También podría gustarte
- Solemne 1 - 1900 - PautaDocumento7 páginasSolemne 1 - 1900 - PautaDiego SepulvedaAún no hay calificaciones
- Relaciones Binarias AuxDocumento39 páginasRelaciones Binarias AuxJackie RosalesAún no hay calificaciones
- Tema 5 - Eco1 - 2021Documento19 páginasTema 5 - Eco1 - 2021Marilena Denisa MicuAún no hay calificaciones
- Contenido Activador Unidad 3 EconometríaDocumento22 páginasContenido Activador Unidad 3 Econometríaalmendra4943Aún no hay calificaciones
- Tarea 1-Regularización L1, L2 y Regresión LogísticaDocumento5 páginasTarea 1-Regularización L1, L2 y Regresión LogísticaDavidAún no hay calificaciones
- Supervised LearningDocumento77 páginasSupervised Learningjamer estradaAún no hay calificaciones
- Programación en Lenguaje Ensamblador (Atmel Studio)Documento64 páginasProgramación en Lenguaje Ensamblador (Atmel Studio)Marco A. Tristan0% (1)
- Adh Anclaje - Matcad - AvanceDocumento16 páginasAdh Anclaje - Matcad - AvanceJoao Jairo Flores VillanuevaAún no hay calificaciones
- Non-Restoring Division Algorithm PabloUribe 1730725Documento12 páginasNon-Restoring Division Algorithm PabloUribe 1730725alison.sarmientoAún no hay calificaciones
- Regresión No Lineal Modelos No LinealízalesDocumento23 páginasRegresión No Lineal Modelos No LinealízalesKEND STEVEN HUAYAN JUAREZAún no hay calificaciones
- Clase5 1Documento13 páginasClase5 1Nicolas AndreAún no hay calificaciones
- Método SimplexDocumento97 páginasMétodo Simplexcelular ownAún no hay calificaciones
- Programación No Lineal Con RestricionesDocumento18 páginasProgramación No Lineal Con RestricionesJuan AristizabalAún no hay calificaciones
- Fernandez Jose t5 Pyoda ADocumento22 páginasFernandez Jose t5 Pyoda AEDUAún no hay calificaciones
- MCP15 Curvas RegularesDocumento16 páginasMCP15 Curvas Regularesariana.lopez.jAún no hay calificaciones
- Formulas Segundo ParcialDocumento6 páginasFormulas Segundo ParcialMaquetas CochabambaAún no hay calificaciones
- E1 CuadripolosDocumento3 páginasE1 CuadripolosJavierAún no hay calificaciones
- Tema4.2 RDocumento4 páginasTema4.2 REva MartinAún no hay calificaciones
- Detección de HeterocedastididadDocumento21 páginasDetección de Heterocedastididadyudel M chAún no hay calificaciones
- Axiomas Cuerpo OrdenDocumento1 páginaAxiomas Cuerpo OrdenRoberto DíazAún no hay calificaciones
- Fernandez Jose T5 Pyoda ADocumento22 páginasFernandez Jose T5 Pyoda AEduardo Fernández CoronadoAún no hay calificaciones
- Modelos Con Un Solo ServidorDocumento2 páginasModelos Con Un Solo ServidorJuan David Lamus ParraAún no hay calificaciones
- ACFrOgDm33u Z48WsuieEKHWB kga7zzDlPpN8UtRtHSXGFqGS6gGjk7PG9hXfD93kcyn6mQZVwFHoGgNSUPR7YpJZfjlB2tXeSGBYJ9IHF-4SlLvMkRQWr95c IhnsDocumento7 páginasACFrOgDm33u Z48WsuieEKHWB kga7zzDlPpN8UtRtHSXGFqGS6gGjk7PG9hXfD93kcyn6mQZVwFHoGgNSUPR7YpJZfjlB2tXeSGBYJ9IHF-4SlLvMkRQWr95c IhnsJackson SandovalAún no hay calificaciones
- Clase3 Optimderivativa Gradiente DescendenteDocumento20 páginasClase3 Optimderivativa Gradiente DescendenteJose BiaforeAún no hay calificaciones
- Form 2 - RespuestasDocumento10 páginasForm 2 - RespuestasMatias BAún no hay calificaciones
- Lineas de InfluenciaDocumento16 páginasLineas de InfluenciaZahid Fernando Ortega AguilarAún no hay calificaciones
- Murrutir Sec1 Pos0Documento8 páginasMurrutir Sec1 Pos0api-3809068100% (1)
- Reresion LinealDocumento30 páginasReresion LinealDario TamayoAún no hay calificaciones
- Tema 2 - TMDocumento15 páginasTema 2 - TMDavid AlejandroAún no hay calificaciones
- REGRESION LINEAL SIMPLE FinalDocumento56 páginasREGRESION LINEAL SIMPLE FinalBAYRONAún no hay calificaciones
- Interpretación de Los Coeficientes PDFDocumento5 páginasInterpretación de Los Coeficientes PDFjuniorAún no hay calificaciones
- Clase Teoría Semana 14Documento32 páginasClase Teoría Semana 14Juan Diego PerezAún no hay calificaciones
- Trigo - Clase4 - UNP - Reducción Al Primer CuadranteDocumento5 páginasTrigo - Clase4 - UNP - Reducción Al Primer CuadranteSandro AlíAún no hay calificaciones
- Ejemplo Resueltos 1Documento26 páginasEjemplo Resueltos 1Julio BarrientosAún no hay calificaciones
- Diseno y Analisis de Experimentos Dougla-232-300Documento69 páginasDiseno y Analisis de Experimentos Dougla-232-300LIZARDO ANDRES GUZMAN CAMARGOAún no hay calificaciones
- 10 - Guias - RegresionDocumento5 páginas10 - Guias - RegresionAnonymous QJeejWbKAún no hay calificaciones
- Muestreo de AceptacionDocumento27 páginasMuestreo de AceptacionjhazAún no hay calificaciones
- Calculo de LimitesDocumento16 páginasCalculo de LimitesYared Tutaya TineoAún no hay calificaciones
- Aplicaciones de Las Cartas de SmithDocumento7 páginasAplicaciones de Las Cartas de SmithAngeles VargasAún no hay calificaciones
- Practica Nro 1 Pronosticos para Los ProyectosDocumento22 páginasPractica Nro 1 Pronosticos para Los ProyectosHugo PinoAún no hay calificaciones
- 8 - Transferencia de Masa Interna 2 - 2021Documento15 páginas8 - Transferencia de Masa Interna 2 - 2021Cecilia FernándezAún no hay calificaciones
- Trabajo VirtualDocumento6 páginasTrabajo VirtualJean Carlos Peña CalleAún no hay calificaciones
- Clase6 Stata ANOVADocumento13 páginasClase6 Stata ANOVAMaria BotasAún no hay calificaciones
- Index 4 Aplicaciones de La DerivadaDocumento33 páginasIndex 4 Aplicaciones de La DerivadaJorge TorresAún no hay calificaciones
- Kriging IDocumento26 páginasKriging ICristian Segura BidermannAún no hay calificaciones
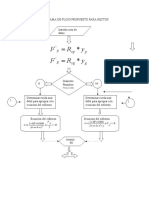
- Diagrama de Flujo RectosDocumento6 páginasDiagrama de Flujo Rectosdaniel calderonAún no hay calificaciones
- 2016 Coeficiente de Correlacion de PearsonDocumento16 páginas2016 Coeficiente de Correlacion de PearsonAlexander GarciaAún no hay calificaciones
- Problemas de Crecimiento Economico en MexicoDocumento2 páginasProblemas de Crecimiento Economico en MexicoCarlos HernandezAún no hay calificaciones
- Criterio de La RaízDocumento9 páginasCriterio de La RaízAlexaAún no hay calificaciones
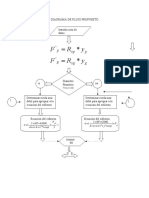
- Diagrama de FlujoDocumento6 páginasDiagrama de Flujodaniel calderonAún no hay calificaciones
- Tutorial Matlab NyquistDocumento5 páginasTutorial Matlab NyquistDavid Elias Flores EscalanteAún no hay calificaciones
- SensibilidadDocumento27 páginasSensibilidadKarenMedínaAún no hay calificaciones
- Taller 5 PDFDocumento4 páginasTaller 5 PDFDaniela MayaAún no hay calificaciones
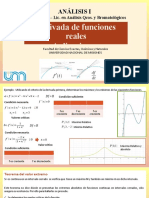
- Derivada de Funciones Reales - Parte V - 2023Documento7 páginasDerivada de Funciones Reales - Parte V - 2023Joaquín BerdiniAún no hay calificaciones
- Estadistica 01Documento11 páginasEstadistica 01Teobaldo Junior Dioses PerezAún no hay calificaciones
- Metodo FUGDocumento19 páginasMetodo FUGsaraAún no hay calificaciones
- Recta Tangentew A Una CircunferenDocumento5 páginasRecta Tangentew A Una CircunferenemersonAún no hay calificaciones
- Introducción Al ÁlgebraDocumento2 páginasIntroducción Al ÁlgebraJuanqui MatCarAún no hay calificaciones
- Taller 2. Polinomios (Parte 1) .Documento2 páginasTaller 2. Polinomios (Parte 1) .Javier LedezmaAún no hay calificaciones
- Introducción Método de JacobiDocumento5 páginasIntroducción Método de JacobiBrenda AvilaAún no hay calificaciones
- Cuadernillo-20210213 091758ev59Documento3 páginasCuadernillo-20210213 091758ev59Elmo Jaime SALAS YAÑEZAún no hay calificaciones
- Tarea 2 - Montoya - MelannyDocumento17 páginasTarea 2 - Montoya - MelannyMelanny Montoya OrtizAún no hay calificaciones
- 76 - Tarea 2Documento116 páginas76 - Tarea 2Yeison RoblesAún no hay calificaciones
- AlgeDocumento1 páginaAlgeAdrian Eduardo Remigio JaraAún no hay calificaciones
- MatemáticasDocumento21 páginasMatemáticasJesús VázquezAún no hay calificaciones
- EXAMEN - 1 - Algebra KattyDocumento11 páginasEXAMEN - 1 - Algebra KattyKATY CORONELAún no hay calificaciones
- Grupo 4 - Taller Nº2 Mssa - Metodos NumericosDocumento9 páginasGrupo 4 - Taller Nº2 Mssa - Metodos NumericosFIORELLA ISABEL DE LA CRUZ CASTILLOAún no hay calificaciones
- 3 Mayo XDocumento9 páginas3 Mayo XMilagros Edith CamargoAún no hay calificaciones
- Interpolación - Trabajo GrupalDocumento3 páginasInterpolación - Trabajo GrupalDavid VeraAún no hay calificaciones
- FACTORIZACIÓNDocumento9 páginasFACTORIZACIÓNUber Antonio Tito FloresAún no hay calificaciones
- Taller: Solución de EcuacionesDocumento16 páginasTaller: Solución de EcuacionesAngie Sánchez BarajasAún no hay calificaciones
- Intento 1 NumericosDocumento5 páginasIntento 1 NumericosSergio Ricardo Figueroa SalcedoAún no hay calificaciones
- Modalidad de Exámenes - Semana 2 - Revisión Del IntentoDocumento3 páginasModalidad de Exámenes - Semana 2 - Revisión Del Intentoluis chuldeAún no hay calificaciones
- FACTORIZACIONDocumento3 páginasFACTORIZACIONYeder VillanuevaAún no hay calificaciones
- Sel 1Documento12 páginasSel 1MarcoLlaveMontañezAún no hay calificaciones
- FMMA010 Ejercicio s11Documento7 páginasFMMA010 Ejercicio s11Paulina Cornejo MezaAún no hay calificaciones
- Ejercicios Del Método de Ruffini para Segundo de SecundariaDocumento8 páginasEjercicios Del Método de Ruffini para Segundo de SecundariaJorge porfirio Pucuhuayla RojasAún no hay calificaciones
- 6.1 Factores, Factor Común Mayor - FCM (GEMA1200)Documento7 páginas6.1 Factores, Factor Común Mayor - FCM (GEMA1200)Rebecca M. Morales AponteAún no hay calificaciones
- Capitulo - II (Raices) Con ExcelDocumento42 páginasCapitulo - II (Raices) Con ExcelDaniel Carlos100% (1)
- Ejercicios de Operaciones Con PolinomiosDocumento6 páginasEjercicios de Operaciones Con PolinomiosCarlos ParraAún no hay calificaciones
- Practica de AlgebraDocumento2 páginasPractica de AlgebraCUSSIAún no hay calificaciones
- Andres Torres - MN - Ejercicio 1Documento13 páginasAndres Torres - MN - Ejercicio 1Marcelo OrtegaAún no hay calificaciones
- Anexo N°7 Expresiones AlgebraicasDocumento3 páginasAnexo N°7 Expresiones AlgebraicasDayani Mora LealAún no hay calificaciones
- Proyecto Final de Investigacion OperativaDocumento4 páginasProyecto Final de Investigacion OperativacristianAún no hay calificaciones
- 4.-Ajuste de Curvas Con Una Combinación Lineal de Funciones ConocidasDocumento4 páginas4.-Ajuste de Curvas Con Una Combinación Lineal de Funciones ConocidasliveAún no hay calificaciones
- Grupo N°3 - Metodos NumericosDocumento581 páginasGrupo N°3 - Metodos NumericosMAYTE CAROLINA CABRERA BERMEOAún no hay calificaciones