También podría gustarte
- Curso de Introducción a la Administración de Bases de DatosDe EverandCurso de Introducción a la Administración de Bases de DatosCalificación: 3 de 5 estrellas3/5 (1)
- Base de Datos No SQLDocumento8 páginasBase de Datos No SQLAngee Sophia LofarAún no hay calificaciones
- MineSight For EngineersDocumento214 páginasMineSight For EngineersRicardo Contreras BAún no hay calificaciones
- Manual FedoraDocumento8 páginasManual Fedoralas chicas100% (2)
- 1.5 Clasificacion de Base de DatosDocumento8 páginas1.5 Clasificacion de Base de DatosOscar MarínAún no hay calificaciones
- Miw. Vgiw. 3. SoftwareDocumento105 páginasMiw. Vgiw. 3. SoftwarecarlosgutisotoAún no hay calificaciones
- Iniciación A FlowcodeDocumento36 páginasIniciación A FlowcodeELPICHUE100% (1)
- Bases de Datos NoSQLDocumento3 páginasBases de Datos NoSQLPatty Bucay100% (1)
- Bases de Datos y Sus TiposDocumento9 páginasBases de Datos y Sus TiposVictor HernandezAún no hay calificaciones
- Estado Del ArteDocumento4 páginasEstado Del Arteandres chalacaAún no hay calificaciones
- Act1 Nuevo ParadigmaDocumento15 páginasAct1 Nuevo ParadigmaKevin LazaroAún no hay calificaciones
- ENSAYO Lam LedsgalDocumento13 páginasENSAYO Lam LedsgalJason Lazo LockAún no hay calificaciones
- Trabajo de Cloud Computing (Aca 3) : Priciliano Aponte Sáenz Ficha: 51118/PRIMER BLOQUE/23V01 C..19.002.079Documento6 páginasTrabajo de Cloud Computing (Aca 3) : Priciliano Aponte Sáenz Ficha: 51118/PRIMER BLOQUE/23V01 C..19.002.079PRICILIANO APONTE SAENZAún no hay calificaciones
- Ensayo NOSQLDocumento9 páginasEnsayo NOSQLAxel Sunem Mora OlveraAún no hay calificaciones
- Manejo y Acceso A La Información Por Medio de Bases de Datos NoSQLDocumento22 páginasManejo y Acceso A La Información Por Medio de Bases de Datos NoSQLjonyAún no hay calificaciones
- No SQLDocumento5 páginasNo SQLmarthin0104Aún no hay calificaciones
- Bases de datos NoSQLDocumento21 páginasBases de datos NoSQLEdsn Denys SarabiaAún no hay calificaciones
- Actividad de Aprendizaje 1Documento4 páginasActividad de Aprendizaje 1manuelaAún no hay calificaciones
- Base de Datos NoSQLDocumento11 páginasBase de Datos NoSQLcarlosAún no hay calificaciones
- Archivo 1 - Bases de Datos No Relacionales - NoSQLDocumento12 páginasArchivo 1 - Bases de Datos No Relacionales - NoSQLKarla DíazAún no hay calificaciones
- Modelado de Base de Datos en Sistemas No Relacionales Nosql - Viljar Palenque OrozDocumento22 páginasModelado de Base de Datos en Sistemas No Relacionales Nosql - Viljar Palenque OrozViLjaR Palenque OrozAún no hay calificaciones
- El Aporte de Las Bases de Datos NoSQL en El Manejo de La InformaciónDocumento3 páginasEl Aporte de Las Bases de Datos NoSQL en El Manejo de La InformaciónJHONATAN DAVID HERNANDEZ HERRERAAún no hay calificaciones
- Bases de datos NoSQL conceptosDocumento7 páginasBases de datos NoSQL conceptosElíasAún no hay calificaciones
- Taller evaluativo. BDDocumento4 páginasTaller evaluativo. BDJOHAN SEBASTIAN DE LAS SALAS DONADOAún no hay calificaciones
- Un Viaje A Través de Base de Datos Espaciales NoSQL EmaDocumento3 páginasUn Viaje A Través de Base de Datos Espaciales NoSQL EmaJamileth FrancoAún no hay calificaciones
- NoSQL DatabasesDocumento53 páginasNoSQL Databasesjuanc.erazo5531Aún no hay calificaciones
- Trabajo Base de DatosDocumento4 páginasTrabajo Base de DatosHECTOR MEDINA LAFONTAún no hay calificaciones
- Ensayo Tecnico Bases de DatosDocumento8 páginasEnsayo Tecnico Bases de DatosMaria Jose Avecillas VillavicencioAún no hay calificaciones
- Base de Datos ResumenDocumento13 páginasBase de Datos Resumeninvictus75opAún no hay calificaciones
- Base de Datos No RelacionalDocumento16 páginasBase de Datos No RelacionalDaniel Rasgado CisnerosAún no hay calificaciones
- Bases de datos: qué son y cómo funcionanDocumento4 páginasBases de datos: qué son y cómo funcionanYajaira CerdaAún no hay calificaciones
- Bases de Datos DocumentalesDocumento4 páginasBases de Datos Documentalesnew magitoAún no hay calificaciones
- Análisis Caso Base de Datos Rafael Pombo 2Documento13 páginasAnálisis Caso Base de Datos Rafael Pombo 2est.tfalexanderAún no hay calificaciones
- Tipos de Bases de DatosDocumento10 páginasTipos de Bases de DatosLiliana SanchezAún no hay calificaciones
- Bases de Datos No relacionalesKEVINDocumento8 páginasBases de Datos No relacionalesKEVINmilagrosdaboinAún no hay calificaciones
- Bases de datos: tipos, características y ejemplosDocumento39 páginasBases de datos: tipos, características y ejemplosgerman jose hernandez ouviertAún no hay calificaciones
- Articulo Base de Datos SQL Vs NOsqlDocumento5 páginasArticulo Base de Datos SQL Vs NOsqlCjJohnnyAún no hay calificaciones
- Tipos de Base de DatosDocumento6 páginasTipos de Base de DatosMARIA FAJARDO CORTESAún no hay calificaciones
- Base de DatosDocumento20 páginasBase de DatosAnthony PalmaAún no hay calificaciones
- Tarea 10 BDDocumento9 páginasTarea 10 BDSamantha PalenciaAún no hay calificaciones
- CassandraDocumento20 páginasCassandradiamondAún no hay calificaciones
- Bases de Datos NosqlDocumento2 páginasBases de Datos NosqlErnesto GonzalezAún no hay calificaciones
- todoSQL 110902Documento49 páginastodoSQL 110902Christian RamiresAún no hay calificaciones
- NoSQL Vs SQLDocumento16 páginasNoSQL Vs SQLLuis BanAún no hay calificaciones
- Introduccion de La Base de DatosDocumento4 páginasIntroduccion de La Base de DatosAlan CarreraAún no hay calificaciones
- Septima EntregaDocumento7 páginasSeptima EntregaAndres MartinezAún no hay calificaciones
- MySQL - EggDocumento63 páginasMySQL - EggSebas F71Aún no hay calificaciones
- Rendimiento NoSQL masivasDocumento8 páginasRendimiento NoSQL masivasDavid SalasAún no hay calificaciones
- 7 - Guía MysqlDocumento56 páginas7 - Guía Mysqlalexis pieroAún no hay calificaciones
- Guía MySQLDocumento56 páginasGuía MySQLFernando AlarconAún no hay calificaciones
- Historia de Las Bases de DatosDocumento11 páginasHistoria de Las Bases de DatosChristian TovarAún no hay calificaciones
- Tabla Practica IDocumento14 páginasTabla Practica IYenifel SueroAún no hay calificaciones
- Conceptos BasicosDocumento9 páginasConceptos BasicosSinai MurguiaAún no hay calificaciones
- Impacto de Los Sistemas de Informacion en Las OrganizacionesDocumento6 páginasImpacto de Los Sistemas de Informacion en Las OrganizacionesDany VegaAún no hay calificaciones
- Base de Dato (Sistema)Documento7 páginasBase de Dato (Sistema)Leyra Ediith GoveaAún no hay calificaciones
- ACID compliant y transacciones en bases de datosDocumento8 páginasACID compliant y transacciones en bases de datosGustavo GonzalezAún no hay calificaciones
- Bases de DatosDocumento10 páginasBases de DatosLorena Domitila Abad ViejóAún no hay calificaciones
- Marco Teorico, Reflexion y ReferenciasDocumento8 páginasMarco Teorico, Reflexion y ReferenciasRAFAEL DAVID CASTILLO SALCEDOAún no hay calificaciones
- BBDD Nosql WP AcensDocumento7 páginasBBDD Nosql WP AcensKarOlita AndaurAún no hay calificaciones
- Principios Base de DatosDocumento9 páginasPrincipios Base de DatosAlexanderAún no hay calificaciones
- Práctica 1 - Base de Datos Miguel y MarcosDocumento3 páginasPráctica 1 - Base de Datos Miguel y MarcosVioletaAún no hay calificaciones
- ALEJANDRO MARTÍNEZ - BBDD NoSQL PDFDocumento5 páginasALEJANDRO MARTÍNEZ - BBDD NoSQL PDFAlejandro LujánAún no hay calificaciones
- Bdno SQLe XistDocumento16 páginasBdno SQLe XistPablo BarbanchoAún no hay calificaciones
- Cronograma Fase 4 DesarrolloDocumento1 páginaCronograma Fase 4 DesarrolloBernardo Moreno CamargoAún no hay calificaciones
- GFPI-F-023 Formato Planeacion Seguimiento y Evaluacion Etapa ProductivaDocumento3 páginasGFPI-F-023 Formato Planeacion Seguimiento y Evaluacion Etapa Productivanathalia santamariaAún no hay calificaciones
- Proyecto FormativoDocumento17 páginasProyecto FormativoLuis Humberto Martinez PalmethAún no hay calificaciones
- 2GFPI-F-019 - Formato - Guia - de - Aprendizaje 01Documento6 páginas2GFPI-F-019 - Formato - Guia - de - Aprendizaje 01Bernardo Moreno CamargoAún no hay calificaciones
- FAVA - Formación en Análisis y Desarrollo de Sistemas de InformaciónDocumento42 páginasFAVA - Formación en Análisis y Desarrollo de Sistemas de InformaciónLuis Fernando RiveroAún no hay calificaciones
- Cronograma Fase IdentificaciónDocumento1 páginaCronograma Fase IdentificaciónBernardo Moreno CamargoAún no hay calificaciones
- Cronograma Fase 3 Diseño 1749814Documento1 páginaCronograma Fase 3 Diseño 1749814Bernardo Moreno CamargoAún no hay calificaciones
- Tematica Curso Análisis de DesarrolloDocumento32 páginasTematica Curso Análisis de DesarrolloMARIOAún no hay calificaciones
- Cronograma de Actividades INDUCCIÓNDocumento1 páginaCronograma de Actividades INDUCCIÓNBernardo Moreno CamargoAún no hay calificaciones
- GFPI-F-035 - V2 - Formato - Articulacion - Curriculo - Educacion - Media-Programa - de - Formacion - SENA - Camilo TorresDocumento3 páginasGFPI-F-035 - V2 - Formato - Articulacion - Curriculo - Educacion - Media-Programa - de - Formacion - SENA - Camilo TorresJefferson BuitragoAún no hay calificaciones
- Lista de Chequeo - Mtto Preventivo2-Sistemas IiDocumento2 páginasLista de Chequeo - Mtto Preventivo2-Sistemas IiBernardo Moreno CamargoAún no hay calificaciones
- Instrumento de Evaluacion - Desempeño - Guia 4Documento2 páginasInstrumento de Evaluacion - Desempeño - Guia 4Bernardo Moreno CamargoAún no hay calificaciones
- SENA evaluación aprendizaje programaciónDocumento2 páginasSENA evaluación aprendizaje programaciónBernardo Moreno CamargoAún no hay calificaciones
- Instrumento de Evaluacion - ProductoDocumento4 páginasInstrumento de Evaluacion - ProductoBernardo Moreno CamargoAún no hay calificaciones
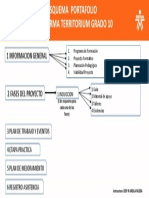
- Esquema PortafolioDocumento1 páginaEsquema PortafolioBernardo Moreno CamargoAún no hay calificaciones
- Instrumento de Evaluacion - Desempeño DFD - Guia 4Documento2 páginasInstrumento de Evaluacion - Desempeño DFD - Guia 4Bernardo Moreno CamargoAún no hay calificaciones
- GFPI-F-025 Lista Verificación Aplicación Procedimiento Ejecución de La FormaciónDocumento8 páginasGFPI-F-025 Lista Verificación Aplicación Procedimiento Ejecución de La FormaciónBernardo Moreno CamargoAún no hay calificaciones
- Perfil TN Programacion de SoftwareDocumento1 páginaPerfil TN Programacion de SoftwareBernardo Moreno CamargoAún no hay calificaciones
- Plantilla Acta Compromiso PAEM SENA-IEDocumento3 páginasPlantilla Acta Compromiso PAEM SENA-IEjulianAún no hay calificaciones
- GFPI-F-021 Formato Notificacion Novedades AmbienteDocumento2 páginasGFPI-F-021 Formato Notificacion Novedades AmbienteJohn Anderson Florido CardonaAún no hay calificaciones
- GD-F-007 Formato de Acta y Registro de AsistenciaDocumento9 páginasGD-F-007 Formato de Acta y Registro de Asistenciajuan david agudelo perodmoAún no hay calificaciones
- GFPI-F-033 Formato Autodiagnostico Institucion EducativaDocumento4 páginasGFPI-F-033 Formato Autodiagnostico Institucion EducativaBernardo Moreno CamargoAún no hay calificaciones
- Presentacion SistemasDocumento7 páginasPresentacion SistemasBernardo Moreno CamargoAún no hay calificaciones
- Invitacion Escuela de Padres - PlantillaDocumento1 páginaInvitacion Escuela de Padres - PlantillaBernardo Moreno CamargoAún no hay calificaciones
- Presentacion Paralelos Programas SistemasDocumento12 páginasPresentacion Paralelos Programas SistemasBernardo Moreno CamargoAún no hay calificaciones
- Estructura NuevaDocumento48 páginasEstructura NuevaANDRES GONZALO REVELO DELGADOAún no hay calificaciones
- Presentacion Paralelos Programas SistemasDocumento12 páginasPresentacion Paralelos Programas SistemasBernardo Moreno CamargoAún no hay calificaciones
- INCOMATRIX (Spanish)Documento28 páginasINCOMATRIX (Spanish)Bernardo Moreno CamargoAún no hay calificaciones
- Manejo de ModulosDocumento6 páginasManejo de ModulosBernardo Moreno CamargoAún no hay calificaciones
- Udemy Workbook 202101 EsDocumento10 páginasUdemy Workbook 202101 EsLuis José RodríguezAún no hay calificaciones
- Torres de Hanoi: resolución recursivaDocumento4 páginasTorres de Hanoi: resolución recursivaJavLo LopAún no hay calificaciones
- Base de Datos MultimediaDocumento15 páginasBase de Datos MultimedialepllachAún no hay calificaciones
- Los 7 Comandos Prohibidos de LinuxDocumento1 páginaLos 7 Comandos Prohibidos de LinuxLando MejiaAún no hay calificaciones
- ArtículoLYX PDFDocumento20 páginasArtículoLYX PDFAndhy DiazAún no hay calificaciones
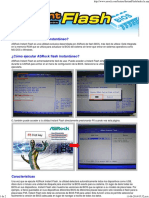
- ASRock Instant FlashDocumento2 páginasASRock Instant FlashdecatequistasAún no hay calificaciones
- Monografia Bellman Ford Bolaños para Hacer InformeDocumento6 páginasMonografia Bellman Ford Bolaños para Hacer InformericrichardAún no hay calificaciones
- CF MU Presentacion Declaraciones Juradas y PagosDocumento95 páginasCF MU Presentacion Declaraciones Juradas y PagosruiznelsonAún no hay calificaciones
- Dispositivos periféricos y herramientas PCDocumento4 páginasDispositivos periféricos y herramientas PCmarauro20051764Aún no hay calificaciones
- Pilas y Colas: LIFO y FIFODocumento3 páginasPilas y Colas: LIFO y FIFOMiriam ValdezAún no hay calificaciones
- Partes de Un Programa en Lenguaje C PDFDocumento11 páginasPartes de Un Programa en Lenguaje C PDFCarmen PereaAún no hay calificaciones
- GFPI-F-019 - Formato - Guia - de - Aprendizaje 1 - Pro. Soft - BDDocumento21 páginasGFPI-F-019 - Formato - Guia - de - Aprendizaje 1 - Pro. Soft - BDLuisHHerreraAún no hay calificaciones
- Sobrecarga OperadoresDocumento2 páginasSobrecarga OperadoresAlejandro PortillaAún no hay calificaciones
- Guia Easy DocsDocumento5 páginasGuia Easy DocsCarlosEduardoCortesAún no hay calificaciones
- Especificacion de Requerimientos Software22Documento7 páginasEspecificacion de Requerimientos Software22ROBINSON RODRIGUEZAún no hay calificaciones
- Centreon Administracion de EventosDocumento7 páginasCentreon Administracion de EventosRaul Guanilo CastilloAún no hay calificaciones
- Waypoints and Track Logs in UTM Grid CoordinatesDocumento350 páginasWaypoints and Track Logs in UTM Grid Coordinatescparedes6Aún no hay calificaciones
- Actividad 1 - Términos Sobre La Seguridad Informática.Documento7 páginasActividad 1 - Términos Sobre La Seguridad Informática.Inés Martínez CarralAún no hay calificaciones
- Mientras - Repetir - paraDocumento11 páginasMientras - Repetir - paraJhon SalazarAún no hay calificaciones
- Sistemas Operativos FCFSDocumento52 páginasSistemas Operativos FCFSÁlvaro Pablos LamasAún no hay calificaciones
- Wk1 b1 Encender ApagarDocumento2 páginasWk1 b1 Encender ApagarSthla PerezAún no hay calificaciones
- Lab 01 - Sistemas de NumeracionDocumento12 páginasLab 01 - Sistemas de NumeracionJose Yagua BeltranAún no hay calificaciones
- Selección de Una Correcta Distribución, Proceso de Encendido e Instalación de LinuxDocumento18 páginasSelección de Una Correcta Distribución, Proceso de Encendido e Instalación de LinuxFercho ChiribogaAún no hay calificaciones
- Kardex de notas de Ingeniería InformáticaDocumento3 páginasKardex de notas de Ingeniería InformáticaRick EspinozaAún no hay calificaciones
- Unidad 9Documento66 páginasUnidad 9Carlos Israel JimenezAún no hay calificaciones
- Sintaxis EmmetDocumento4 páginasSintaxis EmmetNelson CerdaAún no hay calificaciones
- Cómo combinar Scrum y XPDocumento2 páginasCómo combinar Scrum y XPCristhian Javier OrozcoAún no hay calificaciones