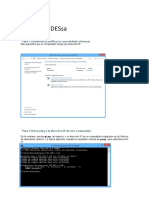
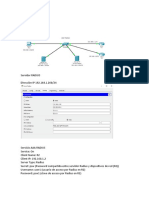
También podría gustarte
- Compilador C CCS y Simulador Proteus para Microcontroladores PICDe EverandCompilador C CCS y Simulador Proteus para Microcontroladores PICCalificación: 2.5 de 5 estrellas2.5/5 (5)
- Control de Versiones de Software con GIT - 2º EdiciónDe EverandControl de Versiones de Software con GIT - 2º EdiciónAún no hay calificaciones
- Actividad Paso 6 Edith GuzmanDocumento34 páginasActividad Paso 6 Edith GuzmanJohanaGuzmanAún no hay calificaciones
- UF0853 - Explotación de las funcionalidades del sistema microinformáticoDe EverandUF0853 - Explotación de las funcionalidades del sistema microinformáticoAún no hay calificaciones
- Entrega 3 Sist - DistribuidosDocumento10 páginasEntrega 3 Sist - DistribuidosSebastián MontealegreAún no hay calificaciones
- UF0852 - Instalación y actualización de sistemas operativosDe EverandUF0852 - Instalación y actualización de sistemas operativosCalificación: 5 de 5 estrellas5/5 (1)
- Piad 215 Formatoalumnotrabajofinal 1Documento14 páginasPiad 215 Formatoalumnotrabajofinal 1POL FFAún no hay calificaciones
- Evidencia de Aprendizaje Semana 4Documento5 páginasEvidencia de Aprendizaje Semana 4valeria calderon50% (4)
- Manual de Manejo y Filtrados de Datos LidarDocumento24 páginasManual de Manejo y Filtrados de Datos LidarRocio CayambeAún no hay calificaciones
- Guia Uso Radio MobileDocumento10 páginasGuia Uso Radio MobileAngelika Vanessa ChambaAún no hay calificaciones
- CCN-STIC-872 Implementación Del ENS en Servidor de Ficheros Sobre Windows Server 2012 R2Documento264 páginasCCN-STIC-872 Implementación Del ENS en Servidor de Ficheros Sobre Windows Server 2012 R2CARLOS ALFREDO GIL BONILLAAún no hay calificaciones
- 8 Modelo WRF I 2014Documento40 páginas8 Modelo WRF I 2014hernymetAún no hay calificaciones
- STD Script Esp PDFDocumento5 páginasSTD Script Esp PDFJhonatanfaim UncpAún no hay calificaciones
- MRTGDocumento7 páginasMRTGinfobitsAún no hay calificaciones
- MRTGDocumento26 páginasMRTGDavid FernandoAún no hay calificaciones
- Investigacion ArquitecturaDocumento4 páginasInvestigacion ArquitecturaBruno MármolAún no hay calificaciones
- Practica MRTGDocumento5 páginasPractica MRTGKmiSzAún no hay calificaciones
- LiggghtsDocumento6 páginasLiggghtsDavid Rivera TapiaAún no hay calificaciones
- Informe MRTGDocumento18 páginasInforme MRTGAntonio Mantilla Galarza100% (1)
- Global Mapper - Referencia Del Lenguaje de Secuencias de ComandosDocumento20 páginasGlobal Mapper - Referencia Del Lenguaje de Secuencias de ComandosPaul Gálvez100% (1)
- Lab Comandos de RedesDocumento14 páginasLab Comandos de RedesALAN ISAAC BERMUDEZ MOLINAAún no hay calificaciones
- Arquitecturas de Computadores 2Documento22 páginasArquitecturas de Computadores 2Adri SsAún no hay calificaciones
- Manual para Acceder A La Base de Datos Del EcmwfDocumento7 páginasManual para Acceder A La Base de Datos Del EcmwfLaura PacciniAún no hay calificaciones
- Manual NagiosDocumento21 páginasManual NagiosJose Calachahuin0% (1)
- TFG Rodríguez Martínez 2015-4Documento24 páginasTFG Rodríguez Martínez 2015-4Kevin GarcíaAún no hay calificaciones
- $ Cat /proc/$$/mapsDocumento3 páginas$ Cat /proc/$$/mapszonaXXXAún no hay calificaciones
- Extensión Las Multi Tareas Con Python® y Procesadores AutónomosDocumento7 páginasExtensión Las Multi Tareas Con Python® y Procesadores AutónomosMiguel VicharraAún no hay calificaciones
- EnunciadoDocumento8 páginasEnunciadomanu claseAún no hay calificaciones
- Extensión Las Multi Tareas Con Python® y Procesadores AutónomosDocumento7 páginasExtensión Las Multi Tareas Con Python® y Procesadores AutónomosRCBAún no hay calificaciones
- Apuntes PVMDocumento36 páginasApuntes PVMDavid Agui LeraAún no hay calificaciones
- Curso Avanzado GradsDocumento49 páginasCurso Avanzado GradsGuisseppe Vasquez67% (3)
- Presentación 1Documento29 páginasPresentación 1Jonathan Juli VelazcoAún no hay calificaciones
- MRTGDocumento3 páginasMRTGEdy VilemaAún no hay calificaciones
- Hito1-Algoritmos UpcDocumento21 páginasHito1-Algoritmos UpcShiara ArauzoAún no hay calificaciones
- Manual de Usuario de BellatorDocumento9 páginasManual de Usuario de BellatorJavier IriberriAún no hay calificaciones
- Softwares de Ventilacion FinalDocumento24 páginasSoftwares de Ventilacion FinalWilber PilcoAún no hay calificaciones
- Práctica 06 Introducción A BDE Con PostGISDocumento15 páginasPráctica 06 Introducción A BDE Con PostGISJOAN SEBASTIAN DIAZ GOMEZAún no hay calificaciones
- Geo FarpdfDocumento73 páginasGeo FarpdfJanno Ahumada TorrejonAún no hay calificaciones
- BoletinPractica2 Febrero2022Documento5 páginasBoletinPractica2 Febrero2022Adrian GarmendiaAún no hay calificaciones
- Taller Geovisor FinalDocumento31 páginasTaller Geovisor Finalser_altesco100% (1)
- (SO2) Enunciado Práctica#1Documento4 páginas(SO2) Enunciado Práctica#1César SazoAún no hay calificaciones
- Transformacion de Ed50 A Etrs89Documento11 páginasTransformacion de Ed50 A Etrs89pollodelaabuelaAún no hay calificaciones
- Cambio de Sistema de Referencia para Ortofotos Con Quantum GIS 2.2Documento11 páginasCambio de Sistema de Referencia para Ortofotos Con Quantum GIS 2.2JesúsLópezAún no hay calificaciones
- Cambio de Sistemas QgisDocumento11 páginasCambio de Sistemas QgisNoelia Concpción CntenoAún no hay calificaciones
- Seis CompDocumento35 páginasSeis CompLaura Lara OrtizAún no hay calificaciones
- Guia de Actividades y Rúbrica de Evaluación - Tarea 2 - Datos Geográficos y Aplicativos SIGDocumento13 páginasGuia de Actividades y Rúbrica de Evaluación - Tarea 2 - Datos Geográficos y Aplicativos SIGmarcelaAún no hay calificaciones
- Node RedDocumento9 páginasNode RedAndres FloresAún no hay calificaciones
- Anexo 2.c Diseño de Redes Con Ics TelecomDocumento51 páginasAnexo 2.c Diseño de Redes Con Ics TelecomIgor Venavidez100% (1)
- Lab 02 - Data Transformation & IndexesDocumento3 páginasLab 02 - Data Transformation & Indexesdanny estradaAún no hay calificaciones
- Ultima PeopleCodeDocumento25 páginasUltima PeopleCodesunmikelAún no hay calificaciones
- InstalandoGMT4 5 12Documento5 páginasInstalandoGMT4 5 12Alfredo SalazarAún no hay calificaciones
- MRTGDocumento4 páginasMRTGRodrigo Uruchi0% (1)
- Instalacion postgreSQLDocumento10 páginasInstalacion postgreSQLJavier HAAún no hay calificaciones
- Tutorial - Spatial Network AnalysisDocumento8 páginasTutorial - Spatial Network AnalysisYesicaAún no hay calificaciones
- FAJARDO Tutorial Diseño de Procesadores de Proposito EspecificoDocumento26 páginasFAJARDO Tutorial Diseño de Procesadores de Proposito EspecificoNJ RSAún no hay calificaciones
- Anexo 3.2 Capacitacion 2 Manual Uso PostGis PDFDocumento22 páginasAnexo 3.2 Capacitacion 2 Manual Uso PostGis PDFSergioAún no hay calificaciones
- WRF2Documento8 páginasWRF2RandallHellVargasPradinettAún no hay calificaciones
- MRTGDocumento12 páginasMRTGDanilo HidalgoAún no hay calificaciones
- Trabajando Con LiDAR en FUSIONDocumento13 páginasTrabajando Con LiDAR en FUSIONPat YqllAún no hay calificaciones
- Guía para El Desarrollo Del Componente Practico y Rubrica de Evaluacion - Tarea 5 - Participar Del Componente Practico Mediado Por TecnologíaDocumento14 páginasGuía para El Desarrollo Del Componente Practico y Rubrica de Evaluacion - Tarea 5 - Participar Del Componente Practico Mediado Por TecnologíaYESSICA CERON MUÑOZAún no hay calificaciones
- CalcularDocumento4 páginasCalcularYovaniFranklinAún no hay calificaciones
- Aso 2020 09Documento4 páginasAso 2020 09Antonio MembriveAún no hay calificaciones
- Instalacion ZoneminderDocumento4 páginasInstalacion ZonemindercidlobusAún no hay calificaciones
- Informe Del SistemaDocumento3 páginasInforme Del SistemaDANIEL ELIAS PACORE GUTIERREZAún no hay calificaciones
- 04 4 TALLER Redes Comando PingDocumento6 páginas04 4 TALLER Redes Comando PingElissa Castellar MartinezAún no hay calificaciones
- Rroo2 PDFDocumento20 páginasRroo2 PDFpapiAún no hay calificaciones
- El BusDocumento5 páginasEl BusEduardo GonzalezAún no hay calificaciones
- DatosDocumento2 páginasDatosNadia Cantero Barruetabeña100% (1)
- Caracteristicas Pic16f84aDocumento6 páginasCaracteristicas Pic16f84aandre izakAún no hay calificaciones
- Lab 02 - Instalación de Controladores de DominioDocumento33 páginasLab 02 - Instalación de Controladores de DominioCristian Nestor Belizario ApazaAún no hay calificaciones
- Vit NP5540M3Documento3 páginasVit NP5540M3Luis Fernando Muro CarpioAún no hay calificaciones
- Actividad 3Documento13 páginasActividad 3Gabo CrassusAún no hay calificaciones
- Requisitos de ADOBEDocumento5 páginasRequisitos de ADOBETHALIA ESMERALDA ALARCON CERCADOAún no hay calificaciones
- Manual de Instalacion Ubuntu Sever 16.04 x86Documento21 páginasManual de Instalacion Ubuntu Sever 16.04 x86Canyfel Amigo FielAún no hay calificaciones
- Actividad Eje 4 Informatica Forense IDocumento8 páginasActividad Eje 4 Informatica Forense IFabian IrreñoAún no hay calificaciones
- Laboratorio #2 - Capa de Aplicacion DHCP, DNS, y HTTPDocumento6 páginasLaboratorio #2 - Capa de Aplicacion DHCP, DNS, y HTTPDaniel Baldeon100% (1)
- Cisco Switch 2948g-l3 Hoja de DatosDocumento6 páginasCisco Switch 2948g-l3 Hoja de Datoserickp_11Aún no hay calificaciones
- Topologia Radius TacacsDocumento5 páginasTopologia Radius TacacsAguilarAún no hay calificaciones
- Informe IISDocumento32 páginasInforme IISChristian AceroAún no hay calificaciones
- Sistemas Distribuidos y CentralizadosDocumento1 páginaSistemas Distribuidos y Centralizadoscatalina riveraAún no hay calificaciones
- Tarea 3 Sistemas DigitalesDocumento3 páginasTarea 3 Sistemas DigitalesMartin GomezAún no hay calificaciones
- Cencosud Newland - 12704733Documento44 páginasCencosud Newland - 12704733German ArciniegasAún no hay calificaciones
- Modelo Osi y ProtocolosDocumento21 páginasModelo Osi y ProtocolosJesus Opon100% (1)
- Las Nuevas Tendencias en Las BDDocumento4 páginasLas Nuevas Tendencias en Las BDlitzi cruz navarroAún no hay calificaciones
- Unidad Aritmetico Logica ALUDocumento29 páginasUnidad Aritmetico Logica ALUSergio BahamonAún no hay calificaciones
- Características de Los Sistemas de AlmacenamientoDocumento11 páginasCaracterísticas de Los Sistemas de AlmacenamientoJuan CarlosAún no hay calificaciones
- UD02 - Soluciones - Sistemas Operativos - TIC I PDFDocumento9 páginasUD02 - Soluciones - Sistemas Operativos - TIC I PDFmaestraAún no hay calificaciones
- Noctua NH d15 Manual Es Web 1Documento4 páginasNoctua NH d15 Manual Es Web 1Francisco Diez CasalAún no hay calificaciones
- Vlan - Configuraciones de Servidor y Cliente VTP PDFDocumento6 páginasVlan - Configuraciones de Servidor y Cliente VTP PDFJorge Antonio Ugarte SaiquitaAún no hay calificaciones