También podría gustarte
- UF2215 - Herramientas de los sistemas gestores de bases de datos. Pasarelas y medios de conexiónDe EverandUF2215 - Herramientas de los sistemas gestores de bases de datos. Pasarelas y medios de conexiónAún no hay calificaciones
- 3.4 Diseño de Base de DatosDocumento21 páginas3.4 Diseño de Base de DatosCharo CruzAún no hay calificaciones
- Base de Datos - Modelado de DatosDocumento5 páginasBase de Datos - Modelado de DatosNadia GonzalezAún no hay calificaciones
- Fase para El Desarrollo Enrique (Computacion)Documento6 páginasFase para El Desarrollo Enrique (Computacion)Edwin LorenzoAún no hay calificaciones
- Diseño Bases DatosDocumento18 páginasDiseño Bases DatosEdwin GallegosAún no hay calificaciones
- Unidad 1 BD. Introducción a las Bases de DatosDocumento4 páginasUnidad 1 BD. Introducción a las Bases de Datosmanoliyogarcia18Aún no hay calificaciones
- Base de Datos I ClaseDocumento16 páginasBase de Datos I ClaseedwinmierAún no hay calificaciones
- Creación de La Estructura de La BD y Aplicación de Restricciones.Documento5 páginasCreación de La Estructura de La BD y Aplicación de Restricciones.salazarjhonalejandro22Aún no hay calificaciones
- V2-MP - 0484 - UF1 - WBT2 - Diseño de Bases de Datos RelacionalesDocumento12 páginasV2-MP - 0484 - UF1 - WBT2 - Diseño de Bases de Datos RelacionalesRubenAsecaSecasAún no hay calificaciones
- ArquitecturaDBDocumento5 páginasArquitecturaDBJohan RiveroAún no hay calificaciones
- Diseño Fisico BDADocumento2 páginasDiseño Fisico BDAAlejandro MartinezAún no hay calificaciones
- Diseño Conceptual de Una Base de DatosDocumento20 páginasDiseño Conceptual de Una Base de Datosbroma tresAún no hay calificaciones
- MBBDD SqlsDocumento15 páginasMBBDD SqlsKlinton PovesAún no hay calificaciones
- Jose Garcia Unidad2Documento4 páginasJose Garcia Unidad2Jairo Jeremias García GuzmánAún no hay calificaciones
- ACA 3 - Base de DatosDocumento13 páginasACA 3 - Base de DatosADRIANA PAOLA AVILA TORRIJOSAún no hay calificaciones
- Trabajo FinalDocumento30 páginasTrabajo FinalFABELA MERCADO MARYAM ANDREAAún no hay calificaciones
- SGBDDocumento16 páginasSGBDJøel Silva El CachørrøAún no hay calificaciones
- Investigacion Base de DatosDocumento12 páginasInvestigacion Base de DatosdffdfsdAún no hay calificaciones
- Monografia BaseDatosMariaDBDocumento28 páginasMonografia BaseDatosMariaDBMike WasouskiAún no hay calificaciones
- Diseño de Base de DatosDocumento11 páginasDiseño de Base de DatosTeresita XalapaAún no hay calificaciones
- Introducción Al Diseño de Bases de DatosDocumento251 páginasIntroducción Al Diseño de Bases de Datoshecx sazAún no hay calificaciones
- Conceptos Básicos Data WareHouse Por B. GomezDocumento6 páginasConceptos Básicos Data WareHouse Por B. GomezBernardo Nijarec Gómez RizoAún no hay calificaciones
- Trabajo de Pueba Sustituto 311 Bade de Datos Universidad Nacional AbiertaDocumento6 páginasTrabajo de Pueba Sustituto 311 Bade de Datos Universidad Nacional AbiertaDanielo AguAún no hay calificaciones
- DBDesigner y PHPMyAdminDocumento20 páginasDBDesigner y PHPMyAdminDATOS100Aún no hay calificaciones
- Principios Base de DatosDocumento9 páginasPrincipios Base de DatosAlexanderAún no hay calificaciones
- Ensayo Diseño de Sistemas Bases de Datos Aplicado Al Diseño de SistemaDocumento10 páginasEnsayo Diseño de Sistemas Bases de Datos Aplicado Al Diseño de SistemavictorAún no hay calificaciones
- Criterios de selección de un SMBDDocumento9 páginasCriterios de selección de un SMBDIng Osqaro GómezAún no hay calificaciones
- Foro Temático 4Documento2 páginasForo Temático 4Victor Javier Cuero VegaAún no hay calificaciones
- Diana Laura Millan Morales 1867 Assignsubmission File Unidad I ABDDocumento15 páginasDiana Laura Millan Morales 1867 Assignsubmission File Unidad I ABDKristell MirandaAún no hay calificaciones
- Modelado de Datos y Diseño de Base de DatoDocumento8 páginasModelado de Datos y Diseño de Base de DatoBianca SykessAún no hay calificaciones
- Actividad01 Unidad02 FundamentosdeBasesdeDatos 20300698Documento17 páginasActividad01 Unidad02 FundamentosdeBasesdeDatos 20300698natividad hernandez alvarezAún no hay calificaciones
- GBD Tema01Documento8 páginasGBD Tema01danielmayenjimenezAún no hay calificaciones
- Fundamentos de Base de DatosDocumento55 páginasFundamentos de Base de DatosEdna AraqueAún no hay calificaciones
- TEMA 1. DISEÑO DE BASES DE DATOS RELACIONALES Apuntes Del TemaDocumento36 páginasTEMA 1. DISEÑO DE BASES DE DATOS RELACIONALES Apuntes Del TemajoseAún no hay calificaciones
- DDBD U1 A2 JubpDocumento18 páginasDDBD U1 A2 JubpGabriel BalderasAún no hay calificaciones
- Mia 311 2Documento10 páginasMia 311 2warriorbardAún no hay calificaciones
- Investigación - Monografíca - Diseño de Base de DatosDocumento20 páginasInvestigación - Monografíca - Diseño de Base de DatosAgustín Puma FernándezAún no hay calificaciones
- Sesión 1 MDBDDocumento42 páginasSesión 1 MDBDchat gptAún no hay calificaciones
- Guia Teorica 2 Bases de DatosDocumento20 páginasGuia Teorica 2 Bases de DatosJohn ParkerAún no hay calificaciones
- Arquitectura de Base de DatosDocumento7 páginasArquitectura de Base de DatosRuth Mora HernandezAún no hay calificaciones
- Introducción a Bases de DatosDocumento24 páginasIntroducción a Bases de DatosGeovanny RodasAún no hay calificaciones
- Implementación Del Esquema Interno (Nivel Físico) .Documento4 páginasImplementación Del Esquema Interno (Nivel Físico) .Pepe TorresAún no hay calificaciones
- Fundamentos de Bases de DatosDocumento46 páginasFundamentos de Bases de DatosRamiro HerreraAún no hay calificaciones
- Introducción. Ciclo de Vida de Los Sistemas de Información. Diseño ConceptualDocumento6 páginasIntroducción. Ciclo de Vida de Los Sistemas de Información. Diseño ConceptualJess FabaraAún no hay calificaciones
- DB-MODELOSDocumento11 páginasDB-MODELOSnelly yanelAún no hay calificaciones
- Universidad Autonóma de Nuevo León Facultad de Ingeniería Mecánica Y EléctricaDocumento13 páginasUniversidad Autonóma de Nuevo León Facultad de Ingeniería Mecánica Y EléctricaJonathan EspinozaAún no hay calificaciones
- Base de Datos ResumenDocumento3 páginasBase de Datos ResumenlorenaJimenezAún no hay calificaciones
- Conceptos básicos de sistemas de bases de datosDocumento12 páginasConceptos básicos de sistemas de bases de datosCarlos Eduardo Pineda JorgeAún no hay calificaciones
- Tarea 5 Jorge JuarezDocumento5 páginasTarea 5 Jorge JuarezJorge Juarez GarciaAún no hay calificaciones
- Clase 1 Diseño de Base de Datos 2020-IDocumento13 páginasClase 1 Diseño de Base de Datos 2020-IRicardo TilleroAún no hay calificaciones
- Diseño Conceptual de Una Base de DatosDocumento8 páginasDiseño Conceptual de Una Base de DatosLeandro BenitezAún no hay calificaciones
- Analisis de Base de DatosDocumento17 páginasAnalisis de Base de Datosady_gg67% (12)
- Clase 6Documento10 páginasClase 6Marilyn RodriguezAún no hay calificaciones
- Apuntes de La Clase 1 de Base de DatosDocumento7 páginasApuntes de La Clase 1 de Base de DatosAlejandro De Los Rios ArancibiaAún no hay calificaciones
- Apuntes de La U1 de Base de Datos 1Documento9 páginasApuntes de La U1 de Base de Datos 1Alejandro De Los Rios ArancibiaAún no hay calificaciones
- Bases de datos para administración de información organizacionalDocumento7 páginasBases de datos para administración de información organizacionalCatherine RiquelmeAún no hay calificaciones
- Instituto Tecnológico de Felipe Carrillo Puerto: Administración de Bases de DatosDocumento10 páginasInstituto Tecnológico de Felipe Carrillo Puerto: Administración de Bases de DatosEfra LarAún no hay calificaciones
- Capituo II. 2.1 Fases en El Desarrollo y Contruccion de Una Bases de Datos1-17Documento17 páginasCapituo II. 2.1 Fases en El Desarrollo y Contruccion de Una Bases de Datos1-17Shaina CreationzAún no hay calificaciones
- Capitulo 1 - ConnollyDocumento8 páginasCapitulo 1 - ConnollyDaniel Carrasset GómezAún no hay calificaciones
- Bases Datos Unidad 1 InvestigacionDocumento10 páginasBases Datos Unidad 1 InvestigacionJuan VilarroelAún no hay calificaciones
- Sistema MuscularDocumento8 páginasSistema MuscularEdgar dennis Mucha ColcaAún no hay calificaciones
- C# Realizando Interfaces ModernasDocumento11 páginasC# Realizando Interfaces ModernasEdgar dennis Mucha ColcaAún no hay calificaciones
- Sistema endocrino: glándulas y hormonas claveDocumento8 páginasSistema endocrino: glándulas y hormonas claveEdgar dennis Mucha ColcaAún no hay calificaciones
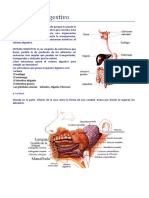
- Sistema DigestivoDocumento14 páginasSistema DigestivoEdgar dennis Mucha ColcaAún no hay calificaciones
- Sistema CirculatorioDocumento6 páginasSistema CirculatorioEdgar dennis Mucha ColcaAún no hay calificaciones
- Actividad de Aprendizaje 1Documento8 páginasActividad de Aprendizaje 1Edgar dennis Mucha ColcaAún no hay calificaciones
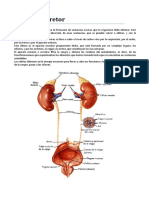
- Sistema ExcretorDocumento5 páginasSistema ExcretorEdgar dennis Mucha ColcaAún no hay calificaciones
- Actividad de Aprendizaje 4Documento12 páginasActividad de Aprendizaje 4Edgar dennis Mucha ColcaAún no hay calificaciones
- Actividad de Aprendizaje 2Documento9 páginasActividad de Aprendizaje 2Edgar dennis Mucha ColcaAún no hay calificaciones
- Actividad de Aprendizaje 2Documento9 páginasActividad de Aprendizaje 2Edgar dennis Mucha ColcaAún no hay calificaciones
- Actividad de Aprendizaje 1Documento8 páginasActividad de Aprendizaje 1Edgar dennis Mucha ColcaAún no hay calificaciones
- 06 Nivelacion MatematicaDocumento18 páginas06 Nivelacion MatematicaPaola Fernanda Taucare PeraltaAún no hay calificaciones
- Rombo NFPA ResincaDocumento10 páginasRombo NFPA ResincaYennifer GonzalezAún no hay calificaciones
- Ejemplo para Viga CoronaDocumento9 páginasEjemplo para Viga CoronaGabriel Mendoza ArauzAún no hay calificaciones
- Reseña Histórica Del Dibujo TécnicoDocumento3 páginasReseña Histórica Del Dibujo TécnicolopezfeliciaAún no hay calificaciones
- Aprender PawnDocumento48 páginasAprender Pawndiegoferreyranet100% (1)
- Curso Electronica BasicaDocumento57 páginasCurso Electronica BasicaAndres ArteagaAún no hay calificaciones
- Trabajo Con Ajax en PHP Utilizando XajaxDocumento94 páginasTrabajo Con Ajax en PHP Utilizando XajaxJonathan MoranAún no hay calificaciones
- Silva de Sirenas - Libro Primero, Libro Segundo y Libro TerceroDocumento106 páginasSilva de Sirenas - Libro Primero, Libro Segundo y Libro TerceroMau AlvaradoAún no hay calificaciones
- Evaluación Del Tren de RODAMIENTO Controle La VidaDocumento28 páginasEvaluación Del Tren de RODAMIENTO Controle La VidaEver Luis Toledo ChancaAún no hay calificaciones
- Conectar MySQL con NetBeansDocumento5 páginasConectar MySQL con NetBeansHector BautistaAún no hay calificaciones
- Transmisión de PotenciaDocumento40 páginasTransmisión de Potenciamattyas Bernal100% (2)
- PascalDocumento2 páginasPascalokearmentagarciaAún no hay calificaciones
- Procesos lácteos: leche, fermentados y mantequillaDocumento152 páginasProcesos lácteos: leche, fermentados y mantequillaAngel Camarena RosalesAún no hay calificaciones
- BalanceoDocumento3 páginasBalanceomessiAún no hay calificaciones
- 2013 Procedimiento de Sauvé-Kapandji en Los Trastornos de La Articulación Radiocubital DistalDocumento8 páginas2013 Procedimiento de Sauvé-Kapandji en Los Trastornos de La Articulación Radiocubital DistalDavid Alejandro Cavieres AcuñaAún no hay calificaciones
- Catalogo Lada NivaDocumento6 páginasCatalogo Lada NivaBeto EinsteinAún no hay calificaciones
- Ciclo Rankine Regenerativo ....Documento13 páginasCiclo Rankine Regenerativo ....Jhoel Sierra F100% (2)
- Estudio HidrologicoDocumento35 páginasEstudio HidrologicoClaudiaBacaCubaAún no hay calificaciones
- Paul DiracDocumento5 páginasPaul DiracOctavio JuarezAún no hay calificaciones
- Practica Vbnet Con AccessDocumento3 páginasPractica Vbnet Con AccessfranzepedacAún no hay calificaciones
- SCV 2016 A 01Documento20 páginasSCV 2016 A 01Saulo124Aún no hay calificaciones
- Diseño de pavimentos rígidosDocumento16 páginasDiseño de pavimentos rígidosAlexander Ponce VelardeAún no hay calificaciones
- CAPITULODocumento63 páginasCAPITULOMA MacedoAún no hay calificaciones
- Preamplificadores de Audio Con Transistores y Con Circuito Integrado, Amplificadores Operacionales EstereoDocumento4 páginasPreamplificadores de Audio Con Transistores y Con Circuito Integrado, Amplificadores Operacionales Estereojuan carlos villalonga albertAún no hay calificaciones
- Problema T-25 BaranDocumento7 páginasProblema T-25 Baranleonard coronilAún no hay calificaciones
- Expo-Nucleos IiDocumento51 páginasExpo-Nucleos IiSimon Rodrigo Rizo GonzalezAún no hay calificaciones
- 6° Semana Fluidos Reales-1Documento63 páginas6° Semana Fluidos Reales-1Gerson ChaconAún no hay calificaciones
- TALLER 2 - Monitoreo SueloDocumento5 páginasTALLER 2 - Monitoreo SueloCristhian FernandezAún no hay calificaciones
- Informe de Plantas TérmicasDocumento7 páginasInforme de Plantas TérmicasCristian Daniel Rodríguez VAún no hay calificaciones