También podría gustarte
- Problemas resueltos de Hidráulica de CanalesDe EverandProblemas resueltos de Hidráulica de CanalesCalificación: 4.5 de 5 estrellas4.5/5 (7)
- Métodos Matriciales para ingenieros con MATLABDe EverandMétodos Matriciales para ingenieros con MATLABCalificación: 5 de 5 estrellas5/5 (1)
- Preguntas Tipo YBDocumento8 páginasPreguntas Tipo YBDavid MartínezAún no hay calificaciones
- Planificación MATEMÁTICA 2° 2023Documento12 páginasPlanificación MATEMÁTICA 2° 2023claudia acevedo100% (1)
- Libro de Hernia InguinalDocumento380 páginasLibro de Hernia Inguinalapi-2618823291% (11)
- Geometric modeling in computer: Aided geometric designDe EverandGeometric modeling in computer: Aided geometric designAún no hay calificaciones
- Propuestos Desarrollados Del Cap 6Documento27 páginasPropuestos Desarrollados Del Cap 6FranzOcrospoma100% (1)
- Ejercicios PropuestosDocumento6 páginasEjercicios PropuestosRoberto SalinasAún no hay calificaciones
- Introducción a MATLAB: Vectores, matrices, gráficos y programaciónDocumento129 páginasIntroducción a MATLAB: Vectores, matrices, gráficos y programaciónAlexander Gómez LlallahuiAún no hay calificaciones
- Sesion01 ANDALP PPTDocumento36 páginasSesion01 ANDALP PPTRebeca Olivares montesAún no hay calificaciones
- Gonzalo_Valdiviezo_PE_Taller3 EstocasticosDocumento7 páginasGonzalo_Valdiviezo_PE_Taller3 EstocasticosTania BasantesAún no hay calificaciones
- Ejercicios condicionales Python área volumenDocumento15 páginasEjercicios condicionales Python área volumenArianna Castano BedoyaAún no hay calificaciones
- Progamacin III TPDocumento20 páginasProgamacin III TProxiblumerAún no hay calificaciones
- ProgamacionIII 1c2014 TP Guia de EjerciciosDocumento20 páginasProgamacionIII 1c2014 TP Guia de EjerciciosFedericoAún no hay calificaciones
- Complejidad Computacional Estructura de DatosDocumento38 páginasComplejidad Computacional Estructura de DatosJosé Nicolás Jorquera HerreraAún no hay calificaciones
- Tema 5 Redes Optimizacion Sesion 2Documento20 páginasTema 5 Redes Optimizacion Sesion 2Jhannette CayojaAún no hay calificaciones
- ANÁLISIS COMPLEJIDAD ALGORITMOSDocumento32 páginasANÁLISIS COMPLEJIDAD ALGORITMOSFrank Leny Ccapa UscaAún no hay calificaciones
- Divide y VencerásDocumento25 páginasDivide y VencerásLoreann ValenciaAún no hay calificaciones
- UNISAL-Orán guía TP0 repaso diagramaciónDocumento3 páginasUNISAL-Orán guía TP0 repaso diagramaciónL.RobledoAún no hay calificaciones
- Divide y vencerás: técnica de diseño de algoritmos recursivosDocumento7 páginasDivide y vencerás: técnica de diseño de algoritmos recursivosandres blancoAún no hay calificaciones
- Algoritmia y Metodos de Acceso - EficienciaDocumento29 páginasAlgoritmia y Metodos de Acceso - EficienciaVictor CherreAún no hay calificaciones
- Ejercicios ResueltosDocumento31 páginasEjercicios ResueltosMarcos Ramos0% (1)
- Eficiencia de Algoritmos PDFDocumento67 páginasEficiencia de Algoritmos PDFJairo MolinaAún no hay calificaciones
- Lab 1. Introducción A ScilabDocumento6 páginasLab 1. Introducción A ScilabMaria SAún no hay calificaciones
- Algoritmos de Búsqueda y OrdenaciónDocumento107 páginasAlgoritmos de Búsqueda y Ordenacióntsuru108Aún no hay calificaciones
- Algoritmos y ProgramaciónDocumento13 páginasAlgoritmos y ProgramacióndanielaAún no hay calificaciones
- 6.1 Redes y Flujo (15 Mayo)Documento18 páginas6.1 Redes y Flujo (15 Mayo)CarolinaAún no hay calificaciones
- Guia 3 AD, JR, MS, LCDocumento13 páginasGuia 3 AD, JR, MS, LCAdriana De León CortezAún no hay calificaciones
- Tarea1 WilderDocumento6 páginasTarea1 WilderWilder Gonzalez DiazAún no hay calificaciones
- 7 Notación AsintóticaDocumento25 páginas7 Notación AsintóticaLuis Ramirez CoronadoAún no hay calificaciones
- Optimización en redes: conceptos básicos y problemasDocumento34 páginasOptimización en redes: conceptos básicos y problemasMayte Peralta BuendíaAún no hay calificaciones
- Análisis de señales continuasDocumento14 páginasAnálisis de señales continuasErick Machado100% (1)
- Introduccion Al Diseño de Curvas Por OrdenadorDocumento13 páginasIntroduccion Al Diseño de Curvas Por OrdenadorRoger Lazaro CruzAún no hay calificaciones
- Trabajo 04Documento10 páginasTrabajo 04aero356Aún no hay calificaciones
- 66 Problemas Resueltos de Análisis y Diseño de AlgoritmosDocumento82 páginas66 Problemas Resueltos de Análisis y Diseño de AlgoritmosLaenetGalumetteJosephJuniorPaulAún no hay calificaciones
- OMPDocumento22 páginasOMPJorge Díaz NavarroAún no hay calificaciones
- 4 EDyA1 RecursividadDocumento12 páginas4 EDyA1 RecursividadJUAN FELIPE GOMEZ MOLINAAún no hay calificaciones
- Divide y Venceras: Resolución de problemas mediante subdivisión recursivaDocumento16 páginasDivide y Venceras: Resolución de problemas mediante subdivisión recursivaIngeniero DelphiAún no hay calificaciones
- CompiladoDocumento380 páginasCompiladoDiego SilvaAún no hay calificaciones
- Examen PDFDocumento26 páginasExamen PDFFranAún no hay calificaciones
- Rpyatp 02Documento4 páginasRpyatp 02api-377694349100% (1)
- Informe - Tema 01Documento36 páginasInforme - Tema 01Raul Depaz NuñezAún no hay calificaciones
- MAT430 Cálculo II - Taller de diseño de caja de vidrioDocumento4 páginasMAT430 Cálculo II - Taller de diseño de caja de vidrionvsm22Aún no hay calificaciones
- Guion 2 Codificacion AritmeticaDocumento8 páginasGuion 2 Codificacion AritmeticaLidia LópezAún no hay calificaciones
- Ipython E.DDocumento41 páginasIpython E.DCristian Brian ALMARAZ ROCHAAún no hay calificaciones
- Practica 3 2-2020Documento2 páginasPractica 3 2-2020Miguel Angel Fernández EquizaAún no hay calificaciones
- Teoria de Los Números Paso-2-Actividad-Colaborativa-Grupo - 8Documento14 páginasTeoria de Los Números Paso-2-Actividad-Colaborativa-Grupo - 8yeseniaAún no hay calificaciones
- Tema Algoritmos 2024Documento75 páginasTema Algoritmos 2024Daniel Robinson GutierrezAún no hay calificaciones
- Dynamic Programming GreedyDocumento92 páginasDynamic Programming GreedyclaudioAún no hay calificaciones
- Cap I IntrodDocumento51 páginasCap I IntrodVilchez RodriguezAún no hay calificaciones
- Sol Práctica Grupal Pert CPMDocumento5 páginasSol Práctica Grupal Pert CPMLUIS ANGEL CHAVEZ SALAZARAún no hay calificaciones
- Curso Matlab 1Documento16 páginasCurso Matlab 1anon_22914928Aún no hay calificaciones
- Examen Parcial de Fundamentos de ProgramaciónDocumento3 páginasExamen Parcial de Fundamentos de ProgramaciónEsteban GuadarramaAún no hay calificaciones
- Practica TLP 1819Documento11 páginasPractica TLP 1819Luis Moreno GonzalezAún no hay calificaciones
- Tema 4Documento18 páginasTema 4ROGERAún no hay calificaciones
- Cuestionario de PythonDocumento6 páginasCuestionario de PythonCristhian Franklin Ccaso AtencioAún no hay calificaciones
- Lab 3 Sistemas de Control 30092021Documento9 páginasLab 3 Sistemas de Control 30092021Adalid elaprendizAún no hay calificaciones
- Cuestionario 03 Grupo 1 B, ESMI (Primer Grado)Documento5 páginasCuestionario 03 Grupo 1 B, ESMI (Primer Grado)Cristhian Franklin Ccaso AtencioAún no hay calificaciones
- 1.2 Analisis de AlgoritmosDocumento20 páginas1.2 Analisis de AlgoritmosWilfredo Bacilio AlarcónAún no hay calificaciones
- Transporte Gye Cuenca 28 de JulioDocumento2 páginasTransporte Gye Cuenca 28 de JulioDavid MartínezAún no hay calificaciones
- Alimentacion 11 Jde JulioDocumento2 páginasAlimentacion 11 Jde JulioDavid MartínezAún no hay calificaciones
- Alimentacion 8 de JulioDocumento2 páginasAlimentacion 8 de JulioDavid MartínezAún no hay calificaciones
- Instalación de OsirixDocumento1 páginaInstalación de OsirixDavid MartínezAún no hay calificaciones
- Alimentacion 2 Cuenca 5 de JulioDocumento2 páginasAlimentacion 2 Cuenca 5 de JulioDavid MartínezAún no hay calificaciones
- Alimentacion Cuenca 5 JulioDocumento2 páginasAlimentacion Cuenca 5 JulioDavid MartínezAún no hay calificaciones
- Alimentacion Cuenca 28 de JulioDocumento2 páginasAlimentacion Cuenca 28 de JulioDavid MartínezAún no hay calificaciones
- CBMRI Interaccion GammaDocumento27 páginasCBMRI Interaccion GammaNeysa UriolAún no hay calificaciones
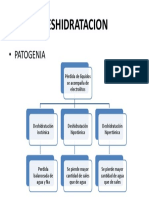
- DeshidratacionDocumento1 páginaDeshidratacionDavid MartínezAún no hay calificaciones
- Manual Deu SoDocumento3 páginasManual Deu SoTaykerouAún no hay calificaciones
- El Electrocardiograma en Reposo de 12 Derivaciones: Experimento de Laboratorio D-7Documento31 páginasEl Electrocardiograma en Reposo de 12 Derivaciones: Experimento de Laboratorio D-7David MartínezAún no hay calificaciones
- DeshidratacionDocumento1 páginaDeshidratacionDavid MartínezAún no hay calificaciones
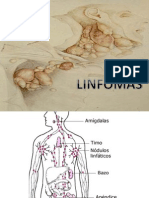
- Linfomas 091106125519 Phpapp01Documento115 páginasLinfomas 091106125519 Phpapp01Iris DuarteAún no hay calificaciones
- SemioDocumento2 páginasSemioDavid MartínezAún no hay calificaciones
- Problemas - Transistores MosfetDocumento15 páginasProblemas - Transistores Mosfetedwinrr7Aún no hay calificaciones
- HT SecundariaDocumento9 páginasHT SecundariaDavid MartínezAún no hay calificaciones
- FORENSEDocumento7 páginasFORENSEDavid MartínezAún no hay calificaciones
- Tutorial de Linux - Comandos de LinuxDocumento18 páginasTutorial de Linux - Comandos de LinuxinfobitsAún no hay calificaciones
- Instalación de OsirixDocumento1 páginaInstalación de OsirixDavid MartínezAún no hay calificaciones
- Manual Deu SoDocumento3 páginasManual Deu SoTaykerouAún no hay calificaciones
- Aciones Olfticas Icaciones: RESOLUCION 132-05-CONATEL-2009Documento7 páginasAciones Olfticas Icaciones: RESOLUCION 132-05-CONATEL-2009David MartínezAún no hay calificaciones
- Consultas en AccessDocumento9 páginasConsultas en AccessMatrox5Aún no hay calificaciones
- LibritoDocumento15 páginasLibritoPatric Medeiros da Silva0% (1)
- 47-LIBRO Probabilidad Combinatoria Ejercicios Resueltos OKDocumento179 páginas47-LIBRO Probabilidad Combinatoria Ejercicios Resueltos OKBautista AnaAún no hay calificaciones
- p5 Procesos PDFDocumento6 páginasp5 Procesos PDFDavid MartínezAún no hay calificaciones
- Wireless Brochure10 EneDocumento8 páginasWireless Brochure10 EneDavid MartínezAún no hay calificaciones
- Cuestionario Licencias Tipo B (1) Ecuador 2015Documento48 páginasCuestionario Licencias Tipo B (1) Ecuador 2015Eduardo CalvachiAún no hay calificaciones
- Programa de Estudio 2° Medio MatemáticaDocumento80 páginasPrograma de Estudio 2° Medio MatemáticaJorge Herrera AravenaAún no hay calificaciones
- Representacion de GrafosDocumento2 páginasRepresentacion de GrafosRicardo Daniel GomAún no hay calificaciones
- Actividades de Laboratorio Capítulo 1 ENUNCIADOS GEOGEBRA PDFDocumento6 páginasActividades de Laboratorio Capítulo 1 ENUNCIADOS GEOGEBRA PDFsatragbiAún no hay calificaciones
- RecursividadDocumento8 páginasRecursividadCortes WilAún no hay calificaciones
- La Ciencia GriegaDocumento17 páginasLa Ciencia GriegaLpSicoD RecordsAún no hay calificaciones
- Interpolación inversa en ingeniería civilDocumento26 páginasInterpolación inversa en ingeniería civilmaria massielAún no hay calificaciones
- 09 Trigonometria RocaDocumento13 páginas09 Trigonometria RocaRICHAR GUEVARA CHIQUILLANAún no hay calificaciones
- Pauta Control 4Documento5 páginasPauta Control 4Nicolás Arrué GálvezAún no hay calificaciones
- Prueba Factorizacion Simplificacion InduccionDocumento5 páginasPrueba Factorizacion Simplificacion InduccionFre Cuevas100% (4)
- Pauta p1 Io1 (D) Utem 23-8-16Documento6 páginasPauta p1 Io1 (D) Utem 23-8-16victorherediafAún no hay calificaciones
- 03.1 - Espectro de Diseño NSR - 10 (Microzonificación) BL-1Documento9 páginas03.1 - Espectro de Diseño NSR - 10 (Microzonificación) BL-1Ingeniero Luis Duran DyeAún no hay calificaciones
- Integral DefinidaDocumento8 páginasIntegral DefinidaEfraín Gustavo estradaAún no hay calificaciones
- Metodo de KinchDocumento10 páginasMetodo de KinchRichi DPAún no hay calificaciones
- Conjunto SDocumento5 páginasConjunto SMaran Apaza Champi100% (1)
- Capas Cilíndricas - PrimeraParteDocumento30 páginasCapas Cilíndricas - PrimeraParteMarlon Alejandro GutierrezAún no hay calificaciones
- Probabilidad HidrologicaDocumento54 páginasProbabilidad HidrologicaOscar Sánchez SosaAún no hay calificaciones
- Proceso Isooctano - CSTR-Cinética de Reacción - Dic 01,2013Documento6 páginasProceso Isooctano - CSTR-Cinética de Reacción - Dic 01,2013sin nombreAún no hay calificaciones
- Usos de GeogebraDocumento7 páginasUsos de GeogebraCesar Felipe MoralesAún no hay calificaciones
- Módulo de Algebra Lineal-005Documento9 páginasMódulo de Algebra Lineal-005Eder MartínezAún no hay calificaciones
- 2.2 Lineas de Transmision - Parte 2 EcuadorDocumento58 páginas2.2 Lineas de Transmision - Parte 2 EcuadorFreed MolignanoAún no hay calificaciones
- Herramientas Matematicas DigitalesDocumento4 páginasHerramientas Matematicas DigitalesRamirez CeciAún no hay calificaciones
- Relaciones binarias, producto cartesiano y par ordenadoDocumento6 páginasRelaciones binarias, producto cartesiano y par ordenadoRony ValdezAún no hay calificaciones
- Algebra Lineal: Ecuaciones Vectoriales y Sistemas LinealesDocumento81 páginasAlgebra Lineal: Ecuaciones Vectoriales y Sistemas LinealesDIANA MARIA LOPEZ ALVAREZAún no hay calificaciones
- Silabo de Geometria I.E #1230FDocumento3 páginasSilabo de Geometria I.E #1230FJulia GarciaAún no hay calificaciones
- Ejercicios de MateDocumento50 páginasEjercicios de MateJhasmany FtAún no hay calificaciones
- Capitulo 07, 2013Documento11 páginasCapitulo 07, 2013Abraham PerezAún no hay calificaciones
- Presentacion Solidos de RevolucionDocumento55 páginasPresentacion Solidos de RevolucionMiller Palacio NuñezAún no hay calificaciones
- Formulas de Identidades TrigonométricasDocumento10 páginasFormulas de Identidades TrigonométricasDanilo ArévaloAún no hay calificaciones