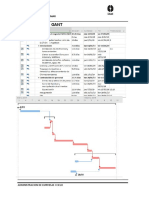
También podría gustarte
- Fundamentos De ProgramaciónDe EverandFundamentos De ProgramaciónCalificación: 5 de 5 estrellas5/5 (2)
- Diseño y construcción de algoritmosDe EverandDiseño y construcción de algoritmosCalificación: 4 de 5 estrellas4/5 (6)
- Algoritmos Genéticos con Python: Un enfoque práctico para resolver problemas de ingenieríaDe EverandAlgoritmos Genéticos con Python: Un enfoque práctico para resolver problemas de ingenieríaCalificación: 5 de 5 estrellas5/5 (5)
- Prácticas de redes de datos e industrialesDe EverandPrácticas de redes de datos e industrialesCalificación: 4 de 5 estrellas4/5 (5)
- El camino a las redes neuronales artificialesDe EverandEl camino a las redes neuronales artificialesAún no hay calificaciones
- Ejercicios Productos NotablesDocumento2 páginasEjercicios Productos NotablesVictor Hugo BustamanteAún no hay calificaciones
- Taller de PythonDocumento85 páginasTaller de PythonCarmen Alonso BellidoAún no hay calificaciones
- PALABRAS PARA LECTURA Aprende Con CamilitaDocumento26 páginasPALABRAS PARA LECTURA Aprende Con Camilitawilli machacaAún no hay calificaciones
- Proyecto Final Papas 12.04.23 NuevoDocumento22 páginasProyecto Final Papas 12.04.23 NuevoAxel Mallqui ricse100% (1)
- Activity Template - Stakeholder AnalysisDocumento2 páginasActivity Template - Stakeholder AnalysisalexAún no hay calificaciones
- Introducción Al Psoc5Lp: Teoría y aplicaciones prácticaDe EverandIntroducción Al Psoc5Lp: Teoría y aplicaciones prácticaAún no hay calificaciones
- Guia Estados Del ArteDocumento70 páginasGuia Estados Del ArteIsabel Rodríguez LópezAún no hay calificaciones
- Practico 3Documento8 páginasPractico 3Diana Parra SalazarAún no hay calificaciones
- Estructuras de Datos y Algoritmos (UNED) - DIseño y Análisis de AlgoritmosDocumento106 páginasEstructuras de Datos y Algoritmos (UNED) - DIseño y Análisis de AlgoritmosecconesaAún no hay calificaciones
- Estructuras de Datos y Algoritmos UNED DIseno y Analisis de AlgoritmosDocumento106 páginasEstructuras de Datos y Algoritmos UNED DIseno y Analisis de AlgoritmosAnonymous FZNn6rBAún no hay calificaciones
- Estructura de datos: Un enfoque con Python, java y C++De EverandEstructura de datos: Un enfoque con Python, java y C++Aún no hay calificaciones
- Análisis de Algoritmos ParalelosDocumento44 páginasAnálisis de Algoritmos ParalelososemavAún no hay calificaciones
- Adonais y Otros PoemasDocumento62 páginasAdonais y Otros PoemasItalo Zeballos Leiva100% (3)
- Analisis de Algoritmos ParalelosDocumento38 páginasAnalisis de Algoritmos ParalelosVictor Hugo BustamanteAún no hay calificaciones
- Analisis de AlgoritmosDocumento35 páginasAnalisis de AlgoritmosLuis ZevallosAún no hay calificaciones
- RendimientoDocumento41 páginasRendimientoAl Ber To100% (1)
- Analisis de Algoritmos Computacionales - Ricardo Faria - 23-EIST-6-019Documento13 páginasAnalisis de Algoritmos Computacionales - Ricardo Faria - 23-EIST-6-019Sonic AmateurAún no hay calificaciones
- Rendimiento de Sistemas ParalelosDocumento34 páginasRendimiento de Sistemas ParalelosEnrique FloresAún no hay calificaciones
- Entrega FinalDocumento11 páginasEntrega FinalAna Milena DiazAún no hay calificaciones
- 02 - Guia Lab - ELT-304JTP - Lenguajes y AlgoritmosDocumento5 páginas02 - Guia Lab - ELT-304JTP - Lenguajes y AlgoritmosBryan alex CegalisAún no hay calificaciones
- Problema Raro-7-JhoelDocumento11 páginasProblema Raro-7-Jhoeldinel snyderAún no hay calificaciones
- 4 - Análisis de AlgorítmosDocumento42 páginas4 - Análisis de AlgorítmosmariaAún no hay calificaciones
- PEC3 20211 SolucionDocumento7 páginasPEC3 20211 SolucionpampamAún no hay calificaciones
- Algoritmos y AnalisisDocumento11 páginasAlgoritmos y AnalisisJoseph MoneyAún no hay calificaciones
- Entrega 3 Sistemas DistribuidosDocumento9 páginasEntrega 3 Sistemas DistribuidosOrlando Alcala Vargas100% (1)
- Ricart y AgrawalaDocumento20 páginasRicart y Agrawalagustavo vilca adcoAún no hay calificaciones
- Tema Algoritmos 2024Documento75 páginasTema Algoritmos 2024Daniel Robinson GutierrezAún no hay calificaciones
- Actividad Pg2fsoc 2022Documento4 páginasActividad Pg2fsoc 2022Liseth MantillaAún no hay calificaciones
- Complejidad AlgoritmicaDocumento32 páginasComplejidad AlgoritmicaMariaYornetAún no hay calificaciones
- Manual de Python, Mathlab y LatexDocumento28 páginasManual de Python, Mathlab y LatexDaniel Valencia CorderoAún no hay calificaciones
- Ejercicios Exercises U3 U4 U5Documento12 páginasEjercicios Exercises U3 U4 U5Hatapro Abaran SaidAún no hay calificaciones
- CP Trabajo de Investigacion Unidad 1 EJ2022Documento11 páginasCP Trabajo de Investigacion Unidad 1 EJ2022Juan Jose Jefferson GutierrezAún no hay calificaciones
- 1 2 A ComputacionParalelaDocumento23 páginas1 2 A ComputacionParalelaGilder Reyes TuctoAún no hay calificaciones
- P3 - Analisis de AlgoritmosDocumento35 páginasP3 - Analisis de AlgoritmosGabriel GarcíaAún no hay calificaciones
- 1313Documento16 páginas1313Alex Cardona ChavezAún no hay calificaciones
- 1313Documento16 páginas1313alexAún no hay calificaciones
- 1.3análisis de Algoritmos ParalelosDocumento39 páginas1.3análisis de Algoritmos ParalelosLa Rana FrikiAún no hay calificaciones
- DiapositivaDocumento21 páginasDiapositivaRusbel MarteAún no hay calificaciones
- Actividad 3Documento15 páginasActividad 3Emanuel MontoyaAún no hay calificaciones
- Pec3 20211Documento6 páginasPec3 20211pampamAún no hay calificaciones
- 03 Daa PAlgoritmos RecursivosDocumento6 páginas03 Daa PAlgoritmos RecursivosDiana BardónAún no hay calificaciones
- Tema1-Analisis - Algoritmos 2014Documento34 páginasTema1-Analisis - Algoritmos 2014Asdasd DasdasdasdAún no hay calificaciones
- Complejidad AlgoritmicaDocumento76 páginasComplejidad AlgoritmicaUserbynn ThunderAún no hay calificaciones
- Cisco CCNA E1 - 11 - 4 - 3 - 3 SkillsDocumento10 páginasCisco CCNA E1 - 11 - 4 - 3 - 3 SkillsMakokhanAún no hay calificaciones
- Clase 9 - Programacin Concurrente - 2021Documento41 páginasClase 9 - Programacin Concurrente - 2021sdlbssoAún no hay calificaciones
- SEPARATA1 - Sistemas OperativosDocumento116 páginasSEPARATA1 - Sistemas Operativosxitofu100% (5)
- Ejercicios Tema 2Documento14 páginasEjercicios Tema 2testAún no hay calificaciones
- Distrib 03 Descomposicion - de - Tareas 2022Documento62 páginasDistrib 03 Descomposicion - de - Tareas 2022Dante CoCAún no hay calificaciones
- Algoritmos y ProgramaciónDocumento13 páginasAlgoritmos y ProgramacióndanielaAún no hay calificaciones
- Analisis de Complejidad - Parte I PDFDocumento10 páginasAnalisis de Complejidad - Parte I PDFRaysaDiazAún no hay calificaciones
- Tarea ASO-UD02 Perez Saa JoseDocumento11 páginasTarea ASO-UD02 Perez Saa JoseJosé Pérez SaaAún no hay calificaciones
- Practica UnoDocumento14 páginasPractica UnoEdgar MartinezAún no hay calificaciones
- Unidad 7 Analisis de Los Algoritmos (OAG)Documento14 páginasUnidad 7 Analisis de Los Algoritmos (OAG)Osvaldo Apolinar100% (4)
- Semana 5Documento26 páginasSemana 5Gilner PapaAún no hay calificaciones
- Actividad Evaluativa 1 - Adriana TorresDocumento9 páginasActividad Evaluativa 1 - Adriana TorresAdriana TorresAún no hay calificaciones
- Examen SO FDI UCM Feb-2021-CDocumento7 páginasExamen SO FDI UCM Feb-2021-CNacho N S KAún no hay calificaciones
- Procesamiento MultimediaDocumento13 páginasProcesamiento MultimediaJose Luis EspinosaAún no hay calificaciones
- Notacion o GrandeDocumento17 páginasNotacion o GrandePedro Ortiz ChiAún no hay calificaciones
- Ejercicios Algoritmos PlanifDocumento5 páginasEjercicios Algoritmos PlanifNico LeivaAún no hay calificaciones
- EsquemasAlgoritmicosParalelos PDFDocumento22 páginasEsquemasAlgoritmicosParalelos PDFVictor Hugo BustamanteAún no hay calificaciones
- PPR Tema2 ParalelizarTareasDocumento91 páginasPPR Tema2 ParalelizarTareasVictor Hugo BustamanteAún no hay calificaciones
- EsquemasAlgoritmicosParalelos PDFDocumento22 páginasEsquemasAlgoritmicosParalelos PDFVictor Hugo BustamanteAún no hay calificaciones
- 01 0 FundamentosDocumento24 páginas01 0 FundamentosVictor Hugo BustamanteAún no hay calificaciones
- Condiciones para El Paralelismo. DependenciasDocumento29 páginasCondiciones para El Paralelismo. DependenciasVictor Hugo BustamanteAún no hay calificaciones
- Condiciones para El Paralelismo. DependenciasDocumento29 páginasCondiciones para El Paralelismo. DependenciasVictor Hugo BustamanteAún no hay calificaciones
- CONSIGNA FINAL 1 - Informe de Vigilancia TecnológicaDocumento6 páginasCONSIGNA FINAL 1 - Informe de Vigilancia TecnológicaVictor Hugo BustamanteAún no hay calificaciones
- Plan Estudios 2015Documento6 páginasPlan Estudios 2015Victor Hugo BustamanteAún no hay calificaciones
- Administracion de Personal y OursourcingDocumento1 páginaAdministracion de Personal y OursourcingVictor Hugo BustamanteAún no hay calificaciones
- Sesionaprendizaje 30 Minutos ExamenDocumento4 páginasSesionaprendizaje 30 Minutos ExamenVictor Hugo BustamanteAún no hay calificaciones
- Informe Sistema de TramitesDocumento3 páginasInforme Sistema de TramitesJorge Chipana CarpioAún no hay calificaciones
- HISTERISISDocumento5 páginasHISTERISISAlfredo Perez FallaAún no hay calificaciones
- PARCIAL de ConsultorioDocumento11 páginasPARCIAL de ConsultorioFranco GarnicaAún no hay calificaciones
- Cuestionario #1Documento6 páginasCuestionario #1Gabriela GrandesAún no hay calificaciones
- Sal U1 A3 DangDocumento10 páginasSal U1 A3 Dangdaniel israel nava garciaAún no hay calificaciones
- Tipos y Clasificación de Los Aceites LubricantesDocumento2 páginasTipos y Clasificación de Los Aceites LubricantesHazael castillo rosasAún no hay calificaciones
- Pedro CUESTINARIO DOCENTES - S2Documento3 páginasPedro CUESTINARIO DOCENTES - S2Micaela Leyva PerezAún no hay calificaciones
- Trabajo Final Publicidad 2Documento2 páginasTrabajo Final Publicidad 2yamiletAún no hay calificaciones
- P-SI-005 - V2.docx ProcedimientoDocumento6 páginasP-SI-005 - V2.docx ProcedimientoAmparo Rodriguez GarciaAún no hay calificaciones
- Vector Normal A Una Superficie Parametria SuaveDocumento3 páginasVector Normal A Una Superficie Parametria SuaveSofia Karolina Quiroz NombertoAún no hay calificaciones
- HP SimDocumento25 páginasHP Simkaly20Aún no hay calificaciones
- Metrado de CaptacionDocumento10 páginasMetrado de CaptacionOPDUR SAN MATEOAún no hay calificaciones
- 13la Mediatriz de Un Segmento Es La Línea Recta Perpendicular A Dicho Segmento Trazada Por Su Punto MedioDocumento4 páginas13la Mediatriz de Un Segmento Es La Línea Recta Perpendicular A Dicho Segmento Trazada Por Su Punto MedioJamil Jaquez SilverioAún no hay calificaciones
- Actividad de Aprendizaje 2. Plan de NegocioDocumento6 páginasActividad de Aprendizaje 2. Plan de NegocioHernandez BvhAún no hay calificaciones
- Recoverd PDFDocumento62 páginasRecoverd PDFOscar ZapataAún no hay calificaciones
- Guia Prestadores 1470 PDFDocumento14 páginasGuia Prestadores 1470 PDFCristian MorenoAún no hay calificaciones
- Empaques y Embalaje PDFDocumento17 páginasEmpaques y Embalaje PDFIrlena CoronellAún no hay calificaciones
- Factores Que Inhiben Participacion Padres Familia Proceso EducativoDocumento46 páginasFactores Que Inhiben Participacion Padres Familia Proceso EducativoTania Rodriguez100% (3)
- EducamosCLM Seguimiento EducativoDocumento1 páginaEducamosCLM Seguimiento EducativoJuan José Bernal ParraAún no hay calificaciones
- Empresa Agroindustrial Pomalca S.A.ADocumento11 páginasEmpresa Agroindustrial Pomalca S.A.ASamuel BarraganAún no hay calificaciones
- Planillas de Mantenimiento de MáquinasDocumento11 páginasPlanillas de Mantenimiento de MáquinasAnonymous 4lIAJ1Lk2Aún no hay calificaciones
- Experimento#1 Fisica LabDocumento7 páginasExperimento#1 Fisica LabIvanna TiburcioAún no hay calificaciones
- Fallo Ryan Tuccillo C CencosudDocumento25 páginasFallo Ryan Tuccillo C CencosudJorge EirisAún no hay calificaciones
- Actividad Estadistica Eje # 2Documento14 páginasActividad Estadistica Eje # 2Jeismar TellezAún no hay calificaciones
- Aviso de Privacidad Sitio Web IntegralDocumento6 páginasAviso de Privacidad Sitio Web IntegralAna Paula FloresAún no hay calificaciones
- DelimitacionDocumento18 páginasDelimitacionmiguel angel condori chambiAún no hay calificaciones