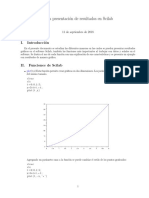
También podría gustarte
- Métodos Matriciales para ingenieros con MATLABDe EverandMétodos Matriciales para ingenieros con MATLABCalificación: 5 de 5 estrellas5/5 (1)
- Capitulo 7Documento15 páginasCapitulo 7violeta molleturo100% (1)
- Ejercicios Cap 1 y 2 MetodosDocumento9 páginasEjercicios Cap 1 y 2 MetodosDavid Gomez TograAún no hay calificaciones
- Ceduvirt Matlab para IngenierosDocumento71 páginasCeduvirt Matlab para IngenierosHemerson Lizarbe AlarcónAún no hay calificaciones
- Otras Tecnicas de Neuroventa InmobiliariaDocumento9 páginasOtras Tecnicas de Neuroventa InmobiliariaDanniel Alberto GuayasAún no hay calificaciones
- La Caída Del Puente SolidaridadDocumento9 páginasLa Caída Del Puente SolidaridadJoseph Alexander100% (1)
- Analisis EconomicoDocumento257 páginasAnalisis EconomicoJuan Eduardo Oyaneder Gutierrez0% (1)
- Informe Gerente PickingDocumento13 páginasInforme Gerente PickingClaudia BgAún no hay calificaciones
- Reconocimiento de Nuestros Saberes DocentesDocumento9 páginasReconocimiento de Nuestros Saberes DocentesMaria Fernanda Muñoz BarruetoAún no hay calificaciones
- Adonais y Otros PoemasDocumento62 páginasAdonais y Otros PoemasItalo Zeballos Leiva100% (3)
- Geometric modeling in computer: Aided geometric designDe EverandGeometric modeling in computer: Aided geometric designAún no hay calificaciones
- Yogurt de KéfirDocumento5 páginasYogurt de KéfirDaniel Gomez Pacheco100% (1)
- Practica 2 para RstudioDocumento3 páginasPractica 2 para RstudioByron Alexis Palazzi SalinasAún no hay calificaciones
- CluDocumento8 páginasCluEdwin Johny Asnate SalazarAún no hay calificaciones
- 4 Luis IncaDocumento26 páginas4 Luis IncaLuis Inca100% (1)
- GUIA DE ESTUDIO No.1 INTRODUCCION A MATLABDocumento19 páginasGUIA DE ESTUDIO No.1 INTRODUCCION A MATLABFundación Salud Siglo 21Aún no hay calificaciones
- ACTIVIDAD DE APRENDIZAJE Practicas de R - Nro1Documento9 páginasACTIVIDAD DE APRENDIZAJE Practicas de R - Nro1Deivid ZambranoAún no hay calificaciones
- Practica para El Uso de MATLABDocumento10 páginasPractica para El Uso de MATLABDaniel MirandaAún no hay calificaciones
- Respuestas Guia 07 (Estructuras de Control en C++)Documento14 páginasRespuestas Guia 07 (Estructuras de Control en C++)skilltikAún no hay calificaciones
- Trabajo de Analisis III en MatlabDocumento17 páginasTrabajo de Analisis III en MatlabGary Chavez VasquezAún no hay calificaciones
- ADA 6. Polinomios Interpolantes RESUELTADocumento20 páginasADA 6. Polinomios Interpolantes RESUELTAAaron Solis MonteroAún no hay calificaciones
- Trabajo ClaseDocumento9 páginasTrabajo ClaseMARIA LUISA ALVARADO SANTOSAún no hay calificaciones
- Ejercicios 888Documento6 páginasEjercicios 888maldonadopxAún no hay calificaciones
- Practica LimitesDocumento8 páginasPractica LimitesFelipe QuintanaAún no hay calificaciones
- Lab 01 TCA1 - IntroMatlabDocumento24 páginasLab 01 TCA1 - IntroMatlabChristian Choquehuanca PacoriAún no hay calificaciones
- TP2 2006Documento14 páginasTP2 2006Joha MarinAún no hay calificaciones
- Lab3 - Santos Cordova Yamir AndreDocumento9 páginasLab3 - Santos Cordova Yamir AndreYAMIR ANDRE SANTOS CORDOVAAún no hay calificaciones
- Sinais e SistemasDocumento10 páginasSinais e SistemasGabriel Reis RAún no hay calificaciones
- 2) Operadores Matemáticos PDFDocumento4 páginas2) Operadores Matemáticos PDFEmanuel Anccasi RamosAún no hay calificaciones
- Ejercicio 5Documento38 páginasEjercicio 5Michelle Alejandra Garduño PérezAún no hay calificaciones
- Aplicaciones Estadistica ComputacionalDocumento7 páginasAplicaciones Estadistica ComputacionalMarco Antonio OxsaAún no hay calificaciones
- Portafolio MNDocumento64 páginasPortafolio MNAlejandrp Josue Cardeña Benitez100% (1)
- R - ComprobadoDocumento13 páginasR - ComprobadoNilson Steven Yarlequé BenitesAún no hay calificaciones
- Ejercicio 8 en R StudioDocumento11 páginasEjercicio 8 en R StudioMarcos Rueda LópezAún no hay calificaciones
- Examen 1 Inteligencia ArtificialDocumento21 páginasExamen 1 Inteligencia ArtificialSebastian NiñoAún no hay calificaciones
- Matlab para EDO 1Documento35 páginasMatlab para EDO 1Hector Levano GamboaAún no hay calificaciones
- CodigoDocumento10 páginasCodigoMIGUEL ANGELAún no hay calificaciones
- Informe de MatlabDocumento23 páginasInforme de MatlabRudyJesusCapaIlizarbeAún no hay calificaciones
- DiapositivasProg R (Samuel)Documento46 páginasDiapositivasProg R (Samuel)Oliver Gomez CutipaAún no hay calificaciones
- Ecuaciones de Grado Superior..Algebra S 8semestral....Documento18 páginasEcuaciones de Grado Superior..Algebra S 8semestral....AndreeVillegasFarfan100% (1)
- Cálculo VectorialDocumento18 páginasCálculo VectorialElias Rodriguez MendozaAún no hay calificaciones
- 702 703 JM GUIA 7 Matematicas y Geometria Mayo 24Documento5 páginas702 703 JM GUIA 7 Matematicas y Geometria Mayo 24STIVEN DURANAún no hay calificaciones
- Practica 2Documento8 páginasPractica 2Angela MartínAún no hay calificaciones
- Ejercicios de Cuaciones de Cauchy-RiemannDocumento22 páginasEjercicios de Cuaciones de Cauchy-RiemannSirWeigel100% (1)
- Adams Moulton V2Documento4 páginasAdams Moulton V2Francisco Javier Gaona LopezAún no hay calificaciones
- Guia de Introduccion A ScilabDocumento29 páginasGuia de Introduccion A ScilabAndres UlloaAún no hay calificaciones
- Analisis NumericoDocumento12 páginasAnalisis NumericomilexiAún no hay calificaciones
- Parcial 2 - SageDocumento10 páginasParcial 2 - SageAlexis LunaAún no hay calificaciones
- Regresion e Interpolacion PDFDocumento16 páginasRegresion e Interpolacion PDFCami ElianaAún no hay calificaciones
- P2analisisnumerico 1071150Documento21 páginasP2analisisnumerico 1071150Jarixander Perez RomeroAún no hay calificaciones
- Ambrosio Huanay Brayan Hector I.Q.A.Documento12 páginasAmbrosio Huanay Brayan Hector I.Q.A.Thalii Ramiirez MaldonadoAún no hay calificaciones
- MHLC U2 A2 RaicDocumento11 páginasMHLC U2 A2 RaicRaúl Ibáñez Couoh0% (1)
- Regresion Lineal y CuadraticaDocumento42 páginasRegresion Lineal y CuadraticamaurcioenAún no hay calificaciones
- Simulacion R - EstadisticoDocumento38 páginasSimulacion R - EstadisticoLibrosAyudaAún no hay calificaciones
- Ejercicios Resuelto Usando RDocumento19 páginasEjercicios Resuelto Usando Rhectorla030% (2)
- Control 1 Laboratorio 1-1 AcfsDocumento13 páginasControl 1 Laboratorio 1-1 AcfsAc AryanAún no hay calificaciones
- Guía de Presentación de Resultados en ScilabDocumento8 páginasGuía de Presentación de Resultados en ScilabCamila RaigosoAún no hay calificaciones
- Ejercicios Resueltos Uso de MatlabDocumento15 páginasEjercicios Resueltos Uso de MatlabjhasmanyAún no hay calificaciones
- Método de La Secante en MatlabDocumento12 páginasMétodo de La Secante en MatlabMoises Choqque PalominoAún no hay calificaciones
- Potencias y Logaritmos de Números RealesDocumento11 páginasPotencias y Logaritmos de Números RealesbuffysangoAún no hay calificaciones
- Capítulo 5-Matlab PDFDocumento56 páginasCapítulo 5-Matlab PDFJuan camilo Ponce SegoviaAún no hay calificaciones
- Romero Ident Fuzzy BDocumento8 páginasRomero Ident Fuzzy BRonald RomeroAún no hay calificaciones
- Práctica 1 - Estimación de Punto y Por Intervalos 1Documento9 páginasPráctica 1 - Estimación de Punto y Por Intervalos 1jorge antonio torres cabreraAún no hay calificaciones
- 3.1 Gráficos Con RDocumento10 páginas3.1 Gráficos Con RNanas NanisAún no hay calificaciones
- Sociología Jurídica - AntologíaDocumento7 páginasSociología Jurídica - AntologíaAndres AlvarezAún no hay calificaciones
- Empaques y Embalaje PDFDocumento17 páginasEmpaques y Embalaje PDFIrlena CoronellAún no hay calificaciones
- TP2 - Historia Arq.1 - PASAPERA BAYONA CARMEN KRISHELLDocumento10 páginasTP2 - Historia Arq.1 - PASAPERA BAYONA CARMEN KRISHELLCarmen Krishell PasaperaAún no hay calificaciones
- Instrumentos de Evaluación - Lista de Chequeo Mapa MentalDocumento4 páginasInstrumentos de Evaluación - Lista de Chequeo Mapa MentalDEIBER ANTONIO MARZOLA TAFURAún no hay calificaciones
- EducamosCLM Seguimiento EducativoDocumento1 páginaEducamosCLM Seguimiento EducativoJuan José Bernal ParraAún no hay calificaciones
- Práctica #2. Dispositivos de Accionamientos Eléctricos en Automatismos IndustrialesDocumento11 páginasPráctica #2. Dispositivos de Accionamientos Eléctricos en Automatismos IndustrialesDaniel David Mantilla QuinteroAún no hay calificaciones
- Desarrollo Caso Practico 2 Sport Athletic S.A AlumnosDocumento14 páginasDesarrollo Caso Practico 2 Sport Athletic S.A AlumnosAnthonny Montalván100% (1)
- Silabo Medio Ambiente y Desarrollo Sostenible - 2024Documento11 páginasSilabo Medio Ambiente y Desarrollo Sostenible - 2024MIGUEL ANGEL BARRIONUEVO CONZAAún no hay calificaciones
- Proyecto Impres. Historia IIIDocumento21 páginasProyecto Impres. Historia IIILuis Adolfo Rodríguez MartínezAún no hay calificaciones
- Sistemas ModalesDocumento3 páginasSistemas ModalesHumberto Fernando Moncada PeñaAún no hay calificaciones
- Dac, Estados de Flujo.Documento4 páginasDac, Estados de Flujo.Diego Alvarez RozoAún no hay calificaciones
- Practica 2 Inorganica IDocumento7 páginasPractica 2 Inorganica Ibrenda ruizAún no hay calificaciones
- Alternativas de Solución - Norleidis YasgunaDocumento9 páginasAlternativas de Solución - Norleidis YasgunaNorle YagunaAún no hay calificaciones
- Plan de AcciónDocumento2 páginasPlan de Acciónaliciafreire57Aún no hay calificaciones
- Modelo 02 Resolucion Aprobacion RD028 2016EF5001Documento2 páginasModelo 02 Resolucion Aprobacion RD028 2016EF5001Linder Santos BustamanteAún no hay calificaciones
- Evidencia 2 NIA-SOX PDFDocumento10 páginasEvidencia 2 NIA-SOX PDFHéctor P. CastilloAún no hay calificaciones
- Fallo Ryan Tuccillo C CencosudDocumento25 páginasFallo Ryan Tuccillo C CencosudJorge EirisAún no hay calificaciones
- Proyecto de InvestigaciónDocumento43 páginasProyecto de Investigaciónper555100% (1)
- Alba InstitucionalDocumento26 páginasAlba Institucionalapi-149138320Aún no hay calificaciones
- Neuroestructura Caso La Muralla de LimaDocumento53 páginasNeuroestructura Caso La Muralla de LimaHugo Soto Perez0% (1)
- CBR InalteradoDocumento4 páginasCBR InalteradoPercy RojasAún no hay calificaciones
- Guia Prestadores 1470 PDFDocumento14 páginasGuia Prestadores 1470 PDFCristian MorenoAún no hay calificaciones
- Clase Sesión 14 - II ParteDocumento11 páginasClase Sesión 14 - II ParteNADIA STEFANIA SEIJAS BERNABEAún no hay calificaciones
- TAREA QuimicaDocumento13 páginasTAREA QuimicaAlessandro RiquelmeAún no hay calificaciones