También podría gustarte
- BDD U3 EaDocumento26 páginasBDD U3 EanegrocabreraAún no hay calificaciones
- Ed TareaDocumento11 páginasEd TareaAbraham PachecoAún no hay calificaciones
- Fundamentos de Gestion de Bases de DatosDocumento17 páginasFundamentos de Gestion de Bases de DatosCristian Saco CardenasAún no hay calificaciones
- Fundamentos Bases DatosDocumento10 páginasFundamentos Bases DatosDuilio Andre Chavez CuariteAún no hay calificaciones
- Fundamentos de Base de Datos 2Documento1 páginaFundamentos de Base de Datos 2Williams San Martín MejíaAún no hay calificaciones
- 1-Bases de Datos - PresentaciónDocumento75 páginas1-Bases de Datos - PresentaciónMARCOS NAVARRO RUIZAún no hay calificaciones
- Manejadores de Bases de DatosDocumento7 páginasManejadores de Bases de DatosMabelRodAlfAún no hay calificaciones
- Cuadernillo Base de Datos Access - Horacio SattiDocumento51 páginasCuadernillo Base de Datos Access - Horacio SattiHoracio Dante SattiAún no hay calificaciones
- Instituto Politécnico Altagracia Iglesias de LoraDocumento11 páginasInstituto Politécnico Altagracia Iglesias de LoraJulie Del Carmen Liriano PeñaAún no hay calificaciones
- Tarea Sistema de Gestión de Base de DatosDocumento7 páginasTarea Sistema de Gestión de Base de DatosIsrael Canale TapiaAún no hay calificaciones
- Clase 02 - Bases de DatosDocumento11 páginasClase 02 - Bases de DatosEdicson AguirreAún no hay calificaciones
- UD01. - Fundamentos e Implantación de Los Sistemas Gestores de Bases de DatosDocumento34 páginasUD01. - Fundamentos e Implantación de Los Sistemas Gestores de Bases de DatosTomas RodriguezAún no hay calificaciones
- Tarea de Base de Datos.Documento13 páginasTarea de Base de Datos.Dream relaxAún no hay calificaciones
- TICSDocumento12 páginasTICSGabriela UcAún no hay calificaciones
- TEMA 3 - Sistemas de Gestión de Base de Datos - RÍos Alcántara, Alma (2019)Documento8 páginasTEMA 3 - Sistemas de Gestión de Base de Datos - RÍos Alcántara, Alma (2019)Robin hoodAún no hay calificaciones
- Taller Evaluativo. BDDocumento4 páginasTaller Evaluativo. BDJOHAN SEBASTIAN DE LAS SALAS DONADOAún no hay calificaciones
- Conceptos de Bases de DatosDocumento53 páginasConceptos de Bases de DatosneogurbAún no hay calificaciones
- Bases de Datos - 1Documento3 páginasBases de Datos - 1Roberto Herrera GonzálezAún no hay calificaciones
- Unidad I Introduccion Al Sistema Manejador de Base de Datos (SMBD)Documento12 páginasUnidad I Introduccion Al Sistema Manejador de Base de Datos (SMBD)Juan Lopez SarrelangueAún no hay calificaciones
- Base de Datos ClaseDocumento27 páginasBase de Datos ClasesandrasierramAún no hay calificaciones
- Bases de Datos - EcuRedDocumento11 páginasBases de Datos - EcuRedLeon VerdeAún no hay calificaciones
- Fundamentos de Base de Datos 1Documento1 páginaFundamentos de Base de Datos 1Williams San Martín MejíaAún no hay calificaciones
- Desarrollo de Software 1Documento6 páginasDesarrollo de Software 14rxymystkxAún no hay calificaciones
- ITIC - Módulo 5 - Datos, BI, Big DataDocumento9 páginasITIC - Módulo 5 - Datos, BI, Big DataMariel Andrea MonserratAún no hay calificaciones
- Base de Datos 1Documento7 páginasBase de Datos 1eduardo dbmAún no hay calificaciones
- Bases Conceptos BásicosDocumento9 páginasBases Conceptos BásicosSANTIAGO SANDOVALAún no hay calificaciones
- Base de DatosDocumento8 páginasBase de DatosDaniela TorosAún no hay calificaciones
- COMPUTODocumento27 páginasCOMPUTOYael RihoAún no hay calificaciones
- Actividad 1Documento11 páginasActividad 1Alison EslavaAún no hay calificaciones
- Taller de Base de DatosDocumento6 páginasTaller de Base de DatosDoris Tatiana Ramirez MontesAún no hay calificaciones
- Asgbd U1Documento14 páginasAsgbd U1Don RamónAún no hay calificaciones
- Base de Datos 2Documento8 páginasBase de Datos 2Max Cruz GDAún no hay calificaciones
- ConcusionesDocumento3 páginasConcusionesarmando jeffryAún no hay calificaciones
- Rubio Torres. (2021) - Introducción Al Almacenamiento, Organización y Bases de Datos. Universidad Tecnológica de MéxicoDocumento8 páginasRubio Torres. (2021) - Introducción Al Almacenamiento, Organización y Bases de Datos. Universidad Tecnológica de MéxicogiselleAún no hay calificaciones
- Resumen Lectura 1Documento8 páginasResumen Lectura 1MarceloAún no hay calificaciones
- Academia de Computacion SoltcetDocumento14 páginasAcademia de Computacion SoltcetMarilyn ArevaloAún no hay calificaciones
- Bases de Datos y Sus TiposDocumento9 páginasBases de Datos y Sus TiposVictor HernandezAún no hay calificaciones
- Ensayo Generalidades de BDD Ernis Aguero AD2422Documento7 páginasEnsayo Generalidades de BDD Ernis Aguero AD2422Ernis AgueroAún no hay calificaciones
- Tarea1 S3 YSantamaria Seccion34Documento14 páginasTarea1 S3 YSantamaria Seccion34Esmeralda SantamariaAún no hay calificaciones
- Ensayo Base de DatosDocumento4 páginasEnsayo Base de DatosMonica Patricia Rosado CifuentesAún no hay calificaciones
- Bases Datos Unidad 1 InvestigacionDocumento10 páginasBases Datos Unidad 1 InvestigacionJuan VilarroelAún no hay calificaciones
- Unidad 3Documento12 páginasUnidad 3Gabby GuerraAún no hay calificaciones
- Actividad No 1 TICDocumento18 páginasActividad No 1 TICCaro Julio Quintero GuevaraAún no hay calificaciones
- Diseño de Base de DatosDocumento11 páginasDiseño de Base de Datosnelly yanelAún no hay calificaciones
- GBD Tema01Documento8 páginasGBD Tema01danielmayenjimenezAún no hay calificaciones
- Foro: "Análisis e Interpretación de Datos Dentro de Una Base de Datos"Documento4 páginasForo: "Análisis e Interpretación de Datos Dentro de Una Base de Datos"Calzado JirehAún no hay calificaciones
- Album GDBTDocumento9 páginasAlbum GDBTIsaac ChávezAún no hay calificaciones
- Introducción y Resumen TDIDocumento4 páginasIntroducción y Resumen TDIMendez Trejo Ana LauraAún no hay calificaciones
- Codo A Codo - 3 Bases de DatosDocumento72 páginasCodo A Codo - 3 Bases de DatosJorge Santiago MediatoAún no hay calificaciones
- TallerDocumento20 páginasTallertupu tamadreAún no hay calificaciones
- ENSAYODocumento8 páginasENSAYOMAYERLY CESPEDES MURILLOAún no hay calificaciones
- Base de DatosDocumento51 páginasBase de Datoscrissel_montecinosAún no hay calificaciones
- TD 3Documento27 páginasTD 3eugeniabezaresAún no hay calificaciones
- Análisis de Los SGBDDocumento2 páginasAnálisis de Los SGBDPaulo MedinaAún no hay calificaciones
- Manejadores de Base de Datos PDFDocumento4 páginasManejadores de Base de Datos PDFErnesto HernandezAún no hay calificaciones
- Ensayo Bases de Datos AvanzadasDocumento16 páginasEnsayo Bases de Datos AvanzadasMiguel Angel Naranjo ArcosAún no hay calificaciones
- Bda - Unidad 1 ResumenDocumento6 páginasBda - Unidad 1 Resumenchiodo.veronicaAún no hay calificaciones
- SGDBDocumento23 páginasSGDBMarisol TabuyoAún no hay calificaciones
- Bases de DatosDocumento6 páginasBases de DatosYamilet GimenezAún no hay calificaciones
- Módulo 4 PDFDocumento47 páginasMódulo 4 PDFDaniel Alejandro Garcia FlorianAún no hay calificaciones
- Desarrollo Web IntroduccionDocumento31 páginasDesarrollo Web IntroduccionJUANCA CBAún no hay calificaciones
- Java Persistencia JPADocumento40 páginasJava Persistencia JPAJUANCA CBAún no hay calificaciones
- Relaciones y JSQLDocumento24 páginasRelaciones y JSQLJUANCA CBAún no hay calificaciones
- WeberDocumento9 páginasWeberJUANCA CBAún no hay calificaciones
- Renacer de EspañaDocumento10 páginasRenacer de EspañaJUANCA CBAún no hay calificaciones
- ArmamentoDocumento7 páginasArmamentoJUANCA CBAún no hay calificaciones
- File:///C/Users/Juanca/Desktop/Juanjose/Katy Hero/Siu - TXT (7/5/2022 23:52:24)Documento10 páginasFile:///C/Users/Juanca/Desktop/Juanjose/Katy Hero/Siu - TXT (7/5/2022 23:52:24)JUANCA CBAún no hay calificaciones
- Paginas WebDocumento9 páginasPaginas WebJUANCA CBAún no hay calificaciones
- Paradigma ProgramacionDocumento12 páginasParadigma ProgramacionJUANCA CBAún no hay calificaciones
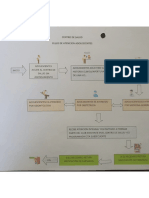
- Flujograma de Atención AdolescentesDocumento1 páginaFlujograma de Atención AdolescentesJUANCA CBAún no hay calificaciones
- Flujograma de ViolenciaDocumento2 páginasFlujograma de ViolenciaJUANCA CBAún no hay calificaciones
- Laptop Bolivia Noviembre 1ra SemanaDocumento101 páginasLaptop Bolivia Noviembre 1ra Semanarnsm.1978Aún no hay calificaciones
- Instalación Del PostgreSQL en LinuxDocumento6 páginasInstalación Del PostgreSQL en Linuxpostgresql_epnAún no hay calificaciones
- Memoria DDRDocumento4 páginasMemoria DDRMarilyn GarcíaAún no hay calificaciones
- Objetivos Virtualization System CenterDocumento11 páginasObjetivos Virtualization System CentersimbiakAún no hay calificaciones
- Qué Es Un Modelo de Entidad de Datos (EDM)Documento8 páginasQué Es Un Modelo de Entidad de Datos (EDM)Teresa BolañosAún no hay calificaciones
- Apuntes Basicos SQL PDFDocumento28 páginasApuntes Basicos SQL PDFHarry Hop HurtadoAún no hay calificaciones
- Ifm UGT207 20170227 IODD11 EsDocumento11 páginasIfm UGT207 20170227 IODD11 EsAlfonso Hernan Novoa CalabranAún no hay calificaciones
- 1.1 Protocolos de ConexionDocumento3 páginas1.1 Protocolos de ConexionJesus Daniel Castro OreaAún no hay calificaciones
- (OLC2) Proyecto1Documento90 páginas(OLC2) Proyecto1Gerardo ChayAún no hay calificaciones
- Act. 3 B1 6to Perito Contador Programacion Alis PerezDocumento5 páginasAct. 3 B1 6to Perito Contador Programacion Alis PerezAdriana MartinezAún no hay calificaciones
- Bases de Datos Nativas XMLDocumento12 páginasBases de Datos Nativas XMLMikelV4Aún no hay calificaciones
- 24 Heap HuffmanDocumento41 páginas24 Heap HuffmanMichellePérezAún no hay calificaciones
- Mapa de Memoria de Un ProcesoDocumento13 páginasMapa de Memoria de Un ProcesoAngel Leonardo Guemez RodriguezAún no hay calificaciones
- Unidad 6 Comandos Avanzados en LinuxDocumento5 páginasUnidad 6 Comandos Avanzados en LinuxPepeAún no hay calificaciones
- Manual de Instalacion MYSQL y ODBC PDFDocumento35 páginasManual de Instalacion MYSQL y ODBC PDFEduardo AguirreAún no hay calificaciones
- Instalar Gnome en OLPCDocumento22 páginasInstalar Gnome en OLPCVoley Pasión100% (1)
- Conociendo UbuntuDocumento26 páginasConociendo UbuntuIsra SanzAún no hay calificaciones
- Implementación Estructuras de Datos (1) SssDocumento50 páginasImplementación Estructuras de Datos (1) SssYESICA GOMEZ COAPAZAAún no hay calificaciones
- Configuracion de Fiori v1Documento45 páginasConfiguracion de Fiori v1Jonathan Argel Maldonado JuarezAún no hay calificaciones
- PolimorfismoDocumento16 páginasPolimorfismoJOSHUA ANDRE ISLAS GARCIAAún no hay calificaciones
- AA1 Evidencia 1 CUESTIONARIO Infraestructura Tecnologica de La OrganizacionDocumento8 páginasAA1 Evidencia 1 CUESTIONARIO Infraestructura Tecnologica de La Organizacioncarolina mezaAún no hay calificaciones
- BDAdv05 - Aggregation Framework en MongoDBDocumento7 páginasBDAdv05 - Aggregation Framework en MongoDBDuckyInfection [oficial] DIAún no hay calificaciones
- 2.2.3.3 ClaseDocumento6 páginas2.2.3.3 ClaseCamilo CortesAún no hay calificaciones
- Múltiples Conexiones A Bases de DatosDocumento2 páginasMúltiples Conexiones A Bases de DatosFroy GonzalezAún no hay calificaciones
- La Virtualización en CanaimaDocumento8 páginasLa Virtualización en CanaimaAna CalumaAún no hay calificaciones
- 05 Arreglos en Python ActualizadoDocumento16 páginas05 Arreglos en Python ActualizadoSergio Eduardo Peña SantamariaAún no hay calificaciones
- Tablas HashDocumento6 páginasTablas HashAnonymous 0irIcemoNAún no hay calificaciones
- Capítulo 11 Sistema de TransporteDocumento25 páginasCapítulo 11 Sistema de TransporteJose Julio LopezAún no hay calificaciones
- Guia de ComputacionDocumento12 páginasGuia de ComputacionJuan Perez AulanAún no hay calificaciones