También podría gustarte
- Neumática y ElectroneumáticaDocumento30 páginasNeumática y ElectroneumáticaJosé Luis Hernández NavaAún no hay calificaciones
- La OratoriaDocumento18 páginasLa OratoriaReciclaje ArtísticoAún no hay calificaciones
- CODELCO - ESPESADORES Apendice - 1.7-Manual - de - OperacionesDocumento61 páginasCODELCO - ESPESADORES Apendice - 1.7-Manual - de - Operacionesipla_mecanicoAún no hay calificaciones
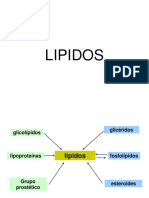
- Lipidos 29048Documento113 páginasLipidos 29048Johan Miguel Camargo LAún no hay calificaciones
- RotacionalDocumento4 páginasRotacionalJuan Carlos MoralesAún no hay calificaciones
- Informe AnaliticaDocumento12 páginasInforme AnaliticaVíctor ValdezAún no hay calificaciones
- Física 5to Año PDFDocumento158 páginasFísica 5to Año PDFcrisar10100% (3)
- 2.1 Solución de Problemas Con BúsquedaDocumento37 páginas2.1 Solución de Problemas Con BúsquedaIvan Lopez MartinezAún no hay calificaciones
- Biomimetica 1Documento2 páginasBiomimetica 1Johnny DávilaAún no hay calificaciones
- 5.2. Zumos o Jugos, Pulpas yDocumento34 páginas5.2. Zumos o Jugos, Pulpas yNilton Madera QuispeAún no hay calificaciones
- Cálculo de La Carga Crítica de Pandeo en PórticosDocumento5 páginasCálculo de La Carga Crítica de Pandeo en PórticosFrank Palacios DelgadoAún no hay calificaciones
- 1.-Libro - Introduccion GnosisDocumento35 páginas1.-Libro - Introduccion GnosisLuis Reinaldo Yantalima50% (2)
- NOM024 VibracionesDocumento20 páginasNOM024 VibracionesDaniel CastilloAún no hay calificaciones
- UNI Clase Elasticidad PDFDocumento28 páginasUNI Clase Elasticidad PDFJAMILL RAUL SANCHEZ HUARACAAún no hay calificaciones
- Segunda Prueba de Avance Ciencias Naturales Segundo Ao de Bachillerato - Praem 2014 PDFDocumento17 páginasSegunda Prueba de Avance Ciencias Naturales Segundo Ao de Bachillerato - Praem 2014 PDFMarvin AlfaroAún no hay calificaciones
- Alcantara Arce Arik Jhonatan PDFDocumento119 páginasAlcantara Arce Arik Jhonatan PDFFernando Zavaleta MuñozAún no hay calificaciones
- DESCARBURACIONDocumento3 páginasDESCARBURACIONIvan Francisco Montejo Rodriguez100% (1)
- Pasos para Trazar Curvas A Nivel y A DesnivelDocumento3 páginasPasos para Trazar Curvas A Nivel y A DesnivelMarvinLeonelMRamirez100% (1)
- 08 - Protección de Las InstalacionesDocumento26 páginas08 - Protección de Las InstalacionesKoslerAún no hay calificaciones
- Funciones EconomicasDocumento9 páginasFunciones Economicasfeder_hAún no hay calificaciones
- FLUIDOOOOOOOOOOOOOOOOOODocumento2 páginasFLUIDOOOOOOOOOOOOOOOOOOSantiagoAún no hay calificaciones
- EJERCICIOS Movimiento CinematicaDocumento2 páginasEJERCICIOS Movimiento CinematicaSantiago Ospina GutiérrezAún no hay calificaciones
- ConjuntosDocumento12 páginasConjuntosHenryk JácomeAún no hay calificaciones
- Coupon Holders - SpanishDocumento2 páginasCoupon Holders - SpanishCarlos EduardoAún no hay calificaciones
- TDS Español - Varathane - RainCoat - Transparente - Base AguaDocumento3 páginasTDS Español - Varathane - RainCoat - Transparente - Base AguaХьюгоAún no hay calificaciones
- GUIA INFORMATIVA 2 Decimo - Calor y TemperaturaDocumento4 páginasGUIA INFORMATIVA 2 Decimo - Calor y TemperaturaQuimica Sebastiana100% (1)
- Actividad-1-MATERIALES DE INGENIERÍA Y LABORATORIODocumento17 páginasActividad-1-MATERIALES DE INGENIERÍA Y LABORATORIOJaime Eduardo Guzmán MorenoAún no hay calificaciones
- Original3 PDFDocumento6 páginasOriginal3 PDFDaniela SanchezAún no hay calificaciones
- Analisis de Sensibilidad Del Proyecto de Fabrica de TelasDocumento6 páginasAnalisis de Sensibilidad Del Proyecto de Fabrica de TelasKevin Paul Celis LlamocaAún no hay calificaciones
- Tutorial Multi Spec. Deteccion de CambiosDocumento13 páginasTutorial Multi Spec. Deteccion de CambiosAlexis LetzenAún no hay calificaciones