También podría gustarte
- Guía Básica KismetDocumento15 páginasGuía Básica KismetgtranAún no hay calificaciones
- Base de Datos en Android ReporteDocumento40 páginasBase de Datos en Android ReportePaisa Rodriguez RojasAún no hay calificaciones
- Conocimientos y Responsabilidades Del DBA 2Documento12 páginasConocimientos y Responsabilidades Del DBA 2lobo1973Aún no hay calificaciones
- Oracle PDFDocumento136 páginasOracle PDFJoellMoisesMonteroJimenezAún no hay calificaciones
- Presentacion Plan de MantenimientoDocumento11 páginasPresentacion Plan de MantenimientoMaria FernandaAún no hay calificaciones
- Cuestionario Cobit 5Documento4 páginasCuestionario Cobit 5elizabeth minaguaAún no hay calificaciones
- Informe Actividad 2Documento5 páginasInforme Actividad 2José Ebdalí Peña PeñaAún no hay calificaciones
- Tema 2 - Instalación y Configuración de ERPCRM - OdgDocumento50 páginasTema 2 - Instalación y Configuración de ERPCRM - Odgdrokz100% (1)
- Fases SDLDocumento9 páginasFases SDLLuis MoralesAún no hay calificaciones
- Modelo Informeproyecto SigDocumento46 páginasModelo Informeproyecto SigJaime Bedón GonzalesAún no hay calificaciones
- Manual Practico Capacitacion GrailsDocumento26 páginasManual Practico Capacitacion GrailsMilton AlvaradoAún no hay calificaciones
- Informe Software GlpiDocumento19 páginasInforme Software GlpiAsistente SistemasAún no hay calificaciones
- InfografíaDocumento1 páginaInfografíamarvin arguinzones100% (2)
- Report e AdoresDocumento22 páginasReport e AdoresErika Rodriguez100% (1)
- Guia - Artefactos - 2 - Fase Planificación y EstimaciónDocumento61 páginasGuia - Artefactos - 2 - Fase Planificación y EstimaciónAracely NuñezAún no hay calificaciones
- Checklist Ds Cawa v1.0Documento3 páginasChecklist Ds Cawa v1.0Italo HeviaAún no hay calificaciones
- PPTs - Curso Básico GeneXusDocumento248 páginasPPTs - Curso Básico GeneXusvsalazar11Aún no hay calificaciones
- Pasos para Crear Un Applet Con NetbeansDocumento5 páginasPasos para Crear Un Applet Con NetbeansLizeth BenavidesAún no hay calificaciones
- Tipos Especificos de SI CRM ERP SCM WFDocumento53 páginasTipos Especificos de SI CRM ERP SCM WFgloria casillaAún no hay calificaciones
- Instalación SAI Móvil - 2013Documento22 páginasInstalación SAI Móvil - 2013Felipe najeraAún no hay calificaciones
- Sílabo Taller de Proyectos 2 - Ingeniería de Sistemas e InformáticaDocumento5 páginasSílabo Taller de Proyectos 2 - Ingeniería de Sistemas e InformáticaEliza Flores HAún no hay calificaciones
- 1.3.3 Lab - Python Programming ReviewDocumento16 páginas1.3.3 Lab - Python Programming ReviewWill D. Gómez VegaAún no hay calificaciones
- APLICACIONES PARA MONITOREO-cuadro ComparativoDocumento16 páginasAPLICACIONES PARA MONITOREO-cuadro ComparativoIbarra SilAún no hay calificaciones
- Funciones nivel servidor SQLDocumento4 páginasFunciones nivel servidor SQLMithsuhiro PampañaupaAún no hay calificaciones
- Guia09 Laravel PrimeraAplicaciónDocumento8 páginasGuia09 Laravel PrimeraAplicaciónNohemi SalceAún no hay calificaciones
- Actualizar OnBase beneficios soporte seguridadDocumento7 páginasActualizar OnBase beneficios soporte seguridadkingsoftAún no hay calificaciones
- Metodologia Del RadDocumento4 páginasMetodologia Del RadPoulsen GuerreroAún no hay calificaciones
- Uso de ColeccionesDocumento3 páginasUso de ColeccionesCindy DiazAún no hay calificaciones
- Ejemplo de Encuesta de Evaluación SoftwareDocumento3 páginasEjemplo de Encuesta de Evaluación Softwaremanuel_a_flores_o5928100% (1)
- IIS vs Apache vs NGINX: Comparativa de servidores webDocumento2 páginasIIS vs Apache vs NGINX: Comparativa de servidores webIsrael FloresAún no hay calificaciones
- Conexiones Android Con Base de DatosDocumento24 páginasConexiones Android Con Base de DatosBUSTAMANTE GUERRERO FernandoAún no hay calificaciones
- Taller 1 Tipos de Base de DatosDocumento6 páginasTaller 1 Tipos de Base de DatosMIGUEL ANGEL VERJEL PE�ARANDAAún no hay calificaciones
- Sistemas Operativos TEMA IIIDocumento4 páginasSistemas Operativos TEMA IIIruben nsue mangueAún no hay calificaciones
- Manual TecnicoDocumento20 páginasManual TecnicoEnrique Galindo50% (2)
- CellsDocumento8 páginasCellsJhony Fernando Bartolo DíazAún no hay calificaciones
- Gobierno de TI: estructura, roles y procesos claveDocumento14 páginasGobierno de TI: estructura, roles y procesos claveAlberto CastilloAún no hay calificaciones
- Guía - Instalación DNLABDocumento12 páginasGuía - Instalación DNLABShemoro- Juan Carlos RamírezAún no hay calificaciones
- Identificacion Requerimiento Funcionales y No Funcionales.Documento3 páginasIdentificacion Requerimiento Funcionales y No Funcionales.Marcelo Alejandro Beneventi IturraAún no hay calificaciones
- Find BugsDocumento14 páginasFind BugsJuan C. GonzalezAún no hay calificaciones
- Slides-Flujo de Desarrollo Moderno CodestreamDocumento126 páginasSlides-Flujo de Desarrollo Moderno CodestreamNess ManAún no hay calificaciones
- Memoria RAM y sus funciones enDocumento7 páginasMemoria RAM y sus funciones enluisa fernandaAún no hay calificaciones
- Manual Certificacion Access 2016Documento57 páginasManual Certificacion Access 2016MarcoReynoso60% (5)
- Instalar GLPI Con Xampp para WindowsDocumento23 páginasInstalar GLPI Con Xampp para WindowsMixer-Flashback HiNrg-MexicoAún no hay calificaciones
- Estandar Programacion Sistemas IonDocumento14 páginasEstandar Programacion Sistemas Ionluis_1306Aún no hay calificaciones
- ISO 25000 PreguntasDocumento8 páginasISO 25000 PreguntasJavier EspinalesAún no hay calificaciones
- Arrays objetos Java crear 10 empleadosDocumento3 páginasArrays objetos Java crear 10 empleadosLuis García NAún no hay calificaciones
- Analisis de Sistemas de ComputoDocumento3 páginasAnalisis de Sistemas de ComputoManuelito UiAún no hay calificaciones
- Cómo Configurar RAID 5 en Ubuntu ServerDocumento15 páginasCómo Configurar RAID 5 en Ubuntu ServerFernando CahueñasAún no hay calificaciones
- Qué Es AzureDocumento9 páginasQué Es AzureHectorJhovaniOliveraAún no hay calificaciones
- Archivos Log y de BitacoraDocumento7 páginasArchivos Log y de BitacoraJosé Larssen TrujilloAún no hay calificaciones
- Tutorial de CA PLEXDocumento18 páginasTutorial de CA PLEXJeffrey Rolando Herrera Benavides100% (1)
- Para Exposiond Del Lunes 3 de Mayo Ingenieria ConcurrenteDocumento26 páginasPara Exposiond Del Lunes 3 de Mayo Ingenieria ConcurrenteJuliana PereiraAún no hay calificaciones
- ¿Son Los Dss Solo para Empresas Grandes?: Por Alejandro Guzmán y Ernesto Chávez PonzanelliDocumento5 páginas¿Son Los Dss Solo para Empresas Grandes?: Por Alejandro Guzmán y Ernesto Chávez PonzanelliWilson Ticona MullisacaAún no hay calificaciones
- Guia Artefactos Scrum 02Documento43 páginasGuia Artefactos Scrum 02Sofia AlarconAún no hay calificaciones
- Cobit5 Dss05 Gestionar Servicios de SeguridadDocumento10 páginasCobit5 Dss05 Gestionar Servicios de SeguridadJuan Fernando Ramirez AgudeloAún no hay calificaciones
- WekaDocumento8 páginasWekaJvlio Cesar Calleja MorenoAún no hay calificaciones
- Gonzalorojas 08 U M L Diagramas de Secuencia177Documento7 páginasGonzalorojas 08 U M L Diagramas de Secuencia177wango12kAún no hay calificaciones
- Informe Tutorial IotDocumento27 páginasInforme Tutorial IotvitoAún no hay calificaciones
- Bases de Datos PDFDocumento40 páginasBases de Datos PDFFrancisco Javier Mingo VelázquezAún no hay calificaciones
- Practica de Web Scraping PDFDocumento14 páginasPractica de Web Scraping PDFEunice LeyvaAún no hay calificaciones
- Estadística aplicada a ingeniería de sistemasDocumento13 páginasEstadística aplicada a ingeniería de sistemasLucitaCastilloAún no hay calificaciones
- Análisis FODA Importaciones Hiraoka menos deDocumento2 páginasAnálisis FODA Importaciones Hiraoka menos deLucitaCastilloAún no hay calificaciones
- Diagnóstico y Tratamiento Del CovidDocumento8 páginasDiagnóstico y Tratamiento Del CovidLucitaCastilloAún no hay calificaciones
- Capas Del Protocolo TCPDocumento2 páginasCapas Del Protocolo TCPLucitaCastilloAún no hay calificaciones
- 01 Economia PracticaDocumento13 páginas01 Economia PracticaLucitaCastilloAún no hay calificaciones
- Router y SwitchDocumento2 páginasRouter y SwitchLucitaCastilloAún no hay calificaciones
- Capas Del Protocolo TCPDocumento2 páginasCapas Del Protocolo TCPLucitaCastilloAún no hay calificaciones
- Procedimiento Reingreso UNACDocumento2 páginasProcedimiento Reingreso UNACCesar Alberto Verastegui ZapataAún no hay calificaciones
- Caso Pract - Patrim. Neto 2Documento3 páginasCaso Pract - Patrim. Neto 2LucitaCastilloAún no hay calificaciones
- Necesidad y ExpectativaDocumento1 páginaNecesidad y ExpectativaLucitaCastilloAún no hay calificaciones
- DISPOSITIVOS DE Entrada y SalidaDocumento10 páginasDISPOSITIVOS DE Entrada y SalidaLucitaCastilloAún no hay calificaciones
- 01 Economia General PracticaDocumento13 páginas01 Economia General PracticaJose Luis Fernandez GamarraAún no hay calificaciones
- ArquiDocumento3 páginasArquiLucitaCastilloAún no hay calificaciones
- Capas Del Protocolo TCPDocumento2 páginasCapas Del Protocolo TCPLucitaCastilloAún no hay calificaciones
- Que Es El IsoDocumento1 páginaQue Es El IsoLucitaCastilloAún no hay calificaciones
- ChileDocumento1 páginaChileLucitaCastilloAún no hay calificaciones
- Manual de UsuarioDocumento8 páginasManual de Usuariocristhian lopezAún no hay calificaciones
- 01 Economia General PracticaDocumento13 páginas01 Economia General PracticaJose Luis Fernandez GamarraAún no hay calificaciones
- Estructura de Trabajos AnalisisDocumento2 páginasEstructura de Trabajos AnalisisLucitaCastilloAún no hay calificaciones
- ISO 27035 Gestión Incidentes Seguridad InformaciónDocumento2 páginasISO 27035 Gestión Incidentes Seguridad InformaciónLucitaCastilloAún no hay calificaciones
- Casos de UsoDocumento52 páginasCasos de UsoKelvin FloresAún no hay calificaciones
- Capitulo 2Documento55 páginasCapitulo 2YenAún no hay calificaciones
- Procedimiento Reingreso UNACDocumento2 páginasProcedimiento Reingreso UNACCesar Alberto Verastegui ZapataAún no hay calificaciones
- Iso 31000 - 27035Documento5 páginasIso 31000 - 27035LucitaCastilloAún no hay calificaciones
- Tema: Arquitectura de Telefonos Moviles 4GDocumento9 páginasTema: Arquitectura de Telefonos Moviles 4GLucitaCastilloAún no hay calificaciones
- Tema: Arquitectura de Telefonos Moviles 4GDocumento9 páginasTema: Arquitectura de Telefonos Moviles 4GLucitaCastilloAún no hay calificaciones
- 01 Economia General PracticaDocumento13 páginas01 Economia General PracticaJose Luis Fernandez GamarraAún no hay calificaciones
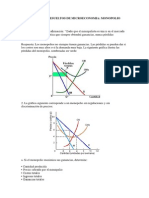
- Ejercicios Resueltos Microeconomia - MonopolioDocumento22 páginasEjercicios Resueltos Microeconomia - Monopoliojuanito_77100% (4)
- Estructura de Trabajos AnalisisDocumento2 páginasEstructura de Trabajos AnalisisLucitaCastilloAún no hay calificaciones
- Silbana BarrazaDocumento2 páginasSilbana BarrazaAleja MendozaAún no hay calificaciones
- Edicion 598 - 30 de Enero Del 2009 - 192 PagsDocumento192 páginasEdicion 598 - 30 de Enero Del 2009 - 192 PagsFÉLIX BAUTISTA BENDEZÚAún no hay calificaciones
- Exp.3 Caracterización de Pulpas Minerales PmiDocumento6 páginasExp.3 Caracterización de Pulpas Minerales PmiYenniffer Ivette Lopez RomeroAún no hay calificaciones
- NTC4398 PDFDocumento11 páginasNTC4398 PDFMeluColoradoAún no hay calificaciones
- Tipos de fuego y extinguidores enDocumento4 páginasTipos de fuego y extinguidores enGerman MartinezAún no hay calificaciones
- Respuestas Del Examen 6ºDocumento5 páginasRespuestas Del Examen 6ºeywerywery60% (5)
- Acta ConstitutivaDocumento6 páginasActa ConstitutivaGregorio RivasAún no hay calificaciones
- Fórmulas y funciones básicas en ExcelDocumento3 páginasFórmulas y funciones básicas en ExcelMaríaAún no hay calificaciones
- Parametros UrbanisticosDocumento7 páginasParametros UrbanisticosTrwWertAún no hay calificaciones
- 2° Informe Quincenal PDFDocumento5 páginas2° Informe Quincenal PDFAlex ZapataAún no hay calificaciones
- Evaluacion Final - Escenario 8 - PRIMER BLOQUE-TEORICO - ETICA EMPRESARIAL - (GRUPO1)Documento6 páginasEvaluacion Final - Escenario 8 - PRIMER BLOQUE-TEORICO - ETICA EMPRESARIAL - (GRUPO1)erikaAún no hay calificaciones
- Cinética de Reacciones y Ley de ArrheniusDocumento7 páginasCinética de Reacciones y Ley de ArrheniusDámaris Urquidi HernándezAún no hay calificaciones
- 3.3 Estimación de CostosDocumento4 páginas3.3 Estimación de Costosmery ruizAún no hay calificaciones
- Ensayo 2Documento7 páginasEnsayo 2Elizabeeth MoralessAún no hay calificaciones
- La participación política en ChileDocumento25 páginasLa participación política en ChileRodrigo ParedesAún no hay calificaciones
- Práctica ReometriaDocumento10 páginasPráctica ReometriaAlberto Arteaga50% (2)
- Manual Mach 10Documento23 páginasManual Mach 10LaarsAún no hay calificaciones
- Giancarlo VelasquezDocumento2 páginasGiancarlo VelasquezAlexa Velasquez AbadAún no hay calificaciones
- Actividad-3-Demanda INDIVIDUALDocumento18 páginasActividad-3-Demanda INDIVIDUALdaniela salgadoAún no hay calificaciones
- Clase 8 Practicas de Conservacion de SuelosDocumento53 páginasClase 8 Practicas de Conservacion de SuelosDoris SuarezAún no hay calificaciones
- ESPECIFICACIONES - INTERRUPTOR 115kVDocumento15 páginasESPECIFICACIONES - INTERRUPTOR 115kVmrivero1983100% (1)
- Derecho Ii: "Fusión, Transformación, Disolución y Liquidación de Sociedades Mercantiles "Documento4 páginasDerecho Ii: "Fusión, Transformación, Disolución y Liquidación de Sociedades Mercantiles "MARIA GRACIA MAGANA GALARZAAún no hay calificaciones
- Resumen Ejecutivo Perfil I.E. Casa BlancaDocumento28 páginasResumen Ejecutivo Perfil I.E. Casa BlancaJose Luis Cerron NastaresAún no hay calificaciones
- Simulacion y Metodo de MontecarloDocumento9 páginasSimulacion y Metodo de MontecarloPedro ChavezAún no hay calificaciones
- 4WD TransmisionDocumento28 páginas4WD TransmisionMatias IbarraAún no hay calificaciones
- IAAC MD 036 IAF MD 10 2013 (REV 01) Manejo de Competencias OCDocumento14 páginasIAAC MD 036 IAF MD 10 2013 (REV 01) Manejo de Competencias OCPatricia CondoriAún no hay calificaciones
- Puertos de Panamá GeneralidadesDocumento7 páginasPuertos de Panamá GeneralidadesCastillo Montenegro KeisyAún no hay calificaciones
- SUMILLADocumento9 páginasSUMILLAEmilioVargasAún no hay calificaciones
- Trabajo Gerencia Estrategica Hampm 2Documento6 páginasTrabajo Gerencia Estrategica Hampm 2Mayerly Andrea Forero CarcamoAún no hay calificaciones
- Reforzamiento Con FRP de Elementos de Concreto ArmadoDocumento24 páginasReforzamiento Con FRP de Elementos de Concreto ArmadoJorge BazánAún no hay calificaciones