También podría gustarte
- Plantilla Estándar de Codificación JavaDocumento4 páginasPlantilla Estándar de Codificación JavaTatiana RamosAún no hay calificaciones
- Manual de Configuracion DHCP Windows Server 2008Documento16 páginasManual de Configuracion DHCP Windows Server 2008Alejandro Rossi Dominguez88% (8)
- Generacion de Codigo Intermedio EntregarDocumento13 páginasGeneracion de Codigo Intermedio EntregarLiza Aleman100% (2)
- Diagrama en Bloques de Un Monitor de LCDDocumento30 páginasDiagrama en Bloques de Un Monitor de LCDJesus UrrietaAún no hay calificaciones
- Cuadro Comparativo-Tipo de AutomataDocumento2 páginasCuadro Comparativo-Tipo de Automatadarka lolAún no hay calificaciones
- BNF & EbnfDocumento2 páginasBNF & EbnfDahianna RamírezAún no hay calificaciones
- Compilados Usando Jflex y Cup, para La Suma, Resta o Multiplicación de Enteros o PalabrasDocumento15 páginasCompilados Usando Jflex y Cup, para La Suma, Resta o Multiplicación de Enteros o PalabrasJuan Pablo0% (1)
- Software E Ingeniería de Software: CapítuloDocumento17 páginasSoftware E Ingeniería de Software: CapítuloYozelin Mercedes RojasAún no hay calificaciones
- Herramientas CaseDocumento17 páginasHerramientas Casekevin paulAún no hay calificaciones
- Analizador SemánticoDocumento52 páginasAnalizador SemánticoDéborah LevAún no hay calificaciones
- POO en Visual Basic NET (Parte 1)Documento16 páginasPOO en Visual Basic NET (Parte 1)cesaryngwieAún no hay calificaciones
- Conversion de BasesDocumento4 páginasConversion de Basesnicolas100% (1)
- Reporte de Practica Espejo (Mirroring)Documento17 páginasReporte de Practica Espejo (Mirroring)Francisco Alejandro Torres OrtizAún no hay calificaciones
- Cadenas de Caracteres en JavaDocumento4 páginasCadenas de Caracteres en JavaSamuel Andrés Pinzón VegaAún no hay calificaciones
- Tópicos Avanzados de ProgramaciónDocumento20 páginasTópicos Avanzados de ProgramaciónSaul EspinozaAún no hay calificaciones
- Evolución de Los SGBDDocumento6 páginasEvolución de Los SGBDLuis Carlos ZuñigaAún no hay calificaciones
- Generacion de Codigo ObjetoDocumento7 páginasGeneracion de Codigo ObjetoEdgar Mendez AlanisAún no hay calificaciones
- Cuadro Comparativo de Manejadores de La Base de DatosDocumento3 páginasCuadro Comparativo de Manejadores de La Base de DatosAnderson Ryan Porras QuispeAún no hay calificaciones
- Expresiones RegularesDocumento7 páginasExpresiones RegularesLaura Elizabeth Gonzalez VillegasAún no hay calificaciones
- Línea de Tiempo LinuxDocumento8 páginasLínea de Tiempo LinuxAlan GarciaAún no hay calificaciones
- Expresiones RegularesDocumento4 páginasExpresiones RegularesMarcos De LeonAún no hay calificaciones
- Actividad 6Documento6 páginasActividad 6Xavier vazquezAún no hay calificaciones
- Traductor (Automatas 1)Documento8 páginasTraductor (Automatas 1)Hecsali SalinasAún no hay calificaciones
- Aplicación de Estructuras de DatosDocumento11 páginasAplicación de Estructuras de DatosKevin CvzAún no hay calificaciones
- 2.9 Instrucciones Aritmeticas1Documento4 páginas2.9 Instrucciones Aritmeticas1fortino_sanchezAún no hay calificaciones
- Compiladores e InterpretesDocumento20 páginasCompiladores e InterpretesCabere Nadime0% (1)
- Unidad 2 Generación de Código Intermedio - 1Documento91 páginasUnidad 2 Generación de Código Intermedio - 1Jose Angel Vazquez TorresAún no hay calificaciones
- Resumen de Los Videos de MantenimientoDocumento7 páginasResumen de Los Videos de MantenimientoRuben GaitanAún no hay calificaciones
- Marco TeoricoDocumento12 páginasMarco TeoricoJOSE ALEJANDRO CERVANTES ROMEROAún no hay calificaciones
- Tele Comunica C I OnesDocumento4 páginasTele Comunica C I OnesCarlos Leonardo HernandezAún no hay calificaciones
- Introducción A Las Plataformas XAMPP, WAMP y APPSERVDocumento5 páginasIntroducción A Las Plataformas XAMPP, WAMP y APPSERVWilly SalcedoAún no hay calificaciones
- Practicas de Configuracion y Verificacion de Las ACLDocumento5 páginasPracticas de Configuracion y Verificacion de Las ACLchernandez_444740Aún no hay calificaciones
- Sybase 7Documento26 páginasSybase 7anon_251766052Aún no hay calificaciones
- Ejercicios Permisos Usuarios PDFDocumento2 páginasEjercicios Permisos Usuarios PDFneoelfeo100% (1)
- Arquitectura Del MouseDocumento5 páginasArquitectura Del Mouseginapao9116940% (1)
- Subneteo de RedesDocumento11 páginasSubneteo de RedesMaria RosaAún no hay calificaciones
- Interpretes y Compiladores Cuadro ComparativoDocumento6 páginasInterpretes y Compiladores Cuadro ComparativoANGEL ROSARIO MARTINEZAún no hay calificaciones
- Manual Básico de HTMLDocumento23 páginasManual Básico de HTMLISAIAS TORREZ MARCELAún no hay calificaciones
- Redes 2 InformeDocumento21 páginasRedes 2 InformeRobin YanezAún no hay calificaciones
- Identificar Los Recursos Que Administra El Sistema OperativoDocumento11 páginasIdentificar Los Recursos Que Administra El Sistema OperativoToño MelgarAún no hay calificaciones
- Requisitos Minimos Instalacion de Gestores de Bases de DatosDocumento10 páginasRequisitos Minimos Instalacion de Gestores de Bases de DatosChristian AndrésAún no hay calificaciones
- Reporte ProgramacionDocumento8 páginasReporte ProgramacionryucotsuAún no hay calificaciones
- Lenguajes y Autómatas IDocumento91 páginasLenguajes y Autómatas ICeleste Hernández GarayAún no hay calificaciones
- Capitulo - 24 Metodos FormalesDocumento6 páginasCapitulo - 24 Metodos FormalesRino Tovar Abreu100% (1)
- 1.protocolos de Comunicaciones para La RedDocumento33 páginas1.protocolos de Comunicaciones para La RedJ, ReyesAún no hay calificaciones
- Cuestionario de Redes en GeneralDocumento2 páginasCuestionario de Redes en GeneralAngel David Pool TAún no hay calificaciones
- Archivos LOGDocumento14 páginasArchivos LOGJose Emmanuel Castro PalmaAún no hay calificaciones
- Informe Ieee Sistemas de ArchivosDocumento3 páginasInforme Ieee Sistemas de ArchivosAndresCamiloAún no hay calificaciones
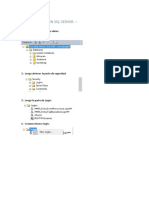
- Crear Usuario en SQL ServerDocumento7 páginasCrear Usuario en SQL ServerLuis RiveroAún no hay calificaciones
- Redes de Comunicaciones ConmutadasDocumento5 páginasRedes de Comunicaciones ConmutadasJoselin QuijijeAún no hay calificaciones
- Instalacion de Active DirectoryDocumento33 páginasInstalacion de Active DirectorybmxmtntAún no hay calificaciones
- ReporteDocumento6 páginasReporteShawn WrightAún no hay calificaciones
- ParavirtualizaciónDocumento4 páginasParavirtualizaciónFrancisco Cabello RAún no hay calificaciones
- Analizador LexicoDocumento14 páginasAnalizador LexicoMaicol GarciaAún no hay calificaciones
- Ensayo Analisis LexicoDocumento13 páginasEnsayo Analisis LexicoanthonyAún no hay calificaciones
- Proyecto Final LenguajesDocumento20 páginasProyecto Final LenguajesEduardo VázquezAún no hay calificaciones
- Teoría de La Computación Analizador LexicoDocumento14 páginasTeoría de La Computación Analizador Lexicohackdg 19Aún no hay calificaciones
- Analisis LexicoDocumento21 páginasAnalisis Lexicoala jazaAún no hay calificaciones
- Analisis Lexico - Traductores, CompiladoresDocumento15 páginasAnalisis Lexico - Traductores, CompiladoresJose Angel QuinteroAún no hay calificaciones
- Analisis LexicoDocumento13 páginasAnalisis LexicoChristian MarquezAún no hay calificaciones
- YoProgramo2 - Artefactos SCRUMDocumento1 páginaYoProgramo2 - Artefactos SCRUMMaria Grisel MirandaAún no hay calificaciones
- WinDEPAV 2Documento3 páginasWinDEPAV 2Mateo Montoya Cardona100% (1)
- 1.1 Elementos Del Modelo de ObjetosDocumento31 páginas1.1 Elementos Del Modelo de ObjetosAngel salas martinezAún no hay calificaciones
- Editar Documento en El DriveDocumento16 páginasEditar Documento en El DriveAlejandro HigueraAún no hay calificaciones
- Programacion de PLCDocumento8 páginasProgramacion de PLCcarlos leonAún no hay calificaciones
- (M3-L2) EncapsulamientoDocumento7 páginas(M3-L2) Encapsulamientokarla gabriela peralta madrigalAún no hay calificaciones
- Control de Lectura (U-2)Documento14 páginasControl de Lectura (U-2)Felipe Guerrero100% (1)
- Nathaly Parra Godinez - Entrega - 9Documento87 páginasNathaly Parra Godinez - Entrega - 9NATHALY PARRA GODINEZAún no hay calificaciones
- Ejercicios Con MatricesDocumento17 páginasEjercicios Con MatriceshorudaAún no hay calificaciones
- Proyecto EmsambladorDocumento24 páginasProyecto EmsambladortatianaAún no hay calificaciones
- Guiade Saint PagoDocumento27 páginasGuiade Saint PagoeleaquinpcAún no hay calificaciones
- Niveles de AccesoDocumento3 páginasNiveles de AccesoMiguelAún no hay calificaciones
- PichulaDocumento3 páginasPichulaGenesis Calvo CarrilloAún no hay calificaciones
- Vdocuments - MX Curso-UmlpptDocumento62 páginasVdocuments - MX Curso-UmlpptJESUSA NATIVIDAD ANGONO ESONO NFONOAún no hay calificaciones
- Práctica 1 - Introducción A Los AlgoritmosDocumento6 páginasPráctica 1 - Introducción A Los AlgoritmosPiero GuerraAún no hay calificaciones
- (AutocapturaV2) Manual de IntegraciónDocumento18 páginas(AutocapturaV2) Manual de IntegraciónJose RamirezAún no hay calificaciones
- Taller de Páginas Web - SEM02 - SintesísDocumento5 páginasTaller de Páginas Web - SEM02 - SintesísLari DPAún no hay calificaciones
- Tutorial de VSFlexGrid 8Documento2 páginasTutorial de VSFlexGrid 8zetaperuAún no hay calificaciones
- Salgado - Stalin - Guia Didactica Docentes Introducción A Las TicDocumento79 páginasSalgado - Stalin - Guia Didactica Docentes Introducción A Las TicStalin Marcelo Salgado GarcíaAún no hay calificaciones
- Guia Java Script Nivel 1Documento30 páginasGuia Java Script Nivel 1Miguel OstosAún no hay calificaciones
- Nagios Vs Observium: 1. Nagios Core (Versión Gratuita) 1.1. DescripciónDocumento3 páginasNagios Vs Observium: 1. Nagios Core (Versión Gratuita) 1.1. DescripciónJuan Fernando Córdova ArevaloAún no hay calificaciones
- Ajustes para QB64Documento3 páginasAjustes para QB64Jooseph Daaniiel Hernandezz BalcazarAún no hay calificaciones
- Infografia y Cuadro Comparativo1Documento3 páginasInfografia y Cuadro Comparativo1Andres CuadradoAún no hay calificaciones
- 0281 Sistemas Operativos 1 - 0281 - SO1 - Programa - Curso - 1S2022Documento5 páginas0281 Sistemas Operativos 1 - 0281 - SO1 - Programa - Curso - 1S2022Saul ObandoAún no hay calificaciones
- CronDocumento23 páginasCrondarlin jhoel teran condorAún no hay calificaciones
- M3 GDPDocumento24 páginasM3 GDPdabenavidesdAún no hay calificaciones
- UNIDAD I - Cont. - Integración de AplicacionesDocumento14 páginasUNIDAD I - Cont. - Integración de AplicacionesEstebanBareiroAún no hay calificaciones
- Ing Software - TRABAJO FINAL - LUZ FARMADocumento61 páginasIng Software - TRABAJO FINAL - LUZ FARMALuis Arcangel Valdivia ChavezAún no hay calificaciones
- Planeacion de Computacion Primaria de 1º A 6ºDocumento4 páginasPlaneacion de Computacion Primaria de 1º A 6ºArturo Flores IxtaAún no hay calificaciones
- Examen FinalDocumento10 páginasExamen FinalgabrielAún no hay calificaciones