También podría gustarte
- Elementos Esenciales Negocio DigitalDocumento19 páginasElementos Esenciales Negocio DigitalCesarLozano100% (2)
- Ejemplo de Una Matriz de ControlDocumento16 páginasEjemplo de Una Matriz de ControlEdwin Avila Ruiz100% (2)
- Caso UBERDocumento11 páginasCaso UBERCamila LópezAún no hay calificaciones
- ConclusiónDocumento2 páginasConclusiónMiguelLopez100% (2)
- Ejemplo de Caso de UsoDocumento11 páginasEjemplo de Caso de UsoFrancisco Gonzalez AguilarAún no hay calificaciones
- Implementación CMMI para El Desarrollo de SoftwareDocumento165 páginasImplementación CMMI para El Desarrollo de SoftwareDavidAún no hay calificaciones
- Sistemas Embebidos en VHDLDocumento20 páginasSistemas Embebidos en VHDLAndy Blue50% (2)
- Inteligencia ArtificialDocumento23 páginasInteligencia ArtificialF.M.100% (1)
- Propuesta Plan Disponibilidad RecuperacionDocumento197 páginasPropuesta Plan Disponibilidad RecuperacionDavidAún no hay calificaciones
- Planeación Estratégica (Parte I)Documento49 páginasPlaneación Estratégica (Parte I)DavidAún no hay calificaciones
- Ingenieria de SoftwareDocumento26 páginasIngenieria de SoftwareDavidAún no hay calificaciones
- Evolución de La Firma ElectrónicaDocumento27 páginasEvolución de La Firma ElectrónicaDavid0% (1)
- Matematicas DiscretasDocumento76 páginasMatematicas DiscretasDavidAún no hay calificaciones
- Ers Sicc - (Ejemplo)Documento33 páginasErs Sicc - (Ejemplo)DavidAún no hay calificaciones
- Reglamento de La Ley de Firma Electrónica AvanzadaDocumento5 páginasReglamento de La Ley de Firma Electrónica AvanzadaDavidAún no hay calificaciones
- POA 2021-2022 Electromecánica AutomotrizDocumento3 páginasPOA 2021-2022 Electromecánica AutomotrizvampiroalexAún no hay calificaciones
- Fundamento de Las Bases de Datos - Modelo Entidad-Relación PDFDocumento11 páginasFundamento de Las Bases de Datos - Modelo Entidad-Relación PDFCarlos ToroAún no hay calificaciones
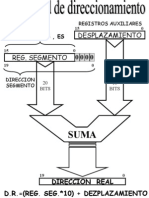
- Unidad I-5 DireccionamientoDocumento14 páginasUnidad I-5 DireccionamientoJesús de DiiAún no hay calificaciones
- Autorización Consulta Externa: Página 1 de 1Documento1 páginaAutorización Consulta Externa: Página 1 de 1Yarleniz RuzAún no hay calificaciones
- LIGHTBURN Manual de InstruccionesDocumento239 páginasLIGHTBURN Manual de InstruccionesDiego Valladares Galicia100% (1)
- Trabajos de Goma EvaDocumento16 páginasTrabajos de Goma EvaMiguel Angel VelasquezAún no hay calificaciones
- Tablas y Graficos DinamicosDocumento5 páginasTablas y Graficos DinamicosMARIBEL ABIGAIL VALDIVIEZO GALANAún no hay calificaciones
- ComputoDocumento10 páginasComputoLuis Luna PultayAún no hay calificaciones
- SolidworkDocumento10 páginasSolidworklupitaramsvAún no hay calificaciones
- Actividades 3.1 Cuadro Sinoptico Medidas de AlmacenamientoDocumento2 páginasActividades 3.1 Cuadro Sinoptico Medidas de AlmacenamientoCarla Andrina Valdez100% (1)
- Introduccion A La Iot Capitulo IiiDocumento57 páginasIntroduccion A La Iot Capitulo IiiPedroChavarriaDiazAún no hay calificaciones
- 18 Triggers PDFDocumento25 páginas18 Triggers PDFEstebanBareiroAún no hay calificaciones
- Ejemplos Diagramas de FlujoDocumento10 páginasEjemplos Diagramas de Flujozule merizaldeAún no hay calificaciones
- Creación de Cielo RasoDocumento11 páginasCreación de Cielo RasoVictor YocyaAún no hay calificaciones
- Teclado MatricialDocumento9 páginasTeclado MatricialnestorAún no hay calificaciones
- Grupo 02-Expo Flex-SimDocumento9 páginasGrupo 02-Expo Flex-Simjhonny ricardo toledo castilloAún no hay calificaciones
- KOB-SGSI-PR-003 Procedimiento de Backup y Restore V03Documento5 páginasKOB-SGSI-PR-003 Procedimiento de Backup y Restore V03Carlos Alberto Fonseca DaviránAún no hay calificaciones
- CVDocumento2 páginasCVcesarAún no hay calificaciones
- Procedimiento Busqueda Ubicación Materiales PañolDocumento12 páginasProcedimiento Busqueda Ubicación Materiales PañolMiguel CejasAún no hay calificaciones
- Guia GE FANUC 21TBDocumento26 páginasGuia GE FANUC 21TBJeisson PachecoAún no hay calificaciones
- Evidenciaa Foro Sistema de Informacion de Los Procesos LogicticosDocumento6 páginasEvidenciaa Foro Sistema de Informacion de Los Procesos LogicticosSurley PalenciaAún no hay calificaciones
- Consideraciones Bim para Elaborar El ProyectoDocumento44 páginasConsideraciones Bim para Elaborar El ProyectoJudith Bruno EspinozaAún no hay calificaciones
- Taller Sistemas - OperativosDocumento24 páginasTaller Sistemas - OperativosRafael ManotasAún no hay calificaciones