También podría gustarte
- ITEM Nº1 PruebaDocumento1 páginaITEM Nº1 PruebaDiego Arteaga CanoAún no hay calificaciones
- Ciclo de Refrigeración Por Compresión A Vapor en Una Cámara de RefrigeraciónDocumento12 páginasCiclo de Refrigeración Por Compresión A Vapor en Una Cámara de RefrigeraciónKevin VasquezAún no hay calificaciones
- Flujo de fluidos a través de lechos porosos y fluizaciónDocumento31 páginasFlujo de fluidos a través de lechos porosos y fluizaciónKevin Vasquez100% (1)
- Semana 7. SecadoDocumento63 páginasSemana 7. SecadoSantiago DangerAún no hay calificaciones
- EjerciciosDocumento10 páginasEjerciciosKevin VasquezAún no hay calificaciones
- Extracción Líquido-LíquidoDocumento16 páginasExtracción Líquido-LíquidoSantiago DangerAún no hay calificaciones
- PW Basico 12Documento2 páginasPW Basico 12Kevin VasquezAún no hay calificaciones
- 02 Enfermedades Transmisión Alimentaria PDFDocumento18 páginas02 Enfermedades Transmisión Alimentaria PDFJosé Manuel Alvarez Fernández100% (1)
- Semana 7. SecadoDocumento63 páginasSemana 7. SecadoSantiago DangerAún no hay calificaciones
- Problemas - CentrifugacionDocumento9 páginasProblemas - CentrifugacionGiorgio Ormachea Cardenas60% (10)
- Operaciones Unitarias Agroindustriales: Extracción de azúcar, secado y equilibrio de fasesDocumento3 páginasOperaciones Unitarias Agroindustriales: Extracción de azúcar, secado y equilibrio de fasesKevin Vasquez0% (1)
- Examen de Opi Ii Unidad Grupo ADocumento1 páginaExamen de Opi Ii Unidad Grupo AKevin VasquezAún no hay calificaciones
- EJERCICIO EXTRACIÓN LIQUIDO-LIQUIDO - Rosas Vasquez KevinDocumento1 páginaEJERCICIO EXTRACIÓN LIQUIDO-LIQUIDO - Rosas Vasquez KevinKevin VasquezAún no hay calificaciones
- Ejercicios Extración Solido-LiquidoDocumento10 páginasEjercicios Extración Solido-LiquidoKevin VasquezAún no hay calificaciones
- Problemas de Balances de MateriaDocumento26 páginasProblemas de Balances de Materiafranzhm21Aún no hay calificaciones
- 2021 IiDocumento3 páginas2021 IiKevin VasquezAún no hay calificaciones
- Balances de Materia Sin - 2013 - 2014Documento2 páginasBalances de Materia Sin - 2013 - 2014Julio E Martinez HernandezAún no hay calificaciones
- Extracción de ácido acético por capas de agua y éter isopropílicoDocumento2 páginasExtracción de ácido acético por capas de agua y éter isopropílicoKevin VasquezAún no hay calificaciones
- Problemas: Problema N° 22.1Documento11 páginasProblemas: Problema N° 22.1Roberto BocanegraAún no hay calificaciones
- Extracción sólido-líquido: equilibrio y factoresDocumento33 páginasExtracción sólido-líquido: equilibrio y factoresRoberto BocanegraAún no hay calificaciones
- Semana 04 EjerciciosDocumento1 páginaSemana 04 EjerciciosKevin VasquezAún no hay calificaciones
- Demuestra Tu Aprendizaje 2021Documento1 páginaDemuestra Tu Aprendizaje 2021Kevin VasquezAún no hay calificaciones
- Analisis Del Macroentorno A Nivel Pais y RegiónDocumento5 páginasAnalisis Del Macroentorno A Nivel Pais y RegiónKevin VasquezAún no hay calificaciones
- Ejercicio 1Documento6 páginasEjercicio 1Kevin VasquezAún no hay calificaciones
- Amenaza de Productos SustitutosDocumento1 páginaAmenaza de Productos SustitutosKevin VasquezAún no hay calificaciones
- Estudio Organizacional - GrupalDocumento13 páginasEstudio Organizacional - GrupalKevin VasquezAún no hay calificaciones
- Graficos de BarrasDocumento2 páginasGraficos de BarrasKevin VasquezAún no hay calificaciones
- Practica Ejercicios 19 y 5Documento11 páginasPractica Ejercicios 19 y 5Kevin VasquezAún no hay calificaciones
- Demanda DirigidaDocumento1 páginaDemanda DirigidaKevin VasquezAún no hay calificaciones
- Estrategias para garantizar el crecimiento económicoDocumento7 páginasEstrategias para garantizar el crecimiento económicoyoadis andriana suarez sierraAún no hay calificaciones
- Word Estudio ContableDocumento6 páginasWord Estudio ContableGONZALO CONTRERAS GUTIERREZAún no hay calificaciones
- Guia de Ejercicios de Inmobiliaria 2Documento4 páginasGuia de Ejercicios de Inmobiliaria 2Jeanette MataAún no hay calificaciones
- Ejercicio Cete TAREADocumento5 páginasEjercicio Cete TAREAIlzeth Dayana Rodríguez mejiaAún no hay calificaciones
- Méndez - D Estados FinancierosDocumento6 páginasMéndez - D Estados FinancierosDaniel MéndezAún no hay calificaciones
- 3.-Formato de Inspección A Andamios de Carga Trabajo y Tipo EscaleraDocumento1 página3.-Formato de Inspección A Andamios de Carga Trabajo y Tipo EscaleraAlan Michel Rojas CamposAún no hay calificaciones
- Matemáticas financieras capítulo 3 resumenDocumento41 páginasMatemáticas financieras capítulo 3 resumenmara dalaesAún no hay calificaciones
- Presupuesto de materia prima A y BDocumento5 páginasPresupuesto de materia prima A y BLuis DectorAún no hay calificaciones
- Tema 5Documento34 páginasTema 5Silvia Peinado LopezAún no hay calificaciones
- Sistema Corredizo Colgante para Portones PesadosDocumento2 páginasSistema Corredizo Colgante para Portones PesadosJhon SandovalAún no hay calificaciones
- Apuntes de Economia 5Documento18 páginasApuntes de Economia 5FROILANAún no hay calificaciones
- Proyecto Final BiologiaDocumento16 páginasProyecto Final BiologiaAna MoralesAún no hay calificaciones
- SC 1Documento7 páginasSC 1PrivadoAún no hay calificaciones
- PADRON LECUONA Juan Patricio Trabajo de Fin de CarreraDocumento67 páginasPADRON LECUONA Juan Patricio Trabajo de Fin de CarreraEquipo NetbotkersAún no hay calificaciones
- Ejercicio en Clases Costos 3-1Documento127 páginasEjercicio en Clases Costos 3-1Dory MirandaAún no hay calificaciones
- Solicitud de Creditos Carterizados PJ BANCO VZLADocumento2 páginasSolicitud de Creditos Carterizados PJ BANCO VZLAjannaAún no hay calificaciones
- Factura Predial - Agosto-2021Documento1 páginaFactura Predial - Agosto-2021Eileen Dayana DayiAún no hay calificaciones
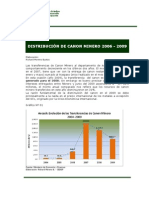
- Canon Minero Ancash 2006-2009Documento12 páginasCanon Minero Ancash 2006-2009jsegura28Aún no hay calificaciones
- Kosten Suess SRL AfipDocumento1 páginaKosten Suess SRL AfipIvan Yasinski PilaraAún no hay calificaciones
- Dossier Tacna Dic21Documento11 páginasDossier Tacna Dic21Wesley RivalditoAún no hay calificaciones
- Tablas y Tarifas ISR 2022 (Anexo 8 Versión Anticipada)Documento49 páginasTablas y Tarifas ISR 2022 (Anexo 8 Versión Anticipada)ANAAún no hay calificaciones
- Sistemas Económicos y Evolución del PensamientoDocumento24 páginasSistemas Económicos y Evolución del PensamientoAbel TorrejónAún no hay calificaciones
- 0006 Kirzner - La Oferta y La DemandaDocumento7 páginas0006 Kirzner - La Oferta y La Demandajmcs83Aún no hay calificaciones
- Declaración Renta 2017 - 2113626965880Documento1 páginaDeclaración Renta 2017 - 2113626965880Agrounion PlantacionAún no hay calificaciones
- Cuadro ResumenDocumento2 páginasCuadro ResumenMarielly ZelayaAún no hay calificaciones
- Presentación 1Documento8 páginasPresentación 1Micaela Zarate GagoAún no hay calificaciones
- Mongrafia CuartoDocumento3 páginasMongrafia CuartoRICO KANA TORRESAún no hay calificaciones
- Alianzas estratégicas y asociaciones para cadenas de valorDocumento11 páginasAlianzas estratégicas y asociaciones para cadenas de valorHumberto Pini100% (1)
- Chocolate para TiDocumento30 páginasChocolate para TiAngela SalgadoAún no hay calificaciones
- Caso 11 - DocDocumento7 páginasCaso 11 - DocJosé Stalin Dávila MegoAún no hay calificaciones