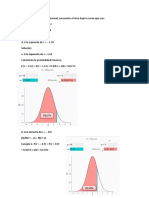
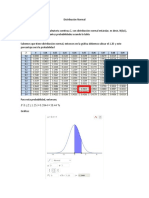
También podría gustarte
- Estadística - Guía 5 y 6Documento20 páginasEstadística - Guía 5 y 6NATALIA TORRESAún no hay calificaciones
- Clase 6 Límites de ConfianzaDocumento7 páginasClase 6 Límites de Confianzajhon APOLINARAún no hay calificaciones
- Taller Estadistica KellyDocumento9 páginasTaller Estadistica KellyEduardo CiroAún no hay calificaciones
- GUIA 3 EstadisticaDocumento6 páginasGUIA 3 EstadisticaFelipe GutierrezAún no hay calificaciones
- Guia de Trabajo Numero 3Documento7 páginasGuia de Trabajo Numero 3Sebastian EncisoAún no hay calificaciones
- Ejercicios EstadisticaDocumento11 páginasEjercicios EstadisticaMonica Fernanda Obando HenaoAún no hay calificaciones
- Ejercicios de AutoevaluacionDocumento13 páginasEjercicios de AutoevaluacionYesenia HernandezAún no hay calificaciones
- SimulacionDocumento6 páginasSimulacionPaula Rodriguez Sanchez100% (1)
- Hoja Trabajo Semana15 NormalDocumento6 páginasHoja Trabajo Semana15 NormalANDREW STEVEN VEGA REYESAún no hay calificaciones
- Diseño de Controladores Con Matlab Umss FcytDocumento12 páginasDiseño de Controladores Con Matlab Umss FcytmarrAún no hay calificaciones
- Actividad N - 2 EstadisticaDocumento9 páginasActividad N - 2 EstadisticaJonathan MartinezAún no hay calificaciones
- Prueba #3 - Estadística A. - Gabriela Maureira M.Documento6 páginasPrueba #3 - Estadística A. - Gabriela Maureira M.Gabriela MaureiraAún no hay calificaciones
- Tarea 2 EstadisticaDocumento7 páginasTarea 2 Estadisticakevin acuñaAún no hay calificaciones
- Tarea 2 Problemas 1-5 Capitulo 2 MontgomeryDocumento8 páginasTarea 2 Problemas 1-5 Capitulo 2 MontgomeryWILLAún no hay calificaciones
- TAREA 2 - Algebra y TrigonometriaDocumento10 páginasTAREA 2 - Algebra y TrigonometriaOscar OrdoñezAún no hay calificaciones
- Solución Ejercicios 53 PDFDocumento8 páginasSolución Ejercicios 53 PDFJuan Felipe Moreno RodriguezAún no hay calificaciones
- Exatraordinario Resuelto 2022Documento3 páginasExatraordinario Resuelto 2022Ainhoa CarrascoAún no hay calificaciones
- TLC ResueltosDocumento12 páginasTLC Resueltosdaniki kikikiAún no hay calificaciones
- Taller 4. Distribución NormalDocumento4 páginasTaller 4. Distribución NormalbrayancabezasAún no hay calificaciones
- R24 NormalDocumento7 páginasR24 NormalOscar RobertoAún no hay calificaciones
- Estimacion de La Diferencia de ProporcionesDocumento8 páginasEstimacion de La Diferencia de ProporcionesSantos Josue Romero OchoaAún no hay calificaciones
- Estadística Examen Final - SolucionarioDocumento5 páginasEstadística Examen Final - SolucionarioJhon Ortega GarciaAún no hay calificaciones
- Ejercicios Desde La 12 Hasta La 22Documento10 páginasEjercicios Desde La 12 Hasta La 22Sthephanie Cabrera100% (1)
- Ej Resueltos Distr NormalDocumento4 páginasEj Resueltos Distr NormalLuis Nexon GrandeAún no hay calificaciones
- Distribución Normal (Ejercicios)Documento4 páginasDistribución Normal (Ejercicios)Franklin R. Meza RodríguezAún no hay calificaciones
- EstadisticaDocumento7 páginasEstadisticaGeorge AscencioAún no hay calificaciones
- Guia 3Documento5 páginasGuia 3juiwscsk cckjsnkfnkAún no hay calificaciones
- Distribuciones Continuas - Maria CamilaDocumento18 páginasDistribuciones Continuas - Maria CamilaYenny Alexandra Bacca CuasapazAún no hay calificaciones
- Probabilidad Normal 3Documento6 páginasProbabilidad Normal 3Enrique Trejo Rodriguez100% (1)
- 2d +Instructivo+Uso+de+Tabla+ZDocumento5 páginas2d +Instructivo+Uso+de+Tabla+ZMiguel UBAún no hay calificaciones
- Integral DefinidaDocumento10 páginasIntegral DefinidaAlexander RamirezAún no hay calificaciones
- La Distribución NormalDocumento10 páginasLa Distribución Normaljose orozcoAún no hay calificaciones
- 2 Prob Bep 2Documento14 páginas2 Prob Bep 2Miguel Angel ArruaAún no hay calificaciones
- Guía de Ejercicios 12. Distribución NormalDocumento6 páginasGuía de Ejercicios 12. Distribución NormalDarkar launs100% (1)
- MCSIT14 Prob (Sol)Documento4 páginasMCSIT14 Prob (Sol)Abel Huaman AtaoAún no hay calificaciones
- Ejercicios Resueltos Binomial y NormalDocumento7 páginasEjercicios Resueltos Binomial y NormalCesarAntonioConchaAún no hay calificaciones
- Guía 3Documento14 páginasGuía 3David AcevedoAún no hay calificaciones
- Distribución Normal. Uso de La Tabla. Intervalos: VídeoDocumento16 páginasDistribución Normal. Uso de La Tabla. Intervalos: VídeoAmer Zayneh GhorbalAún no hay calificaciones
- Problemas Distribucion NormalDocumento3 páginasProblemas Distribucion NormalDatatools GYE-ECAún no hay calificaciones
- Resolucion Ejercicios Taller Capitulo 2 PDFDocumento3 páginasResolucion Ejercicios Taller Capitulo 2 PDFHugo Alfredo Benitez100% (1)
- Fisica ElectromagnetismoDocumento7 páginasFisica ElectromagnetismoJeferson Castañeda DuqueAún no hay calificaciones
- VelascoDocumento17 páginasVelascoSusana Pina MartinAún no hay calificaciones
- Taller Diseño Compensadore Rlocus en Tiempo ContinuoDocumento14 páginasTaller Diseño Compensadore Rlocus en Tiempo Continuo2420211039Aún no hay calificaciones
- Lee La Siguiente Situación y Realiza Lo SolicitadoDocumento6 páginasLee La Siguiente Situación y Realiza Lo SolicitadoAlejandra ZapataAún no hay calificaciones
- EJERCICIOS Estadistica InferencialDocumento6 páginasEJERCICIOS Estadistica InferencialNeisser Caruajulca100% (3)
- MATH.1001.220.T3.v1 RESUELTODocumento8 páginasMATH.1001.220.T3.v1 RESUELTOEnriqueAún no hay calificaciones
- Estadística y Probabilidades Semana 13Documento4 páginasEstadística y Probabilidades Semana 13iris maribel altamirano mocarroAún no hay calificaciones
- Ejercicios EstadisticaDocumento3 páginasEjercicios EstadisticaCristina PolentinoAún no hay calificaciones
- Trabajo IDocumento19 páginasTrabajo IFlorencioRuaRiverosAún no hay calificaciones
- Trabajo de Hipotesis ESTADISTICADocumento14 páginasTrabajo de Hipotesis ESTADISTICAcarlos100% (4)
- Practica Prueba de Hipotesis (Cap II)Documento58 páginasPractica Prueba de Hipotesis (Cap II)deymer nicson ruiz tirado50% (2)
- Distribución NormalDocumento18 páginasDistribución NormalJuan Arcila100% (2)
- Ejemplos Test de HipótesisDocumento12 páginasEjemplos Test de HipótesisNaim GuarinoAún no hay calificaciones
- Estadística Inferencial Guia Numero 3Documento12 páginasEstadística Inferencial Guia Numero 3julimariafarfisAún no hay calificaciones
- Laboratorio FísicaDocumento9 páginasLaboratorio Físicamayra isabel llerena calderonAún no hay calificaciones
- Macarena Squella Semana 5 Matemáticas OriginalDocumento8 páginasMacarena Squella Semana 5 Matemáticas Originalmacarena d.n. castillo squellaAún no hay calificaciones
- Actividad 1Documento8 páginasActividad 1Shyrley Johana Silva ReyesAún no hay calificaciones
- NormalDocumento6 páginasNormalAznaila K. Valencia CheroAún no hay calificaciones
- La guía definitiva en Matemáticas para el Ingreso al BachilleratoDe EverandLa guía definitiva en Matemáticas para el Ingreso al BachilleratoCalificación: 4.5 de 5 estrellas4.5/5 (9)
- Resumen Inv. OprDocumento12 páginasResumen Inv. OpralexanderAún no hay calificaciones
- Futbol, Hinchadas y Ciudad (Bogota)Documento249 páginasFutbol, Hinchadas y Ciudad (Bogota)OrianaAún no hay calificaciones
- Em Prend Uris MoDocumento3 páginasEm Prend Uris MoMilton SantiagoAún no hay calificaciones
- Silabo 2020 - A - Aseguramiento de La CalidadDocumento6 páginasSilabo 2020 - A - Aseguramiento de La CalidadBryan Alexander SanchezAún no hay calificaciones
- Diseño y Propuesta de Mejora Del Proceso de Auditoria Concurrente Interna en El Instituto Cardiovascular-Fundación CardiovascularDocumento77 páginasDiseño y Propuesta de Mejora Del Proceso de Auditoria Concurrente Interna en El Instituto Cardiovascular-Fundación CardiovascularKatherine CardonaAún no hay calificaciones
- Programacion LinealDocumento10 páginasProgramacion LinealFabian Andres Diaz MalpikAún no hay calificaciones
- Material HerramientasDocumento83 páginasMaterial HerramientasSilvia Gonzalez TiznadoAún no hay calificaciones
- Compliance y Anticorrupción 2019Documento8 páginasCompliance y Anticorrupción 2019Roxana AcevedoAún no hay calificaciones
- Trabajo de Investigación para Eureka 2023Documento5 páginasTrabajo de Investigación para Eureka 2023Yare Fernandez TorresAún no hay calificaciones
- Epi ModernaDocumento11 páginasEpi ModernaDante SegoviaAún no hay calificaciones
- Metodos de InvestigaciónDocumento18 páginasMetodos de InvestigaciónGladys de LeónAún no hay calificaciones
- Introducción A La AdminDocumento18 páginasIntroducción A La AdminFernanda RoaAún no hay calificaciones
- Practica N°1 - PresentaciónDocumento5 páginasPractica N°1 - PresentaciónNikoll BellidoAún no hay calificaciones
- Formacion Ciudadana Quinto Basico.Documento4 páginasFormacion Ciudadana Quinto Basico.Alex ViverosAún no hay calificaciones
- S08.s1 PSICOLOGÍA SOCIAL-COMUNITARIADocumento14 páginasS08.s1 PSICOLOGÍA SOCIAL-COMUNITARIALucia Benavides MayauteAún no hay calificaciones
- CUADRO SINOPTICO-ing SistemasDocumento2 páginasCUADRO SINOPTICO-ing SistemasTuClase ClassAún no hay calificaciones
- INV. de OPERACIONES IGE Clase 6 Teoria de DesicionesDocumento98 páginasINV. de OPERACIONES IGE Clase 6 Teoria de DesicionesJRoberto CoronaAún no hay calificaciones
- El Método ObservacionalDocumento1 páginaEl Método ObservacionalElizabeth Urbano IrribarrenAún no hay calificaciones
- Dictamen Cuam 2022Documento8 páginasDictamen Cuam 2022Quetzalia Hernández DuránAún no hay calificaciones
- Cuestionario CuadroDocumento4 páginasCuestionario CuadroEltowersAún no hay calificaciones
- Aproximación Al Análisis Cualitativo de Redes Sociales.Documento23 páginasAproximación Al Análisis Cualitativo de Redes Sociales.Karla HenríquezAún no hay calificaciones
- Hernandez - Maria - Act9 - Habilidades - Del - Pensamiento - para - La - Toma - de DecisionesDocumento34 páginasHernandez - Maria - Act9 - Habilidades - Del - Pensamiento - para - La - Toma - de DecisionesNataly Sheccid Montes de OcaAún no hay calificaciones
- Hoja de Trabajo Tema Investigacion CualitativaDocumento8 páginasHoja de Trabajo Tema Investigacion CualitativaOmar EscobarAún no hay calificaciones
- Distribucion GammaDocumento3 páginasDistribucion GammamiguelbromeroAún no hay calificaciones
- Formato Tesis InvestigacionDocumento59 páginasFormato Tesis InvestigacionPamela RamosAún no hay calificaciones
- Evaluacion A Distancia Olga Lucia GarayDocumento12 páginasEvaluacion A Distancia Olga Lucia GarayGaol GarayAún no hay calificaciones
- Teoria Econometrica IDocumento210 páginasTeoria Econometrica Ilvzm1Aún no hay calificaciones
- Teorías de Los TestsDocumento18 páginasTeorías de Los Testsmelany1de1los-848806Aún no hay calificaciones
- Econ Enc Ara 2020Documento154 páginasEcon Enc Ara 2020carlosAún no hay calificaciones
- Trabajo Colaborativo de ProbabilidadDocumento18 páginasTrabajo Colaborativo de ProbabilidadJuan CaceresAún no hay calificaciones