También podría gustarte
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Calificación: 4.5 de 5 estrellas4.5/5 (121)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryCalificación: 3.5 de 5 estrellas3.5/5 (231)
- Grit: The Power of Passion and PerseveranceDe EverandGrit: The Power of Passion and PerseveranceCalificación: 4 de 5 estrellas4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaCalificación: 4.5 de 5 estrellas4.5/5 (266)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe EverandNever Split the Difference: Negotiating As If Your Life Depended On ItCalificación: 4.5 de 5 estrellas4.5/5 (838)
- The Emperor of All Maladies: A Biography of CancerDe EverandThe Emperor of All Maladies: A Biography of CancerCalificación: 4.5 de 5 estrellas4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe EverandThe Little Book of Hygge: Danish Secrets to Happy LivingCalificación: 3.5 de 5 estrellas3.5/5 (400)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeCalificación: 4 de 5 estrellas4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyCalificación: 3.5 de 5 estrellas3.5/5 (2259)
- Shoe Dog: A Memoir by the Creator of NikeDe EverandShoe Dog: A Memoir by the Creator of NikeCalificación: 4.5 de 5 estrellas4.5/5 (537)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreCalificación: 4 de 5 estrellas4/5 (1090)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersCalificación: 4.5 de 5 estrellas4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe EverandTeam of Rivals: The Political Genius of Abraham LincolnCalificación: 4.5 de 5 estrellas4.5/5 (234)
- Her Body and Other Parties: StoriesDe EverandHer Body and Other Parties: StoriesCalificación: 4 de 5 estrellas4/5 (821)
- The Perks of Being a WallflowerDe EverandThe Perks of Being a WallflowerCalificación: 4.5 de 5 estrellas4.5/5 (2102)
- Rise of ISIS: A Threat We Can't IgnoreDe EverandRise of ISIS: A Threat We Can't IgnoreCalificación: 3.5 de 5 estrellas3.5/5 (137)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceCalificación: 4 de 5 estrellas4/5 (895)
- The Unwinding: An Inner History of the New AmericaDe EverandThe Unwinding: An Inner History of the New AmericaCalificación: 4 de 5 estrellas4/5 (45)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureCalificación: 4.5 de 5 estrellas4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealDe EverandOn Fire: The (Burning) Case for a Green New DealCalificación: 4 de 5 estrellas4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)De EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Calificación: 4 de 5 estrellas4/5 (98)
- Wireshark User GuideDocumento233 páginasWireshark User GuideSergeant HeidirAún no hay calificaciones
- E 10 ACC0Documento99 páginasE 10 ACC0Andrew DowsetAún no hay calificaciones
- Google Cloud Platform TutorialDocumento51 páginasGoogle Cloud Platform Tutorialpavan varma100% (2)
- HOWTO Using Openvpn To Bridge NetworksDocumento10 páginasHOWTO Using Openvpn To Bridge NetworksNghia NguyenAún no hay calificaciones
- How To Configure QoS On The Riverbed SD-WAN Solution - TechRepublicDocumento12 páginasHow To Configure QoS On The Riverbed SD-WAN Solution - TechRepublicDiego ColchaAún no hay calificaciones
- PIC12F1571Documento334 páginasPIC12F1571Anonymous 3GwpCKAún no hay calificaciones
- Delhi Public School Delhi Public School Delhi Public School Delhi Public SchoolDocumento2 páginasDelhi Public School Delhi Public School Delhi Public School Delhi Public Schoolrogo2577Aún no hay calificaciones
- Tutorial Routing 4 RouterDocumento5 páginasTutorial Routing 4 RouterIlhamAún no hay calificaciones
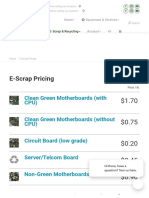
- List E-Waste PriceDocumento4 páginasList E-Waste PriceArianna ContrerasAún no hay calificaciones
- IT Expert - Tweak Utorrent Setting To Increase Torrent Download SpeedDocumento6 páginasIT Expert - Tweak Utorrent Setting To Increase Torrent Download SpeedFrank GimmeAún no hay calificaciones
- Activity No 8 AttributesDocumento6 páginasActivity No 8 Attributesalex sandersAún no hay calificaciones
- Samsung m2070 FW Printer Diagnostics - Buscar Con GoogleDocumento2 páginasSamsung m2070 FW Printer Diagnostics - Buscar Con GoogleDavid LamillaAún no hay calificaciones
- M03 - Install and Manage Network ProtocolsDocumento50 páginasM03 - Install and Manage Network ProtocolsAlazar walle100% (1)
- Domain Controller Critical ServicesDocumento14 páginasDomain Controller Critical ServicessabtriadyAún no hay calificaciones
- KofaxEquitracClientSetupGuide612 EN SecurityFrameworkDocumento35 páginasKofaxEquitracClientSetupGuide612 EN SecurityFrameworkjoniting8Aún no hay calificaciones
- Levels of Computer LanguagesDocumento2 páginasLevels of Computer LanguagesDalitsoAún no hay calificaciones
- Konica Firmware Update InstructionDocumento8 páginasKonica Firmware Update InstructionDean StaceyAún no hay calificaciones
- 98-366 Test Bank Lesson - 01Documento6 páginas98-366 Test Bank Lesson - 01klarascom100% (1)
- Cpus: Latency Oriented DesignDocumento2 páginasCpus: Latency Oriented DesignShaha MubarakAún no hay calificaciones
- Nexus 7000 NX-OS CLI Primer 5.xDocumento186 páginasNexus 7000 NX-OS CLI Primer 5.xroland duboisAún no hay calificaciones
- Alcasar 3.5.4 Installation enDocumento12 páginasAlcasar 3.5.4 Installation enmedit_99Aún no hay calificaciones
- T1-1-Pham Duc Phong-VMware - Establish Your Software-Defined Data CenterDocumento41 páginasT1-1-Pham Duc Phong-VMware - Establish Your Software-Defined Data Centerlongnguyen2512Aún no hay calificaciones
- Parallel Port Control With Delphi - Parallel Port, Delphi, LPTPort, Device DriverDocumento8 páginasParallel Port Control With Delphi - Parallel Port, Delphi, LPTPort, Device DriverRhadsAún no hay calificaciones
- Symantec™ Messaging Gateway 10.7 Installation Guide: Powered by Brightmail™Documento73 páginasSymantec™ Messaging Gateway 10.7 Installation Guide: Powered by Brightmail™tesyouAún no hay calificaciones
- Computer NetworksDocumento12 páginasComputer NetworksOSCAR AHINAMPONGAún no hay calificaciones
- Embedded SyetemDocumento11 páginasEmbedded SyetemDeepak SharmaAún no hay calificaciones
- Oracle Goldengate 12c Fundamentals For OracleDocumento5 páginasOracle Goldengate 12c Fundamentals For OracleqaleeqAún no hay calificaciones
- AcerDocumento4 páginasAcerMrLaptop MYAún no hay calificaciones
- NomadFactory 80s-Spaces ManualDocumento13 páginasNomadFactory 80s-Spaces ManualJJSAún no hay calificaciones