También podría gustarte
- XML: An Introduction to Extensible Markup LanguageDocumento19 páginasXML: An Introduction to Extensible Markup LanguageHarsha VardhanAún no hay calificaciones
- Basic XML What Is XML?Documento25 páginasBasic XML What Is XML?Dijong KapukAún no hay calificaciones
- XML IntroDocumento30 páginasXML IntroKaushik SivashankarAún no hay calificaciones
- Silibus CSC134Documento5 páginasSilibus CSC134maggieAún no hay calificaciones
- Create class timetable HTMLDocumento40 páginasCreate class timetable HTMLmanichennaiAún no hay calificaciones
- The CSS Box ModelDocumento4 páginasThe CSS Box ModelRicardo B. ViganAún no hay calificaciones
- XML Lab RecordDocumento63 páginasXML Lab RecordjesudosssAún no hay calificaciones
- DTD Tutorial2Documento14 páginasDTD Tutorial2Subhasis MishraAún no hay calificaciones
- Architectural Design in Software EngineeringDocumento10 páginasArchitectural Design in Software EngineeringAmudha ShanmugamAún no hay calificaciones
- Lesson 1 - Introduction To System IntegrationDocumento27 páginasLesson 1 - Introduction To System Integrationmark daniel beatoAún no hay calificaciones
- XML Assignment 1 Fall 2021Documento3 páginasXML Assignment 1 Fall 2021Hiếu NguyễnAún no hay calificaciones
- Lecture 1 - Intelligent AgentDocumento11 páginasLecture 1 - Intelligent AgentBilal ShahidAún no hay calificaciones
- Basics of CSS and Some Common MistakesDocumento51 páginasBasics of CSS and Some Common MistakesEinjhel BorresAún no hay calificaciones
- Cascading Style Sheets (CSS)Documento79 páginasCascading Style Sheets (CSS)Khush KhandelwalAún no hay calificaciones
- CSS IntroductionDocumento17 páginasCSS IntroductionJoel MemitaAún no hay calificaciones
- Technologies Every Web Developer Should Be Able To ExplainDocumento4 páginasTechnologies Every Web Developer Should Be Able To ExplainPromikaAún no hay calificaciones
- Basic HTMLDocumento12 páginasBasic HTMLJOLITO RAMOSAún no hay calificaciones
- Database Management System ExplainedDocumento6 páginasDatabase Management System ExplainedAnil ShresthaAún no hay calificaciones
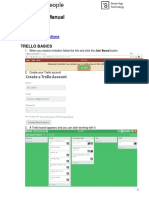
- Brief Trello ManualDocumento10 páginasBrief Trello Manualmunir85Aún no hay calificaciones
- HTML Form Elements PDFDocumento11 páginasHTML Form Elements PDFAlex OrozcoAún no hay calificaciones
- Hospital Management SystemDocumento128 páginasHospital Management SystemKhaled SalehAún no hay calificaciones
- Smart College Campus Using IoTDocumento7 páginasSmart College Campus Using IoTsri harshaphaniAún no hay calificaciones
- Object-Oriented Databases: Need for Complex Data TypesDocumento21 páginasObject-Oriented Databases: Need for Complex Data Typesraazoo19Aún no hay calificaciones
- Software Requirements DocumentDocumento17 páginasSoftware Requirements Documentgim688Aún no hay calificaciones
- O? O? O? O? O? O? O? O? O? O?Documento18 páginasO? O? O? O? O? O? O? O? O? O?jaa_neeAún no hay calificaciones
- Module 6 - Introduction To Hypertext PreprocessorDocumento19 páginasModule 6 - Introduction To Hypertext PreprocessorMr. EpiphanyAún no hay calificaciones
- 2-3 Tier ArchitectureDocumento4 páginas2-3 Tier ArchitectureRamya Selvaraj100% (1)
- CHAPTER 3 Data Representation and Computer ArithmeticDocumento12 páginasCHAPTER 3 Data Representation and Computer ArithmeticKinfe BeregaAún no hay calificaciones
- Fundamentals of Computer: Prof. Jhalak DuttaDocumento55 páginasFundamentals of Computer: Prof. Jhalak DuttaJhalak DuttaAún no hay calificaciones
- 02 HTMLDocumento73 páginas02 HTMLMi Amas VinAún no hay calificaciones
- Introduction To HTMLDocumento23 páginasIntroduction To HTMLAnonymous ij5Eu0Aún no hay calificaciones
- Web Development Course With PHPDocumento15 páginasWeb Development Course With PHPChetan KelkarAún no hay calificaciones
- The Elements of Event Driven ProgramsDocumento3 páginasThe Elements of Event Driven ProgramsTeklit BerihuAún no hay calificaciones
- Unit 3 - Internet of Things - WWW - Rgpvnotes.inDocumento15 páginasUnit 3 - Internet of Things - WWW - Rgpvnotes.inAftab MansuriAún no hay calificaciones
- Reference: Software Engineering, by Ian Sommerville, 9 Edition, Chapter 2Documento16 páginasReference: Software Engineering, by Ian Sommerville, 9 Edition, Chapter 2Ibrahim OiraAún no hay calificaciones
- App Inventor Day 1 PDFDocumento35 páginasApp Inventor Day 1 PDFWalid SassiAún no hay calificaciones
- Mini Project WTDocumento10 páginasMini Project WTDEEPIKAAún no hay calificaciones
- XML Lab Assignments SchemaDocumento24 páginasXML Lab Assignments SchemaNeha MagarAún no hay calificaciones
- Rungta College of Engineering & Technology: Lab Manual CS-322364 (22) : Web TechnologyDocumento58 páginasRungta College of Engineering & Technology: Lab Manual CS-322364 (22) : Web TechnologybinzbinzAún no hay calificaciones
- VTU 8th Sem Cse QB With AnswersDocumento137 páginasVTU 8th Sem Cse QB With Answersvmscse100% (1)
- HTML ProjDocumento14 páginasHTML ProjDanikey SantosAún no hay calificaciones
- Relational Model Concepts ExplainedDocumento5 páginasRelational Model Concepts ExplainedAbhinandan BhatAún no hay calificaciones
- Chapter 9 Transactions Management and Concurrency ControlDocumento36 páginasChapter 9 Transactions Management and Concurrency ControlJiawei TanAún no hay calificaciones
- 2082 - Unit 4 Notes WT (BCA 204)Documento26 páginas2082 - Unit 4 Notes WT (BCA 204)DhananjayKumarAún no hay calificaciones
- Edge analytics core functions and componentsDocumento13 páginasEdge analytics core functions and componentssarakeAún no hay calificaciones
- Distributed DatabaseDocumento49 páginasDistributed DatabaseSatheswaran RajasegaranAún no hay calificaciones
- Client Server ArchitectureDocumento13 páginasClient Server ArchitectureGauri Bachani100% (1)
- Conquer Forms With HTML5 and CSS3Documento96 páginasConquer Forms With HTML5 and CSS3vaishali khairnarAún no hay calificaciones
- HTTP OverviewDocumento14 páginasHTTP OverviewMac GarrAún no hay calificaciones
- System Integration and Architecture - P2Documento24 páginasSystem Integration and Architecture - P2percival fernandezAún no hay calificaciones
- About The Classification and Regression Supervised Learning ProblemsDocumento3 páginasAbout The Classification and Regression Supervised Learning ProblemssaileshmnsAún no hay calificaciones
- Web Programming: Unit 1: Introduction To Dynamic WebsitesDocumento15 páginasWeb Programming: Unit 1: Introduction To Dynamic WebsitesIwan SaputraAún no hay calificaciones
- Introducing the AWTDocumento65 páginasIntroducing the AWTDaniel JoshuaAún no hay calificaciones
- DBMS Report PDFDocumento15 páginasDBMS Report PDFBeast0% (1)
- Fill in TH Blanks - WebApp-XII-2022-Web Scripting - JavaScript-YKDocumento7 páginasFill in TH Blanks - WebApp-XII-2022-Web Scripting - JavaScript-YKRiya DuttAún no hay calificaciones
- Basics of C++ (Lecture 4)Documento32 páginasBasics of C++ (Lecture 4)Inoxent Shezadi100% (1)
- Introcss - ppt.02.01 Box ModelDocumento18 páginasIntrocss - ppt.02.01 Box ModelLuis SorianoAún no hay calificaciones
- Information Management-1-25 PDFDocumento25 páginasInformation Management-1-25 PDFKiruthika Veerappan NagappanAún no hay calificaciones
- IT2357 - Web Technology Lab - XMLDocumento10 páginasIT2357 - Web Technology Lab - XMLbhuvangatesAún no hay calificaciones
- Software Reliability A Complete Guide - 2020 EditionDe EverandSoftware Reliability A Complete Guide - 2020 EditionAún no hay calificaciones
- Dotnet WebServicesDocumento104 páginasDotnet WebServicesHarishAún no hay calificaciones
- Assembly: Where It All Gets PhysicalDocumento34 páginasAssembly: Where It All Gets PhysicalHarish100% (1)
- MethodologyDocumento8 páginasMethodologyHarishAún no hay calificaciones
- GUI Event Handling JavaDocumento39 páginasGUI Event Handling JavaHarish100% (1)
- 4 0Documento45 páginas4 0HarishAún no hay calificaciones
- Introducing The ABCs of WCF AZNETDocumento28 páginasIntroducing The ABCs of WCF AZNETAhmed SharifAún no hay calificaciones
- Introducing NET Framework 35 v1Documento31 páginasIntroducing NET Framework 35 v1janhjordieAún no hay calificaciones
- SOAP - Intro 2 WebservicesDocumento26 páginasSOAP - Intro 2 WebservicesHarish100% (1)
- Agile MethodologiesDocumento33 páginasAgile MethodologiesHarishAún no hay calificaciones
- MVCDocumento11 páginasMVCHarish100% (1)
- C# 3.0 N LinqDocumento58 páginasC# 3.0 N LinqHarishAún no hay calificaciones
- Remote Method Invocation JavaDocumento118 páginasRemote Method Invocation JavaHarishAún no hay calificaciones
- Oracle RDBMS & SQL Tutorial (Very Good)Documento66 páginasOracle RDBMS & SQL Tutorial (Very Good)api-3717772100% (7)
- DatareaderDocumento36 páginasDatareaderHarishAún no hay calificaciones
- Overview of Dotnet Framework 4.0Documento9 páginasOverview of Dotnet Framework 4.0HarishAún no hay calificaciones
- Cheat Sheet - ASPNET BasicsDocumento2 páginasCheat Sheet - ASPNET BasicsMk Dela FuenteAún no hay calificaciones
- Stored ProceduresDocumento32 páginasStored ProceduresHarishAún no hay calificaciones
- C# For C++ ProgrammersDocumento73 páginasC# For C++ ProgrammersHarish100% (1)
- JDBC BasicsDocumento59 páginasJDBC BasicsHarishAún no hay calificaciones
- Dotnet 3.0 OverviewDocumento52 páginasDotnet 3.0 OverviewHarishAún no hay calificaciones
- WCFDocumento94 páginasWCFapi-3845693100% (1)
- Microsoft: Joseph J. Sarna Jr. JJS Systems, LLCDocumento25 páginasMicrosoft: Joseph J. Sarna Jr. JJS Systems, LLCHarishAún no hay calificaciones
- Dotnet FrameworkDocumento60 páginasDotnet FrameworkHarishAún no hay calificaciones
- Javafx Rich Internet Applications With Restful Web Services, Jersey Api and JsonDocumento26 páginasJavafx Rich Internet Applications With Restful Web Services, Jersey Api and JsonHarish100% (1)
- WCF FoundationDocumento36 páginasWCF FoundationHarish100% (1)
- Javascript Cheat SheetDocumento1 páginaJavascript Cheat Sheetdanielle leigh100% (4)
- Core ASP Net Reference SheetDocumento6 páginasCore ASP Net Reference SheetHarishAún no hay calificaciones
- Great Lateral Thinking PuzzlesDocumento49 páginasGreat Lateral Thinking PuzzlesHarish100% (3)
- ORACLE Server 8i Quick Reference CardDocumento6 páginasORACLE Server 8i Quick Reference Cardapi-19933407Aún no hay calificaciones
- Design and Simulation of Wireless Local Area Network For Administrative Office Using OPNET Network Simulator: A Practical ApproachDocumento8 páginasDesign and Simulation of Wireless Local Area Network For Administrative Office Using OPNET Network Simulator: A Practical Approachzerihun demereAún no hay calificaciones
- Prepaway - GCP Professional Cloud ArchitectDocumento91 páginasPrepaway - GCP Professional Cloud Architectmatt stream100% (1)
- AJP (22517) Unit Test 2 CMIF5I 2022-23Documento4 páginasAJP (22517) Unit Test 2 CMIF5I 2022-23Dhaval SarodeAún no hay calificaciones
- Linux Interview Questions AnswersDocumento80 páginasLinux Interview Questions AnswersMishraa_jiAún no hay calificaciones
- ONLINE CRIME MANAGEMENT SYSTEMDocumento18 páginasONLINE CRIME MANAGEMENT SYSTEMShalabh Nigam100% (1)
- Nota VCD Dan DVDDocumento8 páginasNota VCD Dan DVDMimi Syuryani Binti NodinAún no hay calificaciones
- Oxe12.1 SD Maintenance 8AL91011USAG 1 enDocumento235 páginasOxe12.1 SD Maintenance 8AL91011USAG 1 enTamai Aisea AniseAún no hay calificaciones
- JS Essentials Cheat Sheets-1Documento53 páginasJS Essentials Cheat Sheets-1craviteja9Aún no hay calificaciones
- Introduction To Software Reverse Engineering With Ghidra Session 2: C To ASMDocumento49 páginasIntroduction To Software Reverse Engineering With Ghidra Session 2: C To ASMChancemille RemoAún no hay calificaciones
- IT BE Project Presentation-2022-23 JSLDocumento28 páginasIT BE Project Presentation-2022-23 JSLTanmay DoshiAún no hay calificaciones
- Calculating The Fibonacci Number With PHP and HTMLDocumento3 páginasCalculating The Fibonacci Number With PHP and HTMLJake DiMareAún no hay calificaciones
- Shiratech Fpga-MezzaninewebDocumento1 páginaShiratech Fpga-MezzaninewebaaaaAún no hay calificaciones
- P-Delta Analysis ParametersDocumento1 páginaP-Delta Analysis Parametersmathewsujith31Aún no hay calificaciones
- Chapter 3 - SelectionDocumento18 páginasChapter 3 - SelectionAyoub fgdAún no hay calificaciones
- Vodafone MachineLink 3G Firmware Upgrade GuideDocumento8 páginasVodafone MachineLink 3G Firmware Upgrade GuidejaimebravomendozaAún no hay calificaciones
- Technical Data Mobile C-Arm (New Release Dec 2010Documento21 páginasTechnical Data Mobile C-Arm (New Release Dec 2010Ibrahim BRAHIMIAún no hay calificaciones
- JMR 7230 S 3Documento102 páginasJMR 7230 S 3宋翔Aún no hay calificaciones
- COMPAL LA 3301P IBQ00 REV 1.0 (ComunidadeTecnica - Com.br)Documento59 páginasCOMPAL LA 3301P IBQ00 REV 1.0 (ComunidadeTecnica - Com.br)Carlos Tome De SousaAún no hay calificaciones
- Free Indesign Resume Template 2020Documento4 páginasFree Indesign Resume Template 2020gvoimsvcf100% (2)
- Tracking students across WADocumento9 páginasTracking students across WARichel CrowelAún no hay calificaciones
- 5G Boon or BaneDocumento7 páginas5G Boon or BaneManas DwivediAún no hay calificaciones
- mSIM call log analysisDocumento5 páginasmSIM call log analysisNoris RiswandaAún no hay calificaciones
- Harmony 21 Advanced Getting Started GuideDocumento206 páginasHarmony 21 Advanced Getting Started GuideSaul InvictusAún no hay calificaciones
- GATE 2020 COMPUTER SCIENCE & IT SOLUTIONSDocumento43 páginasGATE 2020 COMPUTER SCIENCE & IT SOLUTIONSIshan JawaAún no hay calificaciones
- ProfiNet Tag Generator V2 - DM200Documento49 páginasProfiNet Tag Generator V2 - DM200Paula Carolina Coppe ValleAún no hay calificaciones
- RSA Archer 6.3 Platform User's GuideDocumento128 páginasRSA Archer 6.3 Platform User's GuideCardano walletAún no hay calificaciones
- Telephoning: Business English Lesson 3Documento9 páginasTelephoning: Business English Lesson 3Embut PangestuAún no hay calificaciones
- Oracle® Fusion MiddlewareDocumento132 páginasOracle® Fusion MiddlewareRahul RoyAún no hay calificaciones
- CCNA 2 (v5.0.3 + v6.0) Chapter 3 Exam Answers 2019 - 100% FullDocumento24 páginasCCNA 2 (v5.0.3 + v6.0) Chapter 3 Exam Answers 2019 - 100% Fullreem goAún no hay calificaciones
- Lesson 3 - Word ProcessingDocumento17 páginasLesson 3 - Word ProcessingCharen ReposposaAún no hay calificaciones