También podría gustarte
- Resolucion.° 107-2022 - Vi - Ucv .Documento4 páginasResolucion.° 107-2022 - Vi - Ucv .Edwing Maquera FloresAún no hay calificaciones
- Memorandum Mut. #009 Solicito Informe Del Proceso de Enseñanza Durante El Semestre Académico 2022-IiDocumento1 páginaMemorandum Mut. #009 Solicito Informe Del Proceso de Enseñanza Durante El Semestre Académico 2022-IiEdwing Maquera FloresAún no hay calificaciones
- Pronunciamiento OkeyDocumento1 páginaPronunciamiento OkeyEdwing Maquera FloresAún no hay calificaciones
- 1-Practicas Patria, Nación, Estado...Documento1 página1-Practicas Patria, Nación, Estado...Edwing Maquera FloresAún no hay calificaciones
- 6to - Cyt - Ficha Método Científico - Semana 5Documento1 página6to - Cyt - Ficha Método Científico - Semana 5Edwing Maquera FloresAún no hay calificaciones
- Resolución #033 2023 Co UnajmaDocumento3 páginasResolución #033 2023 Co UnajmaEdwing Maquera FloresAún no hay calificaciones
- 6to - Com - Ficha 1 - Semana 5 - Uso de Los Recursos Ortograficos C, S y ZDocumento2 páginas6to - Com - Ficha 1 - Semana 5 - Uso de Los Recursos Ortograficos C, S y ZEdwing Maquera FloresAún no hay calificaciones
- 6to Com Ficha Semana 08 AnalogíasDocumento2 páginas6to Com Ficha Semana 08 AnalogíasEdwing Maquera FloresAún no hay calificaciones
- 6to - Com - Ficha 1 - Semana 5 - Uso de Los Recursos Ortograficos C, S y ZDocumento2 páginas6to - Com - Ficha 1 - Semana 5 - Uso de Los Recursos Ortograficos C, S y ZEdwing Maquera FloresAún no hay calificaciones
- Directiva Del Examen de Suficiencia Virtual 2023-00Documento3 páginasDirectiva Del Examen de Suficiencia Virtual 2023-00Edwing Maquera FloresAún no hay calificaciones
- 6to - Com - Ficha - Semana 4 - Categoría Gramatical (Taller Abp)Documento4 páginas6to - Com - Ficha - Semana 4 - Categoría Gramatical (Taller Abp)Edwing Maquera FloresAún no hay calificaciones
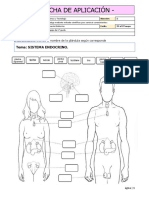
- 6to - Cyt - Ficha 1 Semana 1aparato Endocrino (Taller Abp)Documento2 páginas6to - Cyt - Ficha 1 Semana 1aparato Endocrino (Taller Abp)Edwing Maquera FloresAún no hay calificaciones
- 6TO CYT FICHA Cambios de Estado Ficha ABPDocumento1 página6TO CYT FICHA Cambios de Estado Ficha ABPEdwing Maquera FloresAún no hay calificaciones
- 6to - Cyt - Ficha 1 Semana - 1 Aparato Endocrino (Laboratorio - Abp)Documento1 página6to - Cyt - Ficha 1 Semana - 1 Aparato Endocrino (Laboratorio - Abp)Edwing Maquera FloresAún no hay calificaciones
- 6to - Cyt - Ficha Método Científico - Semana 5Documento1 página6to - Cyt - Ficha Método Científico - Semana 5Edwing Maquera FloresAún no hay calificaciones
- 6to - Mat - Ficha - Semana 03 - Ecuaciones de Primer GradoDocumento2 páginas6to - Mat - Ficha - Semana 03 - Ecuaciones de Primer GradoEdwing Maquera FloresAún no hay calificaciones
- 6to - Cyt - Ficha Método Científico - Semana 5Documento1 página6to - Cyt - Ficha Método Científico - Semana 5Edwing Maquera FloresAún no hay calificaciones
- 6to - Mat - Ficha - Semana 01 - Unidades de MasaDocumento4 páginas6to - Mat - Ficha - Semana 01 - Unidades de MasaEdwing Maquera FloresAún no hay calificaciones
- 6to - Mat - Ficha - Semana 03 - Ecuaciones de Primer GradoDocumento2 páginas6to - Mat - Ficha - Semana 03 - Ecuaciones de Primer GradoEdwing Maquera FloresAún no hay calificaciones
- 6to Cyt Ficha Método Científico Semana 5Documento1 página6to Cyt Ficha Método Científico Semana 5Edwing Maquera FloresAún no hay calificaciones
- 6TO CYT FICHA Cambios de Estado Ficha ABPDocumento1 página6TO CYT FICHA Cambios de Estado Ficha ABPEdwing Maquera FloresAún no hay calificaciones
- 6to - Cyt - Ficha para Album - Semana N°2Documento2 páginas6to - Cyt - Ficha para Album - Semana N°2Edwing Maquera FloresAún no hay calificaciones
- 6TO CYT FICHA Cambios de Estado Ficha ABPDocumento1 página6TO CYT FICHA Cambios de Estado Ficha ABPEdwing Maquera FloresAún no hay calificaciones
- 6to - Mat - Ficha - Semana 06 - Problemas Con Números DecimalesDocumento2 páginas6to - Mat - Ficha - Semana 06 - Problemas Con Números DecimalesEdwing Maquera FloresAún no hay calificaciones
- 6TO CYT FICHA Cambios de Estado Ficha ABPDocumento1 página6TO CYT FICHA Cambios de Estado Ficha ABPEdwing Maquera FloresAún no hay calificaciones
- 6to - Mat - Ficha - Semana 02 - Unidades de LongitudDocumento2 páginas6to - Mat - Ficha - Semana 02 - Unidades de LongitudEdwing Maquera FloresAún no hay calificaciones
- 6to Mat Ficha Semana 01 PorcentajesDocumento2 páginas6to Mat Ficha Semana 01 PorcentajesEdwing Maquera FloresAún no hay calificaciones
- 6to - Mat - Ficha 5 - Semana 5 - Paev Con Números Decimales (Taller Abp)Documento3 páginas6to - Mat - Ficha 5 - Semana 5 - Paev Con Números Decimales (Taller Abp)Edwing Maquera FloresAún no hay calificaciones
- 6TO - MAT - FICHA 4 - SEMANA 04 - Traslación de Figuras en El Plano CartesianoDocumento2 páginas6TO - MAT - FICHA 4 - SEMANA 04 - Traslación de Figuras en El Plano CartesianoEdwing Maquera FloresAún no hay calificaciones
- 6to - Mat - Ficha 5 - Semana 5 - Paev Con Números Decimales (Taller Abp)Documento3 páginas6to - Mat - Ficha 5 - Semana 5 - Paev Con Números Decimales (Taller Abp)Edwing Maquera FloresAún no hay calificaciones
- La Educación para El Trabajo Como Eje IntegradorDocumento9 páginasLa Educación para El Trabajo Como Eje IntegradorDubraska VillarruelAún no hay calificaciones
- El Poder de Los HábitosDocumento1 páginaEl Poder de Los Hábitosazukur2000Aún no hay calificaciones
- Guía de Actividades y Rúbrica de Evaluación - Fase 1 - Reconocimiento Del CursoDocumento7 páginasGuía de Actividades y Rúbrica de Evaluación - Fase 1 - Reconocimiento Del CursoAnonymous DBpmunh9Aún no hay calificaciones
- AQ10. Compatibilidad Fungicidas. Rev. Enero 2020Documento2 páginasAQ10. Compatibilidad Fungicidas. Rev. Enero 2020Marisa PradaAún no hay calificaciones
- Gramática I - Clases de Palabras. Marin MartaDocumento30 páginasGramática I - Clases de Palabras. Marin MartaAyelén SchereiberAún no hay calificaciones
- Revista Juridica2012 CompletoDocumento474 páginasRevista Juridica2012 Completodes_troyer100% (1)
- Anemia FerropénicaDocumento9 páginasAnemia FerropénicaPaola SophiaAún no hay calificaciones
- Trabajo Grupal CineticaDocumento15 páginasTrabajo Grupal CineticaSAMUEL OTOYA LAVADOAún no hay calificaciones
- El Gran Chasco Los Guiaba Dios Aun Estando EquivocadosDocumento29 páginasEl Gran Chasco Los Guiaba Dios Aun Estando EquivocadosElizabeth CamposAún no hay calificaciones
- Plan de vigilancia y prevención COVID-19Documento29 páginasPlan de vigilancia y prevención COVID-19Lucas Delgado BravoAún no hay calificaciones
- Vartini Packing Final PDFDocumento27 páginasVartini Packing Final PDFJhonese CastañedaAún no hay calificaciones
- Onu Mujeres Ante La Sentencia Sobre El Caso Maria Isabel Veliz Franco 4agDocumento2 páginasOnu Mujeres Ante La Sentencia Sobre El Caso Maria Isabel Veliz Franco 4agAnonymous 5vYKrumAún no hay calificaciones
- Lenguaje Jurídico Claro (ED)Documento8 páginasLenguaje Jurídico Claro (ED)Mora spotornoAún no hay calificaciones
- Acta de Bautizo de Vicente Guerrero e IturbideDocumento11 páginasActa de Bautizo de Vicente Guerrero e IturbideEmiliano GarciaAún no hay calificaciones
- Marifre Tarea FinalDocumento22 páginasMarifre Tarea FinalBlanca Milagros Garcia NoboaAún no hay calificaciones
- Separata Cap, 1, 2 y 3 EnfoquesenterapiafamiliarsistémicaDocumento16 páginasSeparata Cap, 1, 2 y 3 EnfoquesenterapiafamiliarsistémicaAntarel. abAún no hay calificaciones
- Crisis, Mapa ConceptualDocumento1 páginaCrisis, Mapa ConceptualJaviercito Remigio100% (1)
- Ruta de La Santidad Venezolana 2022-Sección Caracas PDFDocumento4 páginasRuta de La Santidad Venezolana 2022-Sección Caracas PDFileaneAún no hay calificaciones
- Guìa de Ejercicios de Diagramas de ParetoDocumento1 páginaGuìa de Ejercicios de Diagramas de ParetoOrquidea E. TejedaAún no hay calificaciones
- La EntrevistaDocumento2 páginasLa EntrevistaJoseNovero0% (1)
- 1 Práctica CalificadaDocumento4 páginas1 Práctica CalificadaMartha Jose Josec100% (1)
- Cuadro Comparativo Karen Torres SocarrasDocumento3 páginasCuadro Comparativo Karen Torres Socarraseverto gomezAún no hay calificaciones
- Profecia para Los Espiritus de NorteamericaDocumento3 páginasProfecia para Los Espiritus de NorteamericaIván IllanesAún no hay calificaciones
- Crear y Conjurar La Crisis de La CiudadDocumento2 páginasCrear y Conjurar La Crisis de La CiudadAngela GarciaAún no hay calificaciones
- Hampshire Down: Luis Fernando Rodriguez Lopez Juan Aníbal AndinoDocumento8 páginasHampshire Down: Luis Fernando Rodriguez Lopez Juan Aníbal AndinoJuanAún no hay calificaciones
- Tesis 1 Cuestionario de Tarea 1.3Documento3 páginasTesis 1 Cuestionario de Tarea 1.3GONZALO RAFAEL MOYA VILLANUEVAAún no hay calificaciones
- AbrahamMateo MellowYellowDocumento5 páginasAbrahamMateo MellowYellowhonnhiAún no hay calificaciones
- 52 - Grado - 33 - Sob - Ins - GeneralDocumento6 páginas52 - Grado - 33 - Sob - Ins - GeneralGran Logia Tamaulipas SoporteAún no hay calificaciones
- Actividad 5 Imaginacion Sociologica y PrejuiciosDocumento1 páginaActividad 5 Imaginacion Sociologica y PrejuiciosdAún no hay calificaciones
- Diagnóstico Ingles 5ºDocumento5 páginasDiagnóstico Ingles 5ºPatricia GomezAún no hay calificaciones