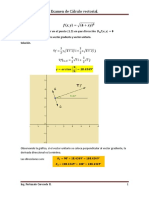
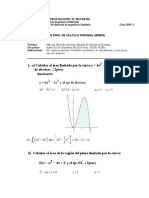
También podría gustarte
- Formulario Proba y Estadista 2021Documento19 páginasFormulario Proba y Estadista 2021Marito KontreAún no hay calificaciones
- Clase 9 D.muestralDocumento13 páginasClase 9 D.muestralHans Heredia (Beto)Aún no hay calificaciones
- Primer CertamenDocumento8 páginasPrimer CertamenDanilo MuñozAún no hay calificaciones
- Formula RioDocumento21 páginasFormula RioJoan NavarroAún no hay calificaciones
- Fórmulas de Estadística - S1Documento4 páginasFórmulas de Estadística - S1Junior Daygoro Navarro IpanaqueAún no hay calificaciones
- Formulario ProbabilidadDocumento8 páginasFormulario ProbabilidadVanesa LeónAún no hay calificaciones
- Formulario Tercera Prueba Inmt 31Documento2 páginasFormulario Tercera Prueba Inmt 31Fabián EspozAún no hay calificaciones
- Formulario Examen FinalDocumento1 páginaFormulario Examen FinalMiguel Angel Cordova CordovaAún no hay calificaciones
- Formulario Parcial 1 EstadisticaDocumento2 páginasFormulario Parcial 1 EstadisticaStefany SantanaAún no hay calificaciones
- IQA270 2022-02 FormularioDocumento2 páginasIQA270 2022-02 FormularioVicente CastroAún no hay calificaciones
- ParametroDocumento14 páginasParametroTania DueñasAún no hay calificaciones
- UntitledDocumento1 páginaUntitledAndres De MoyaAún no hay calificaciones
- ANTOLOGÍA PYE Instituto OrienteDocumento17 páginasANTOLOGÍA PYE Instituto OrienteSantiago Ruiz PAún no hay calificaciones
- Transformada de Fourier para La Teoría de La SeñalDocumento2 páginasTransformada de Fourier para La Teoría de La SeñalSebastián AleagaAún no hay calificaciones
- Fórmulas de Probabilidad y EstadísticaDocumento5 páginasFórmulas de Probabilidad y EstadísticaMaria NietoAún no hay calificaciones
- Solución EPDocumento4 páginasSolución EPXIOMI JHISIAN PADILLA VELAAún no hay calificaciones
- 1.3. - Método de EulerDocumento22 páginas1.3. - Método de EulerJuan Manuel OliverosAún no hay calificaciones
- Derivadas Parciales Moodle1Documento10 páginasDerivadas Parciales Moodle1Soliz Espada Juan JoséAún no hay calificaciones
- ADA4 InfEst LIS Equipo6Documento10 páginasADA4 InfEst LIS Equipo6mgltchmAún no hay calificaciones
- S02 s3 - MATERIALDocumento19 páginasS02 s3 - MATERIALJhonwill Ricse LeyvaAún no hay calificaciones
- Guía Números Complejos UTN-2020Documento13 páginasGuía Números Complejos UTN-2020Alejandro BaroldiAún no hay calificaciones
- Procesamiento Digital de Señales Transformada Z Filtro IIR Y FIR.Documento8 páginasProcesamiento Digital de Señales Transformada Z Filtro IIR Y FIR.alexis pedrozaAún no hay calificaciones
- Un Formulario para EstadisticaDocumento5 páginasUn Formulario para EstadisticaDaniel Robinson GutierrezAún no hay calificaciones
- Derivada Direccional - Ejercicio ResueltoDocumento4 páginasDerivada Direccional - Ejercicio ResueltoUriel GodinezAún no hay calificaciones
- FORMULARIO PROBABILIDAD Y ESTADISTICA Unidad 1 y 2Documento6 páginasFORMULARIO PROBABILIDAD Y ESTADISTICA Unidad 1 y 2Daniel QuirozAún no hay calificaciones
- TMMG 7Documento6 páginasTMMG 7Miguel Ángel DiazAún no hay calificaciones
- Funcion ExponencialDocumento6 páginasFuncion Exponencial5439172023Aún no hay calificaciones
- 16 Tarea 2 Calculo MultivariadoDocumento32 páginas16 Tarea 2 Calculo MultivariadoKarenAún no hay calificaciones
- Examen Parcial Mate 3 16-IDocumento9 páginasExamen Parcial Mate 3 16-ICésar OchoaAún no hay calificaciones
- Método de Ortogonalización de GramDocumento10 páginasMétodo de Ortogonalización de Gramcarlos noelAún no hay calificaciones
- CarbonDocumento14 páginasCarbonDaniel AleAún no hay calificaciones
- Mat1101parteiii 20Documento41 páginasMat1101parteiii 20Breydi CaceresAún no hay calificaciones
- Practica2 Grupo BDocumento9 páginasPractica2 Grupo BMauricio Jose Conza ArmijosAún no hay calificaciones
- 17) DerivadaDireccional - VectorGradienteDocumento4 páginas17) DerivadaDireccional - VectorGradienteJose Armando Ramos UrbinaAún no hay calificaciones
- GEOMETRÍA DIFERENCIAL. Teoría1Documento7 páginasGEOMETRÍA DIFERENCIAL. Teoría1Raquel TorrezAún no hay calificaciones
- Ejercicio de Nano OpticaDocumento2 páginasEjercicio de Nano OpticaJesus PerezAún no hay calificaciones
- Solución - PR5 A2 15IDocumento4 páginasSolución - PR5 A2 15IDeyver Morales YarlequeAún no hay calificaciones
- Ejercicios Desarrollados de V.a.1Documento9 páginasEjercicios Desarrollados de V.a.1Yomer CernaAún no hay calificaciones
- Guia de Trabajos Practicos de Algebra y Geometria Analitica ComprimidoDocumento80 páginasGuia de Trabajos Practicos de Algebra y Geometria Analitica ComprimidoMelina aylen Loscalzo acostaAún no hay calificaciones
- Ecuaciones FisicoquimicaDocumento1 páginaEcuaciones FisicoquimicaDaniel GutierrezAún no hay calificaciones
- Formulario Integrales Calculo2 (Ex de Mesa)Documento4 páginasFormulario Integrales Calculo2 (Ex de Mesa)Servant EmiyaAún no hay calificaciones
- Formulario Estadistica II. Alina TrujilloDocumento4 páginasFormulario Estadistica II. Alina TrujilloNarah Sophia CuellarAún no hay calificaciones
- Pavon - Daysi - Resumen Clase 3Documento6 páginasPavon - Daysi - Resumen Clase 3Abi PavónAún no hay calificaciones
- CLASE 1 Vectores en R3, Geometría Analítica Espacial V1.Documento9 páginasCLASE 1 Vectores en R3, Geometría Analítica Espacial V1.Santiago Leonardo Marcillo HidalgoAún no hay calificaciones
- Clase 5 Unidad IDocumento11 páginasClase 5 Unidad IJunior PonceAún no hay calificaciones
- Prepa 7Documento8 páginasPrepa 7Alex UribeAún no hay calificaciones
- Bfi03 Semana2 Sesion2Documento6 páginasBfi03 Semana2 Sesion2fpfelix96Aún no hay calificaciones
- El Pendulo BalisticoDocumento4 páginasEl Pendulo BalisticoSebastian GarciaAún no hay calificaciones
- Apmat p2Documento11 páginasApmat p2Ramón Flores RodríguezAún no hay calificaciones
- Metodos para Crear Nuevas DistribucionesDocumento4 páginasMetodos para Crear Nuevas DistribucionesKira AyuzawaAún no hay calificaciones
- Área de La Superficie de Revolución IIDocumento15 páginasÁrea de La Superficie de Revolución IIJannlyn ContramaestreAún no hay calificaciones
- Resolución Del Examen Final de 2019 2 Cálculo IntegralDocumento5 páginasResolución Del Examen Final de 2019 2 Cálculo IntegralJesus Miguel Huaman ChingAún no hay calificaciones
- Ecuaciones Diferenciales de Primer Orden.Documento15 páginasEcuaciones Diferenciales de Primer Orden.sandraAún no hay calificaciones
- Ecuaciones Diferenciales Ejercicios LeoDocumento10 páginasEcuaciones Diferenciales Ejercicios LeoLeo RamirezAún no hay calificaciones
- 4 DerivadasDocumento5 páginas4 DerivadasCarlos Elmer Huanca PomaAún no hay calificaciones
- Filtro FIR Y IIR, Analisis MatematicoDocumento8 páginasFiltro FIR Y IIR, Analisis Matematicoalexis pedrozaAún no hay calificaciones
- Procesamiento Digital de Señales, Filtros, Transformada Z.Documento6 páginasProcesamiento Digital de Señales, Filtros, Transformada Z.alexis pedrozaAún no hay calificaciones
- Práctica Probabilidad GCPDocumento5 páginasPráctica Probabilidad GCPGabriel CallejasAún no hay calificaciones
- Taller 5 DBADocumento28 páginasTaller 5 DBAJailene AtencioAún no hay calificaciones
- Soluc PC 1-Cgt-Ean 12436 - 2019 II UtpDocumento3 páginasSoluc PC 1-Cgt-Ean 12436 - 2019 II UtpeldeivissAún no hay calificaciones
- Serie - Del - Segundo - Parcial - 5moreno SergioDocumento7 páginasSerie - Del - Segundo - Parcial - 5moreno Sergiosergio valdez0% (1)
- MUESTREODocumento9 páginasMUESTREOStick EscuderoAún no hay calificaciones
- Calculo de Tamaño de Muestra-Plantilla de ExcelDocumento5 páginasCalculo de Tamaño de Muestra-Plantilla de ExcelScream PxndxAún no hay calificaciones
- Planes de Muestreo Por AtributosDocumento16 páginasPlanes de Muestreo Por AtributosYesicaAún no hay calificaciones
- Unidad 1 - Paso 3 - Análisis de La InformaciónDocumento12 páginasUnidad 1 - Paso 3 - Análisis de La InformaciónJuan Diego Uribe MuñozAún no hay calificaciones
- Kevin Brian Roblero Perez. Ejercicios InfoStatDocumento17 páginasKevin Brian Roblero Perez. Ejercicios InfoStatkevin robleroAún no hay calificaciones
- Trabajo FinalDocumento23 páginasTrabajo FinalDerick RamosAún no hay calificaciones
- Control-1 Econometria 2sem 2022-PautaDocumento4 páginasControl-1 Econometria 2sem 2022-PautaJAVIER VEGAAún no hay calificaciones
- EJEMPLOSDocumento80 páginasEJEMPLOSSebastián Valencia PinedoAún no hay calificaciones
- Actividad 4.1 y 4.2 Estadistica 2Documento12 páginasActividad 4.1 y 4.2 Estadistica 2GUILLERMO ESPARZAAún no hay calificaciones
- Diseño ExperimentalDocumento7 páginasDiseño ExperimentalBrayan D Murillo GAún no hay calificaciones
- Apuntes Estadistica Inferencial 1 PDFDocumento355 páginasApuntes Estadistica Inferencial 1 PDFOtoniel Pecina Hernandez67% (3)
- Resumen Segundo Parcial (Teoría) - ESTADÍSTICA 1 - UBA FCEDocumento5 páginasResumen Segundo Parcial (Teoría) - ESTADÍSTICA 1 - UBA FCEJohn DoeAún no hay calificaciones
- 4.5 Probabilidad y EstadisticaDocumento3 páginas4.5 Probabilidad y Estadisticajared velazquez100% (1)
- Taller 5 WordDocumento5 páginasTaller 5 WordAlejandraAún no hay calificaciones
- Analisis de ConsistenciaDocumento25 páginasAnalisis de ConsistenciaJulio Nejer Maguiña ChavezAún no hay calificaciones
- Medidas de Tendencia CentralDocumento18 páginasMedidas de Tendencia CentralGINA BUSTOS100% (2)
- Que Se Entiende Por Una Población HomogéneaDocumento6 páginasQue Se Entiende Por Una Población HomogéneaDAYANA CHACHA CASTROAún no hay calificaciones
- Ultima Actualidaod 1700Documento36 páginasUltima Actualidaod 1700Edison Paul RAún no hay calificaciones
- La Estadística Descriptiva Es Una Ciencia Que Analiza Series de DatosDocumento14 páginasLa Estadística Descriptiva Es Una Ciencia Que Analiza Series de Datossmeting2495Aún no hay calificaciones
- Actividad Medidas de Tendencia CentralDocumento2 páginasActividad Medidas de Tendencia CentralDaniela VargasAún no hay calificaciones
- Tarea Preparatoria 1Documento3 páginasTarea Preparatoria 1anaAún no hay calificaciones
- Ajuste Del Modelo de Regresión Lineal Con Múltiples VariablesDocumento22 páginasAjuste Del Modelo de Regresión Lineal Con Múltiples VariablesCarina ChacónAún no hay calificaciones
- ESTADISTICADocumento8 páginasESTADISTICACRISTHIAN JESUS VILLARREAL SOSAAún no hay calificaciones
- Tarea #1 Estephanie EucedaDocumento10 páginasTarea #1 Estephanie EucedaEstephanie Carolina Euceda GarxiasAún no hay calificaciones
- Tarea # 6Documento14 páginasTarea # 6maira mujicaAún no hay calificaciones
- Copia de La Casa Del PernoDocumento22 páginasCopia de La Casa Del PernoAnthonyMLAún no hay calificaciones