También podría gustarte
- Problema Cantidad de Movimiento de Fenomenos de Transporte Libro BirdDocumento3 páginasProblema Cantidad de Movimiento de Fenomenos de Transporte Libro BirdAldoCabreraFernandez100% (1)
- INVESTIGACIÓNDocumento51 páginasINVESTIGACIÓNItachi UchiaAún no hay calificaciones
- Ejercicios de FenomenosDocumento3 páginasEjercicios de FenomenosSergio BlancoAún no hay calificaciones
- Trabajo Sobre TerremotosDocumento10 páginasTrabajo Sobre TerremotosmarioAún no hay calificaciones
- HipérbolaDocumento2 páginasHipérbolaRicardo Parra100% (1)
- Desobturacion Y Solventes de Gutapercha PDFDocumento55 páginasDesobturacion Y Solventes de Gutapercha PDFGenesisSolanoAún no hay calificaciones
- Transferencia de Calor, Segunda Edición (Manrique)Documento324 páginasTransferencia de Calor, Segunda Edición (Manrique)Eduardo Leonel H. Yx100% (17)
- Varianza Conocida - Varianza Desconocida ( ) ̄ ( ) ̄ ( 1)Documento6 páginasVarianza Conocida - Varianza Desconocida ( ) ̄ ( ) ̄ ( 1)Catalina Cruz BravoAún no hay calificaciones
- Unidad III Inferencia Acerca de Una y Dos PoblacionesDocumento25 páginasUnidad III Inferencia Acerca de Una y Dos Poblaciones??????Aún no hay calificaciones
- Constante de PlanckDocumento19 páginasConstante de PlanckNicolás Berrío HerreraAún no hay calificaciones
- Formulario Inferencia 489376Documento1 páginaFormulario Inferencia 489376wendy lauraAún no hay calificaciones
- Deber2 B2Documento12 páginasDeber2 B2Alejandra SamaniegoAún no hay calificaciones
- NOTAS - Comparación de Dos MediasDocumento8 páginasNOTAS - Comparación de Dos MediasluisAún no hay calificaciones
- Resumen Pruebas de Hipótesis de RegresionesDocumento2 páginasResumen Pruebas de Hipótesis de RegresionesDREAM BOXAún no hay calificaciones
- Capítulo 2 PDFDocumento22 páginasCapítulo 2 PDFHugo EspinozaAún no hay calificaciones
- Intervalos 2 PoblacionesDocumento5 páginasIntervalos 2 PoblacionesisabelAún no hay calificaciones
- 06 22 Integral DefinidaDocumento5 páginas06 22 Integral DefinidaSebastianAún no hay calificaciones
- Guía01 2 2022 1Documento6 páginasGuía01 2 2022 1Luis Arrieta100% (2)
- Formularioparte 2Documento22 páginasFormularioparte 2ClauAún no hay calificaciones
- Taller 7 OndasDocumento7 páginasTaller 7 OndasDaniel Felipe PeraltaAún no hay calificaciones
- Maxima VerosimilitudDocumento19 páginasMaxima VerosimilitudStefano Calderon GalarzaAún no hay calificaciones
- Formulario5 IntervaloConfianzaDocumento1 páginaFormulario5 IntervaloConfianzaMiguel Saenz EgúsquizaAún no hay calificaciones
- FORMULARIO MAT 1136 I-2020 Aux. Lizeth Nelly Lopez TorrezDocumento4 páginasFORMULARIO MAT 1136 I-2020 Aux. Lizeth Nelly Lopez TorrezLizeth Nelly Lopez TorrezAún no hay calificaciones
- Funcion WeibullDocumento4 páginasFuncion WeibullDamianMenaAún no hay calificaciones
- Medios de PropagaciónDocumento4 páginasMedios de PropagaciónGERARDO FLORES CHUQUIMIAAún no hay calificaciones
- Taller Cuatro - Mariana BayonaDocumento6 páginasTaller Cuatro - Mariana BayonaMariana BayonaAún no hay calificaciones
- Ejercicios de Fisica 35 51 NuevoDocumento11 páginasEjercicios de Fisica 35 51 NuevoAnonymous 83bPWvN4GAún no hay calificaciones
- Ma444-2021 01-Formulas y tablas-EBDocumento10 páginasMa444-2021 01-Formulas y tablas-EBMoisés Romero FloresAún no hay calificaciones
- 06 Verificación de Aprendizaje ResueltosDocumento8 páginas06 Verificación de Aprendizaje ResueltosSebastianAún no hay calificaciones
- FORMULARIODocumento2 páginasFORMULARIOLinda De LeónAún no hay calificaciones
- AntenasDocumento3 páginasAntenasAugusto GarciaAún no hay calificaciones
- Ex. Sustitutorio Ee588 - Fiee UniDocumento7 páginasEx. Sustitutorio Ee588 - Fiee UniDavidAún no hay calificaciones
- 8Documento5 páginas8Anonymous 50rGkqmU100% (1)
- Hoja de Fórmulas 2 PDFDocumento4 páginasHoja de Fórmulas 2 PDFPancho MaffiAún no hay calificaciones
- Flujo de Fluidos Compresibles-Escurrimiento AdiabaticoDocumento5 páginasFlujo de Fluidos Compresibles-Escurrimiento AdiabaticoGabriela Teresa Góngora ZepitaAún no hay calificaciones
- Muestreo Aleatorio Simple Media PoblacionalDocumento4 páginasMuestreo Aleatorio Simple Media PoblacionalLaura Veira.Aún no hay calificaciones
- Pruebas de HipotesisDocumento1 páginaPruebas de HipotesisKarol Moreno100% (1)
- Ejercicios Resueltos Sobre Desviación Estándar Poblacional, Función de Densidad de Probabilidad, Estimación Por Momentos y Variable AleatoriaDocumento10 páginasEjercicios Resueltos Sobre Desviación Estándar Poblacional, Función de Densidad de Probabilidad, Estimación Por Momentos y Variable AleatoriaMario Orlando Suárez IbujésAún no hay calificaciones
- Clase Semana 10 Cap 3 Distribuciones Importantes Distribuciones Normal, Binomial y LogNormalDocumento24 páginasClase Semana 10 Cap 3 Distribuciones Importantes Distribuciones Normal, Binomial y LogNormalAxel AlvarezAún no hay calificaciones
- Formulario Estadistica InferencialDocumento6 páginasFormulario Estadistica InferencialMatias BravoAún no hay calificaciones
- Formulario Inferencia Icdocima 12m Ok 497508Documento7 páginasFormulario Inferencia Icdocima 12m Ok 497508Valentina Duran RamirezAún no hay calificaciones
- Capítulo 7 INTERVALO DE CONFIANZA - 083714Documento5 páginasCapítulo 7 INTERVALO DE CONFIANZA - 083714LunaAún no hay calificaciones
- Ayudantia Sabado 14 de MayoDocumento3 páginasAyudantia Sabado 14 de MayoAlejandraAún no hay calificaciones
- Ej ResueltosDocumento26 páginasEj ResueltosMaría Menéndez MarínAún no hay calificaciones
- VEXPODocumento20 páginasVEXPOALEJANDRA LUCERO MEJ�A CRUZAún no hay calificaciones
- Mvco2 U1 Ea V2 RaicDocumento9 páginasMvco2 U1 Ea V2 RaicRaúl SánchezAún no hay calificaciones
- METODO DE HARDY CROS1 AlturasDocumento13 páginasMETODO DE HARDY CROS1 AlturasValentín PilcoAún no hay calificaciones
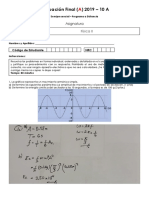
- Física Ii - Tipo A Examen Final 2019-10Documento6 páginasFísica Ii - Tipo A Examen Final 2019-10Ryuzaki KuroShin クロしんAún no hay calificaciones
- Integrales de Línea 1Documento10 páginasIntegrales de Línea 1cristofer aravenaAún no hay calificaciones
- Contenido S14Documento7 páginasContenido S14WILSON ANDRES ERAZO CUASAPAZAún no hay calificaciones
- HojadeecuacionesaDocumento1 páginaHojadeecuacionesaRocio VillalbaAún no hay calificaciones
- Taller 2 Integrales MultiplesDocumento38 páginasTaller 2 Integrales MultiplesDaniel SanchezAún no hay calificaciones
- 2.e Problema ResueltoDocumento3 páginas2.e Problema ResueltoJosé IvánAún no hay calificaciones
- 05-05-2022 VARIABLES ALEATORIAS CONTINUAS Y ALGUNOS MODELOS DE PROBABILIDAD Funciones de Probabilidad Bivariantes Esperanza Bivariantes - CovarianzaDocumento6 páginas05-05-2022 VARIABLES ALEATORIAS CONTINUAS Y ALGUNOS MODELOS DE PROBABILIDAD Funciones de Probabilidad Bivariantes Esperanza Bivariantes - CovarianzaAlain RamosAún no hay calificaciones
- Formulario AID 2021-01Documento7 páginasFormulario AID 2021-01FernandoAún no hay calificaciones
- Ultimo Parcial EstadisticaDocumento6 páginasUltimo Parcial EstadisticaElSirGutiAún no hay calificaciones
- Electro ResueltoDocumento6 páginasElectro ResueltoJerson Flores QuispeAún no hay calificaciones
- Mas Sinreposición Errorabsoluto 2021cDocumento20 páginasMas Sinreposición Errorabsoluto 2021cMaurizio StrokesAún no hay calificaciones
- Formulario - Examen v4Documento4 páginasFormulario - Examen v4Alvaro Sanchez GonzalezAún no hay calificaciones
- Taller Colaborativo IIDocumento18 páginasTaller Colaborativo IIJuan Sebastian Cote DominguezAún no hay calificaciones
- Análisis de Esfuerzos CombinadosDocumento8 páginasAnálisis de Esfuerzos CombinadosJuan LadinoAún no hay calificaciones
- β1Documento18 páginasβ1Kang HyukAún no hay calificaciones
- Notsa 3 Sflropq 1Documento14 páginasNotsa 3 Sflropq 1Kang HyukAún no hay calificaciones
- Econometría Aplicada de Series TemporalesDocumento5 páginasEconometría Aplicada de Series TemporalesKang HyukAún no hay calificaciones
- Solución Problemas Macroeconomia IV (Marzo 08)Documento16 páginasSolución Problemas Macroeconomia IV (Marzo 08)dianaome_92Aún no hay calificaciones
- Actividad 3 Mercado de DivisasDocumento5 páginasActividad 3 Mercado de DivisasKang HyukAún no hay calificaciones
- Interuf 262 - OKHA303-062Documento2 páginasInteruf 262 - OKHA303-062jimeneajAún no hay calificaciones
- Fresadora ProDocumento33 páginasFresadora ProRafael AlvaradoAún no hay calificaciones
- Problema 4.26 Fogler PDFDocumento4 páginasProblema 4.26 Fogler PDFMauricio Monguí RodríguezAún no hay calificaciones
- Guia Practica Laboratorio Teledeteccion - Idrisi AndesDocumento81 páginasGuia Practica Laboratorio Teledeteccion - Idrisi AndeskateborghiAún no hay calificaciones
- Mantenimiento Al Sistema de Refrigeración Del MotorDocumento58 páginasMantenimiento Al Sistema de Refrigeración Del MotorLuis Sanchez75% (4)
- Uasd Iem-2020 Unidad No.4.1Documento5 páginasUasd Iem-2020 Unidad No.4.1Eric Manuel Mercedes AbreuAún no hay calificaciones
- Blindaje LíquidoDocumento2 páginasBlindaje Líquidosiddartha5612Aún no hay calificaciones
- Informe 6 RoxDocumento20 páginasInforme 6 RoxAlexis Puente BurgaAún no hay calificaciones
- Informe de Gra...Documento59 páginasInforme de Gra...Armando RojasAún no hay calificaciones
- Estudio de CalicatasDocumento40 páginasEstudio de CalicatasGerman BarrosAún no hay calificaciones
- Cultura y Civilización.Documento5 páginasCultura y Civilización.gabrielAún no hay calificaciones
- Reconocimiento Del Terreno PDFDocumento79 páginasReconocimiento Del Terreno PDFFranco Ibacache RivasAún no hay calificaciones
- Comparación Normas Asshto y Covenin para PuentesDocumento106 páginasComparación Normas Asshto y Covenin para PuentesAlejandro Alfonzo100% (1)
- Microsoft Word - Relación Entre El Impulso de Una Fuerza y Cantidad de MovimientoDocumento1 páginaMicrosoft Word - Relación Entre El Impulso de Una Fuerza y Cantidad de MovimientoLuis Gómez PérezAún no hay calificaciones
- Reciclado Con Cemento PDFDocumento45 páginasReciclado Con Cemento PDFAlvaro Eloy Uría ArrayaAún no hay calificaciones
- Cuidados de Acuario PDFDocumento74 páginasCuidados de Acuario PDFalfredo100% (2)
- 5 Nrf-090-Pemex-2013Documento43 páginas5 Nrf-090-Pemex-2013Jorge Luis Sosa MorenoAún no hay calificaciones
- Informe Medios de Medición y CalibraciónDocumento10 páginasInforme Medios de Medición y CalibraciónAriasZaldivarJesúsMiguelAún no hay calificaciones
- Ventilador Marco TeoricoDocumento8 páginasVentilador Marco TeoricoHector AlvaradoAún no hay calificaciones
- Ballerina Jabon Liquido Algas Marinas Hoja Seguridad PDFDocumento6 páginasBallerina Jabon Liquido Algas Marinas Hoja Seguridad PDFJonathan Erly Chalco Pari100% (1)
- Mezclador Giratorio Cat RM300 PDFDocumento16 páginasMezclador Giratorio Cat RM300 PDFCarlos Alfredo LauraAún no hay calificaciones
- Mecanica VentilatoriaDocumento8 páginasMecanica VentilatoriaAlexander VillaAún no hay calificaciones
- Resueltos A Problemas Tipo - CapacitoresDocumento2 páginasResueltos A Problemas Tipo - CapacitoresFlorenciaGarcia100% (3)
- Bitácora 13. CorrecciónDocumento3 páginasBitácora 13. CorrecciónMelina HernándezAún no hay calificaciones
- Ejercicios de Sedimentacion LibreDocumento11 páginasEjercicios de Sedimentacion LibreKelly Ramos100% (2)
- Curso Carpinteria de AluminioDocumento3 páginasCurso Carpinteria de AluminioGerardoAún no hay calificaciones