También podría gustarte
- RacaSAFIQpmnGkgBSMKZAQ TFinalDocumento8 páginasRacaSAFIQpmnGkgBSMKZAQ TFinalSamuel BarcenasAún no hay calificaciones
- Guía de Manejo de Rstudio 2021Documento3 páginasGuía de Manejo de Rstudio 2021Miguel SalasAún no hay calificaciones
- ASGBD Proves LliuresDocumento6 páginasASGBD Proves LliuresAmelia HermidaAún no hay calificaciones
- Taller Data ScienceDocumento15 páginasTaller Data ScienceHarrison QUINTERO CAICEDOAún no hay calificaciones
- DatawinDocumento9 páginasDatawinroyandersoAún no hay calificaciones
- Actd Taller11Documento5 páginasActd Taller11NAún no hay calificaciones
- Examen Bases de DatosDocumento13 páginasExamen Bases de DatosjuanurielmeAún no hay calificaciones
- Actividades Estructura de Datos JavaDocumento5 páginasActividades Estructura de Datos Javagosma3379Aún no hay calificaciones
- Datamine Studio 2Documento57 páginasDatamine Studio 2Jeson CGAún no hay calificaciones
- Lab 1Documento10 páginasLab 1Victor HenostrozaAún no hay calificaciones
- Guia de TP BDA - 2012Documento22 páginasGuia de TP BDA - 2012Jokerwin09Aún no hay calificaciones
- KaggleDocumento9 páginasKaggleAndrès SantacruzAún no hay calificaciones
- Final 2022-2Documento4 páginasFinal 2022-2Michin BoteroAún no hay calificaciones
- Notas de ClaseDocumento32 páginasNotas de ClasejdmarinAún no hay calificaciones
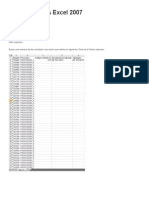
- Autofill en VBA Excel 2007Documento2 páginasAutofill en VBA Excel 2007pariciotomasAún no hay calificaciones
- Programacion ParalelaDocumento7 páginasProgramacion ParalelaCristian MartinezAún no hay calificaciones
- Enunciado Ejercicios MIPS 1Documento4 páginasEnunciado Ejercicios MIPS 1Fabiola JaldinAún no hay calificaciones
- Examen Suficiencia COMP IIDocumento4 páginasExamen Suficiencia COMP IIOmar CarbajalAún no hay calificaciones
- Tercer Parcial Compu2 Ing UcDocumento2 páginasTercer Parcial Compu2 Ing UcAlejandroAún no hay calificaciones
- Examenes SupletoriosDocumento8 páginasExamenes SupletoriosMauro AlfredoAún no hay calificaciones
- AD Nov 22-23 - Carballo Alonso Alejandro - Enunciado-1Documento2 páginasAD Nov 22-23 - Carballo Alonso Alejandro - Enunciado-1Alex CarballoAún no hay calificaciones
- N8 HT2 MundialDocumento4 páginasN8 HT2 MundialA Que No Adivinan Quieen ???Aún no hay calificaciones
- L06 Macros Nivel BásicoDocumento17 páginasL06 Macros Nivel BásicoJhon Jhampieer Gil HuamaniAún no hay calificaciones
- Bases de Datos Usando DAODocumento22 páginasBases de Datos Usando DAOOrley PalmaAún no hay calificaciones
- 4GL 07 Enunciado TareaDocumento3 páginas4GL 07 Enunciado TareaCenj UroAún no hay calificaciones
- 0010 - SEM6 - ActividadDocumento7 páginas0010 - SEM6 - ActividadSamuel BarcenasAún no hay calificaciones
- Desafío - Primera VisualizaciónDocumento4 páginasDesafío - Primera Visualizaciónguillermo schadeAún no hay calificaciones
- Examen 3E - 2T-2017 v1Documento4 páginasExamen 3E - 2T-2017 v1Cusco LibrosAún no hay calificaciones
- EXAMEN 1ER, 2do Y 3ER PARCIAL A BASE DATOS 2016 FINAL1Documento7 páginasEXAMEN 1ER, 2do Y 3ER PARCIAL A BASE DATOS 2016 FINAL1Ernestoo AdrianooAún no hay calificaciones
- DudlerDocumento6 páginasDudlerDudler Gonzales HolgadoAún no hay calificaciones
- Prueba Tecnica DataKnow PDFDocumento3 páginasPrueba Tecnica DataKnow PDFPipe LeivaAún no hay calificaciones
- Practica C++ Nro 2Documento6 páginasPractica C++ Nro 2carlosclariAún no hay calificaciones
- Ejercicios Tema 2Documento2 páginasEjercicios Tema 2xicenAún no hay calificaciones
- Arquitectura de Aplicaciones Java EXAMEN 01 2Documento3 páginasArquitectura de Aplicaciones Java EXAMEN 01 2Melisa ZagaAún no hay calificaciones
- Recuperación Práctica en RDocumento4 páginasRecuperación Práctica en RSebas VillaAún no hay calificaciones
- Alu FinalDocumento22 páginasAlu FinalDavid Juarez MagañaAún no hay calificaciones
- L06 Macros Nivel Básico Chipana Machaca Ronald Conclusiones 454Documento17 páginasL06 Macros Nivel Básico Chipana Machaca Ronald Conclusiones 454Frai Wilder Zapana MamaniAún no hay calificaciones
- Examen Suficiencia COMP IIDocumento4 páginasExamen Suficiencia COMP IIOmar Carbajal50% (2)
- R Importacion PDFDocumento6 páginasR Importacion PDFMTTAún no hay calificaciones
- 3 3.1.4.6 Lab - Descriptive Statistics in Python MarkDocumento8 páginas3 3.1.4.6 Lab - Descriptive Statistics in Python MarkmarkAún no hay calificaciones
- 21 EjerciciosRepasoDocumento17 páginas21 EjerciciosRepasoandres leonardo pinto cristanchoAún no hay calificaciones
- Taller Ggplot RstudioDocumento5 páginasTaller Ggplot RstudioMiguel Angel Cosio TabaresAún no hay calificaciones
- Descripcion Del Programa Caja y BigotesDocumento5 páginasDescripcion Del Programa Caja y BigotesJhon OñaAún no hay calificaciones
- Taller Transformacion ETLDocumento2 páginasTaller Transformacion ETLBellumAún no hay calificaciones
- Calcular Dis-Nor-Esta Guardar Archivo ExcelDocumento3 páginasCalcular Dis-Nor-Esta Guardar Archivo ExcelcasaeanAún no hay calificaciones
- c21 1f Miranada Barrientos Anthony Lab6Documento17 páginasc21 1f Miranada Barrientos Anthony Lab6Anthony Miranda AJAún no hay calificaciones
- Examen 3 ADocumento4 páginasExamen 3 AJuan MostaceroAún no hay calificaciones
- Facultades Investigadores Ys EquiposDocumento8 páginasFacultades Investigadores Ys EquiposEfren PullaAún no hay calificaciones
- ESTADÍSTICA DESCRIPTIVA - Documentos de GoogleDocumento7 páginasESTADÍSTICA DESCRIPTIVA - Documentos de GoogleJavier GilAún no hay calificaciones
- Lab4 3Documento4 páginasLab4 3Jose FernandoAún no hay calificaciones
- Creacion de Base de Datos en Access Con Visual BasicDocumento88 páginasCreacion de Base de Datos en Access Con Visual BasicFrancisco VelazquezAún no hay calificaciones
- Ejercicios EDATDocumento13 páginasEjercicios EDATJavierRodriguezAún no hay calificaciones
- Trabajos en ExcelDocumento2 páginasTrabajos en ExcelAndreita MardilaAún no hay calificaciones
- Ejercicios Guiados de Punteros en C++, 6 HojasDocumento6 páginasEjercicios Guiados de Punteros en C++, 6 Hojasjuliocesarmota50% (2)
- CholeskyDocumento6 páginasCholeskyDante1222Aún no hay calificaciones
- Expo Lenguaje C Equipo #1 de MarsDocumento30 páginasExpo Lenguaje C Equipo #1 de MarsZamir Leonardo LozanoAún no hay calificaciones
- 21 EjerciciosRepasoDocumento17 páginas21 EjerciciosRepasoJuliana PalmaAún no hay calificaciones
- Taller 2Documento2 páginasTaller 2Michin BoteroAún no hay calificaciones
- Taller FinalDocumento1 páginaTaller FinalMichin BoteroAún no hay calificaciones
- Quiniela Fixture Copa Mundial Fifa Qatar 2022 Excel para DescargarDocumento17 páginasQuiniela Fixture Copa Mundial Fifa Qatar 2022 Excel para DescargarMichin BoteroAún no hay calificaciones
- Parcial 2022-2Documento3 páginasParcial 2022-2Michin BoteroAún no hay calificaciones
- Final 2022-2Documento4 páginasFinal 2022-2Michin BoteroAún no hay calificaciones
- E.D. de Primer Orden 2022-2 PDFDocumento38 páginasE.D. de Primer Orden 2022-2 PDFMichin BoteroAún no hay calificaciones
- 02 LimitesDocumento2 páginas02 LimitesMichin BoteroAún no hay calificaciones
- Cardinalidad de Base de DatosDocumento3 páginasCardinalidad de Base de DatosANTONY JAHIR ORTIZ ROMEROAún no hay calificaciones
- Tres Formas para Crear Un ShapefileDocumento5 páginasTres Formas para Crear Un ShapefileArmando Rodriguez MontellanoAún no hay calificaciones
- S2-Trabajo Práctico Experimental - 1Documento6 páginasS2-Trabajo Práctico Experimental - 1CésarGmzAún no hay calificaciones
- WA0018jdjekd.Documento9 páginasWA0018jdjekd.Gabriela AriasAún no hay calificaciones
- Diferencias y Similitudes Entre El Modelo Tabular y El MultidimensionalDocumento2 páginasDiferencias y Similitudes Entre El Modelo Tabular y El MultidimensionalLilianaAún no hay calificaciones
- Tarea para BD01Documento5 páginasTarea para BD01Santiago Alejandro Mayoral MataAún no hay calificaciones
- Sistema de IG Tarea 7 Capitulo 6Documento13 páginasSistema de IG Tarea 7 Capitulo 6Dayanara G FalconeAún no hay calificaciones
- Base de DatosDocumento62 páginasBase de DatosMariferLopezAún no hay calificaciones
- Clase 10 PostgisDocumento24 páginasClase 10 PostgisBRAYAN ESTIVEL MAGIN MAMBUSCAYAún no hay calificaciones
- Creación Física BDDocumento5 páginasCreación Física BDosvi00725% (4)
- BD CorregidoDocumento17 páginasBD CorregidoIván DewittAún no hay calificaciones
- Examen Final - Semana 8 - INV - SEGUNDO BLOQUE BDGDDocumento12 páginasExamen Final - Semana 8 - INV - SEGUNDO BLOQUE BDGDRicardo SaenzAún no hay calificaciones
- Examen Diagnostico de Base de DatosDocumento2 páginasExamen Diagnostico de Base de DatosLeticia MendozaAún no hay calificaciones
- Taller#2 1Documento25 páginasTaller#2 1JUAN PABLO OROZCO ROMEROAún no hay calificaciones
- Actividad Semana1Documento4 páginasActividad Semana1Ulises ZeneaAún no hay calificaciones
- Bitácora de Manipulación de Datos Entre Diferentes Motores de Base de DatosDocumento31 páginasBitácora de Manipulación de Datos Entre Diferentes Motores de Base de DatosUsiel PerezAún no hay calificaciones
- Por Si AcasoDocumento11 páginasPor Si AcasoMario MartinezAún no hay calificaciones
- C5 Gestor de Bases de DatosDocumento4 páginasC5 Gestor de Bases de DatosEstefania LópezAún no hay calificaciones
- Documento Sin TítuloDocumento5 páginasDocumento Sin TítuloAlvaro RomeroAún no hay calificaciones
- Guía DataGuard Completa para Dummies (M.C.P.)Documento42 páginasGuía DataGuard Completa para Dummies (M.C.P.)daguasAún no hay calificaciones
- Índices SQL ServerDocumento35 páginasÍndices SQL ServerMiguel Díaz VidarteAún no hay calificaciones
- Ejercicio2 - Generación de Una Maqueta Con Base de DatosDocumento8 páginasEjercicio2 - Generación de Una Maqueta Con Base de DatosRuben CalderonAún no hay calificaciones
- Base de Datos Marino DbaDocumento3 páginasBase de Datos Marino DbaJonathan04 AlmonteAún no hay calificaciones
- Diseño e Implementación de Azure Synapse AnalyticsDocumento3 páginasDiseño e Implementación de Azure Synapse AnalyticsCoin ServiceAún no hay calificaciones
- Base de DatosDocumento20 páginasBase de DatosJairo TivantaAún no hay calificaciones
- Curso Especializado Programación Con PythonDocumento4 páginasCurso Especializado Programación Con PythonElmer CeladitaAún no hay calificaciones
- Objectivo 5 - Crystal ReportsDocumento7 páginasObjectivo 5 - Crystal ReportsTutancamon GarciaAún no hay calificaciones
- Evaluacion Final - Escenario 8 - PRIMER BLOQUE-TEORICO - VIRTUAL - FUNDAMENTOS DE BASES DE DATOS - (GRUPO T01)Documento14 páginasEvaluacion Final - Escenario 8 - PRIMER BLOQUE-TEORICO - VIRTUAL - FUNDAMENTOS DE BASES DE DATOS - (GRUPO T01)Miyer Ferney Cifuentes TunjanoAún no hay calificaciones
- Herramientas para El Desarrollo de Sistemas de InformaciónDocumento41 páginasHerramientas para El Desarrollo de Sistemas de InformaciónRUBEN LUNA GUTIERREZAún no hay calificaciones
- Nomenclatura para La Base de Datos-637677920Documento17 páginasNomenclatura para La Base de Datos-637677920Anonymous 4aXaxLAún no hay calificaciones
- 7 tendencias digitales que cambiarán el mundoDe Everand7 tendencias digitales que cambiarán el mundoCalificación: 4.5 de 5 estrellas4.5/5 (87)
- Guía de cálculo y diseño de conductos para ventilación y climatizaciónDe EverandGuía de cálculo y diseño de conductos para ventilación y climatizaciónCalificación: 5 de 5 estrellas5/5 (1)
- Resumen de El cuadro de mando integral paso a paso de Paul R. NivenDe EverandResumen de El cuadro de mando integral paso a paso de Paul R. NivenCalificación: 5 de 5 estrellas5/5 (2)
- Influencia. La psicología de la persuasiónDe EverandInfluencia. La psicología de la persuasiónCalificación: 4.5 de 5 estrellas4.5/5 (14)
- Clics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaDe EverandClics contra la humanidad: Libertad y resistencia en la era de la distracción tecnológicaCalificación: 4.5 de 5 estrellas4.5/5 (117)
- Excel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másDe EverandExcel para principiantes: Aprenda a utilizar Excel 2016, incluyendo una introducción a fórmulas, funciones, gráficos, cuadros, macros, modelado, informes, estadísticas, Excel Power Query y másCalificación: 2.5 de 5 estrellas2.5/5 (3)
- Lógica de programación: Solucionario en pseudocódigo – Ejercicios resueltosDe EverandLógica de programación: Solucionario en pseudocódigo – Ejercicios resueltosCalificación: 3.5 de 5 estrellas3.5/5 (7)
- ¿Cómo piensan las máquinas?: Inteligencia artificial para humanosDe Everand¿Cómo piensan las máquinas?: Inteligencia artificial para humanosCalificación: 5 de 5 estrellas5/5 (1)
- Excel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteDe EverandExcel y SQL de la mano: Trabajo con bases de datos en Excel de forma eficienteCalificación: 1 de 5 estrellas1/5 (1)
- Excel 2021 y 365 Paso a Paso: Paso a PasoDe EverandExcel 2021 y 365 Paso a Paso: Paso a PasoCalificación: 5 de 5 estrellas5/5 (12)
- UF2246 - Reparación de pequeños electrodomésticos y herramientas eléctricasDe EverandUF2246 - Reparación de pequeños electrodomésticos y herramientas eléctricasCalificación: 2.5 de 5 estrellas2.5/5 (3)
- LAS VELAS JAPONESAS DE UNA FORMA SENCILLA. La guía de introducción a las velas japonesas y a las estrategias de análisis técnico más eficaces.De EverandLAS VELAS JAPONESAS DE UNA FORMA SENCILLA. La guía de introducción a las velas japonesas y a las estrategias de análisis técnico más eficaces.Calificación: 4.5 de 5 estrellas4.5/5 (54)
- EL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.De EverandEL PLAN DE MARKETING EN 4 PASOS. Estrategias y pasos clave para redactar un plan de marketing eficaz.Calificación: 4 de 5 estrellas4/5 (51)
- Design Thinking para principiantes: La innovación como factor para el éxito empresarialDe EverandDesign Thinking para principiantes: La innovación como factor para el éxito empresarialCalificación: 4.5 de 5 estrellas4.5/5 (10)
- El mito de la inteligencia artificial: Por qué las máquinas no pueden pensar como nosotros lo hacemosDe EverandEl mito de la inteligencia artificial: Por qué las máquinas no pueden pensar como nosotros lo hacemosCalificación: 5 de 5 estrellas5/5 (2)
- Inteligencia artificial: Análisis de datos e innovación para principiantesDe EverandInteligencia artificial: Análisis de datos e innovación para principiantesCalificación: 4 de 5 estrellas4/5 (3)
- UF0349: ATENCIÓN AL CLIENTE EN EL PROCESO COMERCIAL (ADGG0208) (ADGD0308)De EverandUF0349: ATENCIÓN AL CLIENTE EN EL PROCESO COMERCIAL (ADGG0208) (ADGD0308)Calificación: 2 de 5 estrellas2/5 (1)
- Machine Learning y Deep Learning: Usando Python, Scikit y KerasDe EverandMachine Learning y Deep Learning: Usando Python, Scikit y KerasAún no hay calificaciones
- Todo Sobre Tecnología Blockchain: La Guía Definitiva Para Principiantes Sobre Monederos BlockchainDe EverandTodo Sobre Tecnología Blockchain: La Guía Definitiva Para Principiantes Sobre Monederos BlockchainAún no hay calificaciones
- Comunicaciones industriales y WinCCDe EverandComunicaciones industriales y WinCCCalificación: 5 de 5 estrellas5/5 (4)
- La psicología del trading de una forma sencilla: Cómo aplicar las estrategias psicológicas y las actitudes de los comerciantes ganadores para operar con éxito en línea.De EverandLa psicología del trading de una forma sencilla: Cómo aplicar las estrategias psicológicas y las actitudes de los comerciantes ganadores para operar con éxito en línea.Calificación: 4.5 de 5 estrellas4.5/5 (3)
- EL PLAN DE NEGOCIOS DE UNA FORMA SENCILLA. La guía práctica que ayuda a poner en marcha nuevos proyectos e ideas empresariales.De EverandEL PLAN DE NEGOCIOS DE UNA FORMA SENCILLA. La guía práctica que ayuda a poner en marcha nuevos proyectos e ideas empresariales.Calificación: 4 de 5 estrellas4/5 (20)
- Curso básico de Python: La guía para principiantes para una introducción en la programación con PythonDe EverandCurso básico de Python: La guía para principiantes para una introducción en la programación con PythonAún no hay calificaciones
- Ciberseguridad: Una Simple Guía para Principiantes sobre Ciberseguridad, Redes Informáticas y Cómo Protegerse del Hacking en Forma de Phishing, Malware, Ransomware e Ingeniería SocialDe EverandCiberseguridad: Una Simple Guía para Principiantes sobre Ciberseguridad, Redes Informáticas y Cómo Protegerse del Hacking en Forma de Phishing, Malware, Ransomware e Ingeniería SocialCalificación: 4.5 de 5 estrellas4.5/5 (11)
- El dilema humano: Del Homo sapiens al Homo techDe EverandEl dilema humano: Del Homo sapiens al Homo techCalificación: 4 de 5 estrellas4/5 (1)
- Manual Técnico del Automóvil - Diccionario Ilustrado de las Nuevas TecnologíasDe EverandManual Técnico del Automóvil - Diccionario Ilustrado de las Nuevas TecnologíasCalificación: 4.5 de 5 estrellas4.5/5 (14)