También podría gustarte
- TBD Comandos SQL OracleDocumento12 páginasTBD Comandos SQL OracleVictor CortesAún no hay calificaciones
- SQL DDLDocumento25 páginasSQL DDLBelem MezaAún no hay calificaciones
- Apuntes GTB - Primer TrimestreDocumento6 páginasApuntes GTB - Primer TrimestreLauraRodriguezSabaterAún no hay calificaciones
- SQLDocumento8 páginasSQLluiscoronaAún no hay calificaciones
- Comandos de OracleDocumento10 páginasComandos de OracleStefania OrozcoAún no hay calificaciones
- Practica 8 de BDDocumento8 páginasPractica 8 de BDashly ramosAún no hay calificaciones
- Comandos y Sintaxis SQLDocumento13 páginasComandos y Sintaxis SQLCristopher ZamoraAún no hay calificaciones
- Apuntes Del Chat Con Filtro JuanmaDocumento9 páginasApuntes Del Chat Con Filtro JuanmaAngel CopadoAún no hay calificaciones
- Practivas IDocumento8 páginasPractivas Ipingaloca2Aún no hay calificaciones
- Creación de TablasDocumento9 páginasCreación de TablasAlexis FloresAún no hay calificaciones
- Comandos SQL BásicosDocumento6 páginasComandos SQL BásicosOSCAR RODRIGUEZAún no hay calificaciones
- Manual de Comandos ORACLE 10GDocumento17 páginasManual de Comandos ORACLE 10GDavid Santillán RamosAún no hay calificaciones
- Creand Base de Datos - TablaDocumento80 páginasCreand Base de Datos - TablaMaravi APAún no hay calificaciones
- SQLDocumento9 páginasSQLJuan BromasAún no hay calificaciones
- Comandos Consultas SQL ServerDocumento32 páginasComandos Consultas SQL ServermiguelAún no hay calificaciones
- Teoria Creacion Supresion Modificacion de TablasDocumento6 páginasTeoria Creacion Supresion Modificacion de TablasM. Angeles Parr INF.Aún no hay calificaciones
- BD Estudiantes MiercolesDocumento19 páginasBD Estudiantes MiercolesJose RamonAún no hay calificaciones
- JOIN OracleDocumento17 páginasJOIN OracleAlexis FloresAún no hay calificaciones
- PDF Ut6Documento17 páginasPDF Ut6AlvaroAún no hay calificaciones
- Apuntes SQLDocumento15 páginasApuntes SQLzl SistemasAún no hay calificaciones
- Tablas Temporales en SQL ServerDocumento4 páginasTablas Temporales en SQL ServerJosé Pedro PascualAún no hay calificaciones
- SQL ServerDocumento7 páginasSQL ServerCristhian JoelAún no hay calificaciones
- Supertipos y Subtipos en SQL Server 2008Documento25 páginasSupertipos y Subtipos en SQL Server 2008Geovanny CudcoAún no hay calificaciones
- SQL DDLDocumento25 páginasSQL DDLAlex Poma PancayaAún no hay calificaciones
- Consultas SQL básicasDocumento10 páginasConsultas SQL básicasKaren Huerta mendozaAún no hay calificaciones
- 06 SQLDocumento15 páginas06 SQLJackson Osterling Aguilar PasionAún no hay calificaciones
- FORMULARIODocumento4 páginasFORMULARIOKrly EspinozaAún no hay calificaciones
- SelectDocumento7 páginasSelectAnonymous ufXa159Aún no hay calificaciones
- SQL CREATE, INSERT, UPDATE, DELETE y SELECTDocumento6 páginasSQL CREATE, INSERT, UPDATE, DELETE y SELECTFelipe Hdez GalvanAún no hay calificaciones
- Comandos SQL BásicosDocumento7 páginasComandos SQL BásicosLuz Eliana Martinez RamosAún no hay calificaciones
- SQLDocumento123 páginasSQLAlex SaucedoAún no hay calificaciones
- Actividad - 2.5 - Comandos - SQLDocumento23 páginasActividad - 2.5 - Comandos - SQLLesly TorresAún no hay calificaciones
- Lenguaje SQL Server TeoriaDocumento6 páginasLenguaje SQL Server TeoriaKevin Cruzado CaveroAún no hay calificaciones
- Sesion 01Documento110 páginasSesion 01MINION BBMAún no hay calificaciones
- Alter ProcedureDocumento11 páginasAlter ProcedureLight17Aún no hay calificaciones
- APEXDocumento17 páginasAPEXOsiris FernandezAún no hay calificaciones
- Migracion de DatosDocumento6 páginasMigracion de DatosCamila GonzalezAún no hay calificaciones
- Guía BDDocumento11 páginasGuía BDRaúl MuroAún no hay calificaciones
- Ejercicio Sentencias SQLDocumento13 páginasEjercicio Sentencias SQLRusbel HuamanAún no hay calificaciones
- Comandos SQL BásicosDocumento7 páginasComandos SQL BásicosLuz Eliana Martinez RamosAún no hay calificaciones
- Aprendiendo SQL Con PostgresqlDocumento8 páginasAprendiendo SQL Con PostgresqlFabian GutierrezAún no hay calificaciones
- C06 Practicas SQLDocumento7 páginasC06 Practicas SQLMiguel DodiegoAún no hay calificaciones
- Sesión 11 B - Material Complementario MySqlDocumento15 páginasSesión 11 B - Material Complementario MySqlAbel Ortiz CastilloAún no hay calificaciones
- Apuntes Capitulo 2Documento32 páginasApuntes Capitulo 2Shoin DannAún no hay calificaciones
- Chrystal - Comandos Basicos SQLDocumento6 páginasChrystal - Comandos Basicos SQLAlvaro TovarAún no hay calificaciones
- Inatruc en SQL Visual BasicDocumento10 páginasInatruc en SQL Visual BasicBerny HcAún no hay calificaciones
- SQL ALTER TABLEDocumento2 páginasSQL ALTER TABLERafa Iglesias PlaAún no hay calificaciones
- Resumen SQLDocumento10 páginasResumen SQLjosefaAún no hay calificaciones
- Comandos MysqlDocumento45 páginasComandos MysqlAshley Stronghold WitwickyAún no hay calificaciones
- Notas Clase Setencia SQLDocumento8 páginasNotas Clase Setencia SQLCarolina CAún no hay calificaciones
- Crud SQLDocumento15 páginasCrud SQLzl SistemasAún no hay calificaciones
- Pres 12 BDIDocumento28 páginasPres 12 BDISebastian Gongora AnguloAún no hay calificaciones
- Comandos Basicos en SQLDocumento4 páginasComandos Basicos en SQLLina Marcela ChaverraAún no hay calificaciones
- PRACTICA0_01Documento11 páginasPRACTICA0_01RodrigoAún no hay calificaciones
- Procedimientos y Funciones Apuntes de C#Documento22 páginasProcedimientos y Funciones Apuntes de C#maldito92Aún no hay calificaciones
- Clave PrimariaDocumento16 páginasClave PrimariaIsamar Alejandra QueroAún no hay calificaciones
- Apuntes Consultas BD05Documento5 páginasApuntes Consultas BD05Raul FernandezAún no hay calificaciones
- Base de Datos - SintaxisDocumento24 páginasBase de Datos - SintaxismarilinaperAún no hay calificaciones
- Tablas dinámicas para todos. Desde simples tablas hasta Power-Pivot: Guía útil para crear tablas dinámicas en ExcelDe EverandTablas dinámicas para todos. Desde simples tablas hasta Power-Pivot: Guía útil para crear tablas dinámicas en ExcelAún no hay calificaciones
- Tablas dinámicas y Gráficas para Excel: Una guía visual paso a pasoDe EverandTablas dinámicas y Gráficas para Excel: Una guía visual paso a pasoAún no hay calificaciones
- Traducción Álgebra Relacional a SQLDocumento3 páginasTraducción Álgebra Relacional a SQLalvaro Garcia sanchezAún no hay calificaciones
- Ejercicios SQL 1-14Documento21 páginasEjercicios SQL 1-14Jordi CardenasAún no hay calificaciones
- Certificados Calidad 2020 2030Documento5 páginasCertificados Calidad 2020 2030oscarAún no hay calificaciones
- Presupuesto Asesores CalidadDocumento3 páginasPresupuesto Asesores CalidadJorge MonjeAún no hay calificaciones
- Basededatos 2Documento14 páginasBasededatos 2izko villaAún no hay calificaciones
- Caratula Manual Del Sistema de Gestión de La CalidadDocumento1 páginaCaratula Manual Del Sistema de Gestión de La Calidadjose luisAún no hay calificaciones
- PDF Reducer Free reduce documentosDocumento161 páginasPDF Reducer Free reduce documentosSaira Yadira100% (1)
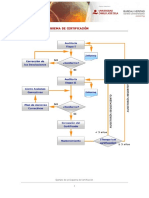
- Esquema de certificación ejemploDocumento1 páginaEsquema de certificación ejemploClaudia Carrizo LeonAún no hay calificaciones
- Esquema Oposita Test Identificadores BibliograficosDocumento1 páginaEsquema Oposita Test Identificadores BibliograficosJuan SánchezAún no hay calificaciones
- Consultas SQL: Cláusulas SELECT, FROM y WHEREDocumento41 páginasConsultas SQL: Cláusulas SELECT, FROM y WHERECarlosSandovalMedinaAún no hay calificaciones
- Tarea Fundamentos de Programacion Donaciones CulminadoDocumento4 páginasTarea Fundamentos de Programacion Donaciones CulminadoDario LlerenaAún no hay calificaciones
- Requerimientos FSSC 22000Documento5 páginasRequerimientos FSSC 22000Eduardiitho MorreyAún no hay calificaciones
- Herramientas Efectivas para El Diseño e Implantación de Un Sistema de Gestión de La Calidad ISO 9000 2000Documento40 páginasHerramientas Efectivas para El Diseño e Implantación de Un Sistema de Gestión de La Calidad ISO 9000 2000Carolina Bohorquez100% (2)
- Tarea II PARCIALDocumento6 páginasTarea II PARCIALSanchez91Aún no hay calificaciones
- Listado Normas Icontec LalibreriadelaUDocumento537 páginasListado Normas Icontec LalibreriadelaUGeison José DÍaz MilánAún no hay calificaciones
- Resultados 2SK35Documento112 páginasResultados 2SK35Pavel Martínez GonzálezAún no hay calificaciones
- Ejercicio Obligatorio - Base de Datos II - Revisión Del IntentoDocumento2 páginasEjercicio Obligatorio - Base de Datos II - Revisión Del IntentoDoly LandAún no hay calificaciones
- Directorio NormasDocumento7 páginasDirectorio NormasSalas AlexAún no hay calificaciones
- Certificacion ISODocumento21 páginasCertificacion ISOThalia Acosta SolanoAún no hay calificaciones
- LibrosSoftwareGratisDocumento705 páginasLibrosSoftwareGratisAlexito ContrerasAún no hay calificaciones
- Conformidad - Ingreso de Nuevos Trabajadores A Roxfarma - Miércoles 15 de Febrero Del 2023Documento2 páginasConformidad - Ingreso de Nuevos Trabajadores A Roxfarma - Miércoles 15 de Febrero Del 2023Kevin Benjamin Bartra CarriónAún no hay calificaciones
- P1 Practico1 PDFDocumento5 páginasP1 Practico1 PDFMateo MonteiroAún no hay calificaciones
- Promociones CertiprofDocumento8 páginasPromociones Certiprofjorge GUILLENAún no hay calificaciones
- FORMA URBANA (Lecturas y Acciones en La Ciudad) de Cesar NacelliDocumento53 páginasFORMA URBANA (Lecturas y Acciones en La Ciudad) de Cesar NacellicoloAún no hay calificaciones
- Este Documento PDF Ha Sido Editado Con Icecream PDF Editor. Actualice A PRO para Eliminar La Marca de AguaDocumento47 páginasEste Documento PDF Ha Sido Editado Con Icecream PDF Editor. Actualice A PRO para Eliminar La Marca de AguaGabrielAún no hay calificaciones
- UntitledDocumento7 páginasUntitledVictor Raul Huertas ApolinarioAún no hay calificaciones
- Norma 17025Documento1 páginaNorma 17025Ana Muñoz NaranjoAún no hay calificaciones
- Reglamento para La Regulacion de Emisiones de Gases Contaminantes y Humo de Los Vehiculos ContaminantesDocumento8 páginasReglamento para La Regulacion de Emisiones de Gases Contaminantes y Humo de Los Vehiculos ContaminantesRuben C. LoboAún no hay calificaciones
- C#Documento4 páginasC#eduardoezequielvigettiAún no hay calificaciones
- Diagrama Sistemas Gestion CalidadDocumento3 páginasDiagrama Sistemas Gestion CalidadCesar HoyosAún no hay calificaciones