También podría gustarte
- Clase Introduccion A EDD 2 (Repaso Pilas)Documento17 páginasClase Introduccion A EDD 2 (Repaso Pilas)GENESIS NAHOMI APARICIO ACANAún no hay calificaciones
- 5 TdaDocumento34 páginas5 TdaVale Constanzo RiverosAún no hay calificaciones
- Las Estructuras de Datos Son Aquellas Que NosDocumento13 páginasLas Estructuras de Datos Son Aquellas Que NosHumberto Hernandez GranadosAún no hay calificaciones
- Estructura de DatosDocumento17 páginasEstructura de DatosDiocelin OsorioAún no hay calificaciones
- Stacks Queue List TreeDocumento27 páginasStacks Queue List TreeAlejandro Alejandro CAún no hay calificaciones
- Instituto Tecnológico de AguascalientesDocumento9 páginasInstituto Tecnológico de AguascalientesJose ZamoraAún no hay calificaciones
- Módulo 2 - Lectura 2Documento19 páginasMódulo 2 - Lectura 2luis pAún no hay calificaciones
- Estructuras anidadasDocumento15 páginasEstructuras anidadasMaribel Peñafiel SequeirosAún no hay calificaciones
- ColasDocumento30 páginasColasjcl3192Aún no hay calificaciones
- Tema 3 EstructurasLinealesDocumento46 páginasTema 3 EstructurasLinealesSalma mlrAún no hay calificaciones
- TDADocumento4 páginasTDApinponeAún no hay calificaciones
- Estructuras linealesDocumento6 páginasEstructuras linealesApril MejiaAún no hay calificaciones
- Pilas y ColasDocumento10 páginasPilas y Colasleonardo suarezAún no hay calificaciones
- Programación, Tema 1Documento12 páginasProgramación, Tema 1Luis Fernando Montes Dela CruzAún no hay calificaciones
- GuialistaDocumento18 páginasGuialistaAndreina GarciaAún no hay calificaciones
- Unidad 1 Estructura de DatosDocumento6 páginasUnidad 1 Estructura de DatosAbreu96Aún no hay calificaciones
- Entrega Semana 10 Actividad BibliotecaDocumento7 páginasEntrega Semana 10 Actividad BibliotecaJuan David LOPEZ GUTIERREZAún no hay calificaciones
- Trabajo Pila (Programacion)Documento12 páginasTrabajo Pila (Programacion)DanieleonardoAún no hay calificaciones
- Implementación de Pilas con Listas EnlazadasDocumento19 páginasImplementación de Pilas con Listas EnlazadasRodrigoQuinterosAún no hay calificaciones
- TadsDocumento43 páginasTadsAlvaro Chambi CamposAún no hay calificaciones
- Fichas Estructuras de DatosDocumento7 páginasFichas Estructuras de DatosMiguel Angel Rodríguez FuentesAún no hay calificaciones
- 3er ParcialDocumento2 páginas3er ParcialJesús RamírezAún no hay calificaciones
- Informe Sobre ColasDocumento17 páginasInforme Sobre ColasJorling VíctorAún no hay calificaciones
- TAD ListasDocumento12 páginasTAD ListasRicardo Mauricio ReyesAún no hay calificaciones
- JavaDocumento7 páginasJavaYoshiro VilchezAún no hay calificaciones
- Arboles Binarios, Colas, FilasDocumento95 páginasArboles Binarios, Colas, FilasRaulAún no hay calificaciones
- Pilas en programación: tipos, operaciones y ejemplosDocumento16 páginasPilas en programación: tipos, operaciones y ejemplosCristian HernandézAún no hay calificaciones
- Estructuras Lineales JavaDocumento13 páginasEstructuras Lineales JavaJulio BelloAún no hay calificaciones
- Implementación de Pila, Cola y Lista Con Punto de InterésDocumento7 páginasImplementación de Pila, Cola y Lista Con Punto de InterésVicente ParraAún no hay calificaciones
- Colas PooDocumento4 páginasColas PooIsaac SanchezAún no hay calificaciones
- Ejerc EDTema 3Documento11 páginasEjerc EDTema 3Fran222999 XDAún no hay calificaciones
- Pilas, Colas, Listas, Arboles, Grafos...Documento11 páginasPilas, Colas, Listas, Arboles, Grafos...Tomás José Sánchez Díaz50% (2)
- Arbol Binario Post-OrdenDocumento16 páginasArbol Binario Post-OrdenMartin BernabeAún no hay calificaciones
- ColasDocumento13 páginasColasemmauel.esva1Aún no hay calificaciones
- Sesión 4 (Laboratorio) : Pilas y Colas 1.1. Implementación de Una Pila Con Listas Enlazadas ObjetivoDocumento17 páginasSesión 4 (Laboratorio) : Pilas y Colas 1.1. Implementación de Una Pila Con Listas Enlazadas ObjetivoRicardo GarciaAún no hay calificaciones
- Teoria (Módulo 4)Documento22 páginasTeoria (Módulo 4)Str 3Aún no hay calificaciones
- TDA y listasSEDocumento13 páginasTDA y listasSEAndrés JackAún no hay calificaciones
- Ordenar Listas en JavaDocumento16 páginasOrdenar Listas en JavaShPetherAún no hay calificaciones
- Tipos Abstractos de Datos - Tad ListaDocumento28 páginasTipos Abstractos de Datos - Tad ListaLessGmzAún no hay calificaciones
- Pilas en CDocumento23 páginasPilas en CTony Ztratokazter DkAún no hay calificaciones
- TDA Pila y ColaDocumento16 páginasTDA Pila y ColaJulio Cesar Soto VelizAún no hay calificaciones
- Actividad 10.2Documento6 páginasActividad 10.2David ZAún no hay calificaciones
- Pilas y ColasDocumento12 páginasPilas y Colaselrafa_759Aún no hay calificaciones
- EstructurasDocumento32 páginasEstructurasBryan Tony Cipriano TarazonaAún no hay calificaciones
- Ejemplos de TDADocumento12 páginasEjemplos de TDAFrancisco0% (1)
- Pilas PDFDocumento7 páginasPilas PDFBetty GarciaAún no hay calificaciones
- Estructura PilaDocumento6 páginasEstructura PilaYesenia Villegas RivasAún no hay calificaciones
- Pilas y ColasDocumento13 páginasPilas y ColasEduardo LesseyAún no hay calificaciones
- Lectura 3 - Listas EnlazadasDocumento40 páginasLectura 3 - Listas Enlazadasclays2Aún no hay calificaciones
- Deda U1 A2 MatzDocumento10 páginasDeda U1 A2 MatzMariana ZavalaAún no hay calificaciones
- Listas, Pilas y ColasDocumento23 páginasListas, Pilas y ColasChristian Axel Quiñones FernandezAún no hay calificaciones
- Evaluacion EmilyDocumento7 páginasEvaluacion EmilyJorge LuisAún no hay calificaciones
- Aula VirtualDocumento8 páginasAula VirtualLuana GadêlhaAún no hay calificaciones
- C++ Pilas ApuntesDocumento15 páginasC++ Pilas ApuntesNachoBrotoBlascoAún no hay calificaciones
- EDTema 3 TADlDocumento197 páginasEDTema 3 TADlFran222999 XDAún no hay calificaciones
- 2 Guia Estructura de Datos Juliana y SantiagoDocumento8 páginas2 Guia Estructura de Datos Juliana y SantiagoJotas VillalobosAún no hay calificaciones
- 20152sfiec030121 1Documento5 páginas20152sfiec030121 1anabska bnsndAún no hay calificaciones
- Monografia ListaDocumento6 páginasMonografia ListaALFONSO ALEJANDRO SEVILLA HIDALGOAún no hay calificaciones
- ED 3 Transparencias. ListasDocumento73 páginasED 3 Transparencias. ListasDani FrancoAún no hay calificaciones
- Rouser Ns125 ManualdeusuarioDocumento33 páginasRouser Ns125 ManualdeusuarioPUNE VENTAS100% (5)
- Catalogo Accionadores PuertasDocumento363 páginasCatalogo Accionadores PuertasLuis Bienvenido Pastor100% (1)
- Manufactura Inteligente Utilizando Vision para RobotsDocumento6 páginasManufactura Inteligente Utilizando Vision para RobotsjavierchachacoAún no hay calificaciones
- Estructura capas Tierra TEORIA PLACAS TECTONICASDocumento8 páginasEstructura capas Tierra TEORIA PLACAS TECTONICASKael'ThasYovanyAún no hay calificaciones
- Guia2criteriossensibilidad1sem2019Documento2 páginasGuia2criteriossensibilidad1sem2019Paul Pulgar OrellanaAún no hay calificaciones
- Ensayo Sobre La Música de Las Esferas - Julieta M. Gallegos AciarDocumento4 páginasEnsayo Sobre La Música de Las Esferas - Julieta M. Gallegos AciarJulieta GallegosAún no hay calificaciones
- Puesta a Tierra en Subestaciones: ¿Unidas o SeparadasDocumento5 páginasPuesta a Tierra en Subestaciones: ¿Unidas o SeparadasJuan Carlos Dubravcic100% (1)
- Furlex 100SDocumento2 páginasFurlex 100SAcastillaje y JarciasAún no hay calificaciones
- 3 - Elementos, Mezclas y CompuestosDocumento4 páginas3 - Elementos, Mezclas y CompuestosErley GarcésAún no hay calificaciones
- CAPITULOS 6 Y 7 GESTION TECNOLÓGICA HOSPITALARIA (Autoguardado)Documento12 páginasCAPITULOS 6 Y 7 GESTION TECNOLÓGICA HOSPITALARIA (Autoguardado)AlexAún no hay calificaciones
- Java Programacion FuncionalDocumento45 páginasJava Programacion FuncionalChrisAún no hay calificaciones
- Herramientas TIC para la gerencia: Procesadores de texto y funciones de WordDocumento17 páginasHerramientas TIC para la gerencia: Procesadores de texto y funciones de WordSamara ToroAún no hay calificaciones
- Tarea 1 de DMC1109Documento2 páginasTarea 1 de DMC1109GerarxxxAún no hay calificaciones
- TABLA Tema2 EstadisticaIIDocumento3 páginasTABLA Tema2 EstadisticaIILuis EspañaAún no hay calificaciones
- Solucion Coversiones YcinematicaDocumento18 páginasSolucion Coversiones YcinematicanancyAún no hay calificaciones
- Modelado estructural de un reservorio en ANSYSDocumento4 páginasModelado estructural de un reservorio en ANSYSCHILON ISPILCO ELIO0% (1)
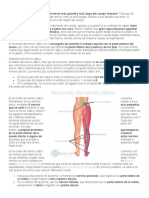
- Características y anatomía del nervio ciáticoDocumento12 páginasCaracterísticas y anatomía del nervio ciáticoLuz Liz CLAún no hay calificaciones
- Guia Manejo Software CrocodileDocumento3 páginasGuia Manejo Software CrocodileQuevin BarreraAún no hay calificaciones
- La CienciaDocumento4 páginasLa CienciaAndrea Sanchez AbarcaAún no hay calificaciones
- 01-Clases de OracionesDocumento103 páginas01-Clases de OracionesFernando Morián CaballeroAún no hay calificaciones
- Prox MoxDocumento3 páginasProx MoxMichelle Potes SanchezAún no hay calificaciones
- RadioFrecuencia EjerciciosDocumento23 páginasRadioFrecuencia Ejerciciosfa98Aún no hay calificaciones
- Análisis y Comentario de Textos FilosóficosDocumento12 páginasAnálisis y Comentario de Textos FilosóficosFernando Nietzsche0% (1)
- Taller para Parcial 2021Documento3 páginasTaller para Parcial 2021Samuel DelgadoAún no hay calificaciones
- NUESTRA SEÑORA DE CHIQUINQUIRA 1ER AÑODocumento1 páginaNUESTRA SEÑORA DE CHIQUINQUIRA 1ER AÑOcinemaAún no hay calificaciones
- Grupo4 Actividad21 5847Documento5 páginasGrupo4 Actividad21 5847WILSON ANDRES ERAZO CUASAPAZAún no hay calificaciones
- Introducción A La Toma de DecisionesDocumento41 páginasIntroducción A La Toma de DecisionesRenato WongAún no hay calificaciones
- Act 2 RDocumento7 páginasAct 2 RIbsenJavierMosqueraVilladiegoAún no hay calificaciones
- A - Sem2 - Tanto Por Ciento e InterésDocumento4 páginasA - Sem2 - Tanto Por Ciento e InterésAlisson Gálvez ArévaloAún no hay calificaciones