Externa Obligatoriedad Secopii 2023 Rev. DG FManuel Esteban LermaAún no hay calificaciones
- Orfeo 9624 Actualizacion Politicas ContablesDocumento4 páginasOrfeo 9624 Actualizacion Politicas ContablesManuel Esteban LermaAún no hay calificaciones
- Regresión Lineal Simple PDFDocumento35 páginasRegresión Lineal Simple PDFManuel Esteban LermaAún no hay calificaciones
- Econometria FinancieraDocumento3 páginasEconometria FinancieraManuel Esteban LermaAún no hay calificaciones
- Leccion 2Documento5 páginasLeccion 2Erlin EspinalAún no hay calificaciones
- Foro 3.3Documento9 páginasForo 3.3Patricia SilvaAún no hay calificaciones
- Tema 9Documento7 páginasTema 9Shariff AspilcuetaAún no hay calificaciones
- Manual Cooper SmithDocumento14 páginasManual Cooper SmithJulia RiveraAún no hay calificaciones
- Bondad de AjusteDocumento6 páginasBondad de AjusteAndres Felipe Calvo LozanoAún no hay calificaciones
- Modelos AtomicosDocumento2 páginasModelos AtomicosMario SebAún no hay calificaciones
- Taller 11Documento9 páginasTaller 11fatimaAún no hay calificaciones
- Artículo FinalDocumento8 páginasArtículo FinalEduardo AlvarengaAún no hay calificaciones
- Quimica Grado 10 SupletorioDocumento2 páginasQuimica Grado 10 SupletorioCarlos berrios CanalAún no hay calificaciones
- Lab Grupo6Documento7 páginasLab Grupo6HENRY GUSTAVO JAPAY LIÑANAún no hay calificaciones
- Dca Tipos de CalzadoDocumento12 páginasDca Tipos de CalzadoHenryPilatasigAún no hay calificaciones
- Fórmulas Talleres Estadística IiDocumento2 páginasFórmulas Talleres Estadística IikeliAún no hay calificaciones
- Cuadro Comparativo Tema 2Documento5 páginasCuadro Comparativo Tema 2shareni romoAún no hay calificaciones
- DiracDocumento36 páginasDiracOrlando DunstAún no hay calificaciones
- Taller 2 Experimentos Con Un Solo FactorDocumento9 páginasTaller 2 Experimentos Con Un Solo FactorClaudia TorresAún no hay calificaciones
- Densidad TeoricaDocumento7 páginasDensidad Teoricatoniza69Aún no hay calificaciones
- Comparar Los Niveles de Estrés Positivo Según La Situación LaboralDocumento3 páginasComparar Los Niveles de Estrés Positivo Según La Situación LaboralL Marcelo Marticorena AquijeAún no hay calificaciones
- Modelos Teóricos de Distribuciones de ProbabilidadDocumento28 páginasModelos Teóricos de Distribuciones de ProbabilidadjuanAún no hay calificaciones
- Ova Sem 13 Analisis de Varianza de Un Solo FactorDocumento9 páginasOva Sem 13 Analisis de Varianza de Un Solo FactorCarlos Oroya OjedaAún no hay calificaciones
- Guia N°1 Inferencia.Documento4 páginasGuia N°1 Inferencia.Chris VegaAún no hay calificaciones
- Quinta Clase de Estadistica IIUNAC2022DEFINITIVADocumento82 páginasQuinta Clase de Estadistica IIUNAC2022DEFINITIVANativa Cevichería RestobarAún no hay calificaciones
- LUNA - JIMENEZ - OSCAR - URIEL - RES342 - Entregable 1Documento6 páginasLUNA - JIMENEZ - OSCAR - URIEL - RES342 - Entregable 1Oscar LunaAún no hay calificaciones
- Taller Pronósticos Regresión LinealDocumento5 páginasTaller Pronósticos Regresión LinealHector Daniel VACA TORRESAún no hay calificaciones
- 1.3.1 CausalidadDocumento6 páginas1.3.1 CausalidadCesar Manuel Caamal PatAún no hay calificaciones
- Perfil de Proyecto y TesisDocumento3 páginasPerfil de Proyecto y TesisCarlos Alberto Fonseca DaviránAún no hay calificaciones
- BARTON ZWIEBACH BiografiaDocumento176 páginasBARTON ZWIEBACH BiografiaMiguel Salazar ヅAún no hay calificaciones
- Clau ESTADISTICA ResueltoDocumento7 páginasClau ESTADISTICA ResueltoRuben CastilloAún no hay calificaciones