También podría gustarte
- DocumentoDocumento1 páginaDocumentoMarioRamirezAún no hay calificaciones
- Identificación de Vulnerabilidades de La RedDocumento4 páginasIdentificación de Vulnerabilidades de La RedMarioRamirezAún no hay calificaciones
- PPP Vs HDLCDocumento1 páginaPPP Vs HDLCMarioRamirezAún no hay calificaciones
- 1-Make Mine Wireless InstructionsDocumento1 página1-Make Mine Wireless InstructionsMarioRamirezAún no hay calificaciones
- 3-Inside and Outside Control InstructionsDocumento4 páginas3-Inside and Outside Control InstructionsMarioRamirezAún no hay calificaciones
- 11.2.2.6 Lab - Researching Network Security ThreatsDocumento4 páginas11.2.2.6 Lab - Researching Network Security ThreatsBraulioGonzalezPalaciosAún no hay calificaciones
- 2-Investigating Wireless ImplementationsDocumento3 páginas2-Investigating Wireless ImplementationsMarioRamirezAún no hay calificaciones
- 2 ACT 1 - Identifying IPv4 AddressesDocumento3 páginas2 ACT 1 - Identifying IPv4 AddressesMarioRamirezAún no hay calificaciones
- 2-Investigating Wireless ImplementationsDocumento3 páginas2-Investigating Wireless ImplementationsMarioRamirezAún no hay calificaciones
- 1-Make Mine Wireless InstructionsDocumento1 página1-Make Mine Wireless InstructionsMarioRamirezAún no hay calificaciones
- 1 ACT 1 - Converting IPv4 Addresses To BinaryDocumento6 páginas1 ACT 1 - Converting IPv4 Addresses To BinaryMarioRamirezAún no hay calificaciones
- 7.1.2.9 Lab - Converting IPv4 Addresses To BinaryDocumento4 páginas7.1.2.9 Lab - Converting IPv4 Addresses To BinaryAuroth DarchrowAún no hay calificaciones
- Dificultades y Otros AspectosDocumento5 páginasDificultades y Otros AspectosMarioRamirezAún no hay calificaciones
- Practica 2 CnnaDocumento6 páginasPractica 2 CnnaMarioRamirezAún no hay calificaciones
- Redes Inalámbricas PDFDocumento1 páginaRedes Inalámbricas PDFManuel Fernando Papa YelaAún no hay calificaciones
- Infografia3xb0i02e PDFDocumento1 páginaInfografia3xb0i02e PDFMarioRamirezAún no hay calificaciones
- Comando FINDDocumento9 páginasComando FINDMarioRamirezAún no hay calificaciones
- Retos y DificultadesDocumento23 páginasRetos y DificultadesMarioRamirezAún no hay calificaciones
- La Muerte Del Hardware y SofrtwareDocumento17 páginasLa Muerte Del Hardware y SofrtwareMarioRamirezAún no hay calificaciones
- Estándaresdecomunicación PDFDocumento3 páginasEstándaresdecomunicación PDFManuel Fernando Papa YelaAún no hay calificaciones
- Com, Dcom, CorbaDocumento16 páginasCom, Dcom, CorbaMarioRamirezAún no hay calificaciones
- Definicion PDFDocumento6 páginasDefinicion PDFMarioRamirezAún no hay calificaciones
- Sistemas Distribuidos PanoramaDocumento17 páginasSistemas Distribuidos PanoramaMarguita MaqueAún no hay calificaciones
- Practica I PDFDocumento1 páginaPractica I PDFMarioRamirezAún no hay calificaciones
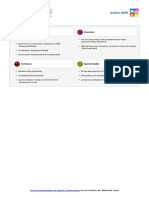
- DAFODocumento2 páginasDAFOMarioRamirezAún no hay calificaciones
- Modelosdelossistemasdistribuidos 140522233511 Phpapp02Documento56 páginasModelosdelossistemasdistribuidos 140522233511 Phpapp02Carlos Manuel Padilla CruzAún no hay calificaciones
- TP-Link TL-WA5210G Access PointDocumento15 páginasTP-Link TL-WA5210G Access Pointfernandov24Aún no hay calificaciones
- Comunicacin Entre Procesos 160217022423Documento41 páginasComunicacin Entre Procesos 160217022423Giovanny Andres RamiresAún no hay calificaciones
- 03IXStream Sistemas Distribuidos PDFDocumento201 páginas03IXStream Sistemas Distribuidos PDFMireya Noemi Arroyos RodriguezAún no hay calificaciones
- Características Del Estándar ANSI ISA 101.01 2015Documento10 páginasCaracterísticas Del Estándar ANSI ISA 101.01 2015antonioheredia50% (2)
- Manual Tecnico Censo AgropecuarioDocumento6 páginasManual Tecnico Censo AgropecuarioCristian HerediaAún no hay calificaciones
- Final Plantilla para Elaborar Tu ProyectoDocumento41 páginasFinal Plantilla para Elaborar Tu ProyectoJorge Andrew's MendozaAún no hay calificaciones
- Paredes Vega Hector Ivan Uni 02 Act 02Documento2 páginasParedes Vega Hector Ivan Uni 02 Act 02hpkatiaAún no hay calificaciones
- Lab - 12 Andamayo GaryDocumento5 páginasLab - 12 Andamayo GaryGary Edson Andamayo Yaya100% (1)
- Fundamentos de Calidad Del Software - Aseguramiento de La Calidad Del Software (SQA)Documento42 páginasFundamentos de Calidad Del Software - Aseguramiento de La Calidad Del Software (SQA)J Yobany Murillo AAún no hay calificaciones
- Ejercicios Básicos - EnunciadosDocumento11 páginasEjercicios Básicos - EnunciadosEspinosa Solano Lisseth Guadalupe ぬみAún no hay calificaciones
- Actividad de Aprendizaje 13 Evidencia 1 Articulo Tecnologias de La Informacion y La ComunicacionDocumento6 páginasActividad de Aprendizaje 13 Evidencia 1 Articulo Tecnologias de La Informacion y La ComunicacionAnggie HerreraAún no hay calificaciones
- Tutorial 01 Visor de ImagenesDocumento28 páginasTutorial 01 Visor de ImagenesRaul RojasAún no hay calificaciones
- Taller 3 Guía ExcelDocumento2 páginasTaller 3 Guía ExcelzayrajoharoaAún no hay calificaciones
- Gestión de Fincas e InmueblesDocumento7 páginasGestión de Fincas e InmueblesAndres Renjifo100% (1)
- Representación de La Arquitectura de Software Usando UMLDocumento10 páginasRepresentación de La Arquitectura de Software Usando UMLJorge MartinezAún no hay calificaciones
- Evaluación Virtual 6Documento19 páginasEvaluación Virtual 6Gilmar GutiérrezAún no hay calificaciones
- Tipos de Vistas de Power PointDocumento10 páginasTipos de Vistas de Power PointJuan RealesAún no hay calificaciones
- Sistemas de ArchivosDocumento5 páginasSistemas de ArchivosAxel GomezAún no hay calificaciones
- Tarea 5Documento9 páginasTarea 5Temporal UserAún no hay calificaciones
- Manual de Comandos en LinuxDocumento32 páginasManual de Comandos en LinuxMinimideOsarAún no hay calificaciones
- Dialnet InvestigacionesCualitativasEnCienciaYTecnologia201 718933 PDFDocumento490 páginasDialnet InvestigacionesCualitativasEnCienciaYTecnologia201 718933 PDFRey David Castillo VegaAún no hay calificaciones
- AVG Antivirus 2015Documento9 páginasAVG Antivirus 2015jesús castilloAún no hay calificaciones
- Artefactos de Sistema WindowsDocumento11 páginasArtefactos de Sistema WindowsFrancisco BarriosAún no hay calificaciones
- Conciencia Tecnológica 1405-5597: Issn: Contec@mail - Ita.mxDocumento5 páginasConciencia Tecnológica 1405-5597: Issn: Contec@mail - Ita.mxCarlos PoemapeAún no hay calificaciones
- Silabo Suficiencia Académica 2018Documento10 páginasSilabo Suficiencia Académica 2018Ronald Cordova TorrejonAún no hay calificaciones
- Desconectado Por VACDocumento5 páginasDesconectado Por VACJOSE SANTIAGOAún no hay calificaciones
- Acuerdo 189-2014 Reglamento Del Regimen de FacturacionDocumento20 páginasAcuerdo 189-2014 Reglamento Del Regimen de FacturacionDavid TejadaAún no hay calificaciones
- Dev Pascal 2009Documento26 páginasDev Pascal 2009Jorge BetancourtAún no hay calificaciones
- Resumen Memoria PFC: TANGIBLE: Sistema de Bajo Coste para Localización y Detección de Gestos 3D en Entornos Inmersivos.Documento59 páginasResumen Memoria PFC: TANGIBLE: Sistema de Bajo Coste para Localización y Detección de Gestos 3D en Entornos Inmersivos.Álvaro Fernández TuestaAún no hay calificaciones
- Uso de Toolbox MATLABDocumento9 páginasUso de Toolbox MATLABByron Xavier Lima CedilloAún no hay calificaciones
- 6 CalculosDocumento22 páginas6 CalculosJuan Jose GomezAún no hay calificaciones
- Libros CompDocumento60 páginasLibros Compaulisan14Aún no hay calificaciones
- AAI - TIDS02 - Guía de Ejercicios 1 Conversión de Pseudocódigos A JAVADocumento9 páginasAAI - TIDS02 - Guía de Ejercicios 1 Conversión de Pseudocódigos A JAVAjavierAún no hay calificaciones