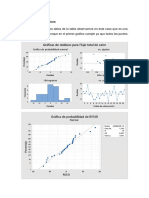
También podría gustarte
- Modelo Potencial CorregidoDocumento12 páginasModelo Potencial CorregidoRenuevix CelestialAún no hay calificaciones
- Linealidad y FlúorDocumento37 páginasLinealidad y FlúorFlorent TobarAún no hay calificaciones
- TERMINEDocumento10 páginasTERMINEMANUEL ESPINOZAAún no hay calificaciones
- Trabajo FinalDocumento113 páginasTrabajo FinalMoy PMAún no hay calificaciones
- Clase Estadística CorrelaciónDocumento27 páginasClase Estadística CorrelaciónYesenia GallegosAún no hay calificaciones
- Regresion LinealDocumento16 páginasRegresion Linealdemon RAún no hay calificaciones
- SalidaDocumento7 páginasSalidayulimarAún no hay calificaciones
- Actividad 2 U4Documento18 páginasActividad 2 U4Effect MtzAún no hay calificaciones
- Taller Prueba de Hipotesis # 2Documento7 páginasTaller Prueba de Hipotesis # 2Henry SuarezAún no hay calificaciones
- Regresion LinealDocumento41 páginasRegresion LinealGrosnman AlenberthpAún no hay calificaciones
- tp4b Ej 12,14Documento3 páginastp4b Ej 12,14Miguel LlaryoraAún no hay calificaciones
- 4 AlumnosDocumento4 páginas4 AlumnosDiego UrielAún no hay calificaciones
- Pruebas Estadisticas para Numeros Aleatorios SimulacionDocumento8 páginasPruebas Estadisticas para Numeros Aleatorios SimulacionGustavo GomezAún no hay calificaciones
- Módulo IV Modelos de RegresiónDocumento16 páginasMódulo IV Modelos de RegresiónDiego Armando Ramirez HernandezAún no hay calificaciones
- Tema 6 - Problemas y Ejemplos de Medición Del Tiempo - DavidDocumento18 páginasTema 6 - Problemas y Ejemplos de Medición Del Tiempo - DavidAndrés David Sanga TitoAún no hay calificaciones
- Contrastes No Cos I v3Documento34 páginasContrastes No Cos I v3cl2011Aún no hay calificaciones
- Parte 3 - Trabajo IntegradorDocumento7 páginasParte 3 - Trabajo IntegradorCristhian Ricardo Ortiz VariasAún no hay calificaciones
- EstAp EV2Documento9 páginasEstAp EV2oliverio tijerina aréchigaAún no hay calificaciones
- Practica2.Inferencia Una PoblaciónDocumento15 páginasPractica2.Inferencia Una PoblaciónadrianAún no hay calificaciones
- Primera Parte Del Trabajo Final. Estadistica Inferencial. Rigoberto AmericoDocumento100 páginasPrimera Parte Del Trabajo Final. Estadistica Inferencial. Rigoberto AmericoTrigo san100% (1)
- Exámenes Recientes Con Solución de La PrácticaDocumento31 páginasExámenes Recientes Con Solución de La Prácticamarta.p.olmedoAún no hay calificaciones
- Modelos ProbabilísticosDocumento25 páginasModelos ProbabilísticosJoelAún no hay calificaciones
- Notas Sobre Inferencia EstadísticaDocumento7 páginasNotas Sobre Inferencia EstadísticaRICARDO ANGEL BERRIO PEREZAún no hay calificaciones
- 2d +Instructivo+Uso+de+Tabla+ZDocumento5 páginas2d +Instructivo+Uso+de+Tabla+ZMiguel UBAún no hay calificaciones
- Prueba 2 - EST 301 - 2SEM - 2022 - PAUTADocumento4 páginasPrueba 2 - EST 301 - 2SEM - 2022 - PAUTAFranko Ignacio Perez CarvajalAún no hay calificaciones
- Ejercicio de Regresión LinealDocumento9 páginasEjercicio de Regresión LinealEmyBenaventeAún no hay calificaciones
- Prueba de HipótesisDocumento8 páginasPrueba de HipótesisIke_CollpaAún no hay calificaciones
- Seis Sigma BB AnalisisDocumento688 páginasSeis Sigma BB AnalisisLilia Navarro ValverdeAún no hay calificaciones
- Evaluación Del Modelo de Regresión Lineal SimpleDocumento8 páginasEvaluación Del Modelo de Regresión Lineal Simplejose zeaAún no hay calificaciones
- Practica Estadistica Aplicada A MetrologiaDocumento21 páginasPractica Estadistica Aplicada A MetrologiaAnonymous SiO8gwwRtoAún no hay calificaciones
- Seis Sigma BB AnalisisDocumento688 páginasSeis Sigma BB Analisistlatuani1000Aún no hay calificaciones
- 50 Minaard PDFDocumento10 páginas50 Minaard PDFjim130Aún no hay calificaciones
- Modelo LinealDocumento10 páginasModelo LinealJosé de J Pérez HAún no hay calificaciones
- Unidad06 EstimacionIntervalosDocumento30 páginasUnidad06 EstimacionIntervalosFrancisco Javier0% (1)
- Prueba de HipotesisDocumento7 páginasPrueba de HipotesisKaren MontañoAún no hay calificaciones
- Métodos Numericos Método de BiseccionDocumento10 páginasMétodos Numericos Método de BiseccionBrian JersonAún no hay calificaciones
- Ejercicios Propuestos - ESTADISTICA AVANZADADocumento13 páginasEjercicios Propuestos - ESTADISTICA AVANZADAIngescol SasAún no hay calificaciones
- Tarea 2Documento5 páginasTarea 2MenesesAugustoAún no hay calificaciones
- TALLER 3 Una Media Cola DerechaDocumento6 páginasTALLER 3 Una Media Cola DerechacursosmiguelaguilarAún no hay calificaciones
- Trabajo Grupal EstadísticaDocumento42 páginasTrabajo Grupal EstadísticaJosuë0% (4)
- Clas 9Documento16 páginasClas 9Leslie Celenia Limache FuentesAún no hay calificaciones
- Examen - Sustitutorio - Unidad2 - ORLANDO SUAREZ CANCINODocumento13 páginasExamen - Sustitutorio - Unidad2 - ORLANDO SUAREZ CANCINOLUIS DAVID ZAVALETA GUTIERREZAún no hay calificaciones
- Diapositivas de RegresiónDocumento30 páginasDiapositivas de RegresiónEliana Cárdenas LealAún no hay calificaciones
- 3.5. Actividad # 2 - 1124858960Documento11 páginas3.5. Actividad # 2 - 1124858960Silvio RamirezAún no hay calificaciones
- Practica 12 Regresion Lineal y CorrelacionDocumento15 páginasPractica 12 Regresion Lineal y CorrelacionOswaldo ZamoraAún no hay calificaciones
- Tema 5Documento13 páginasTema 5Victoresteban2Aún no hay calificaciones
- Ayudantia N1 EconoDocumento17 páginasAyudantia N1 EconoBrian Philippe Tampier TapiaAún no hay calificaciones
- CUARTA PRÁCTICA (Recuperado Automáticamente)Documento26 páginasCUARTA PRÁCTICA (Recuperado Automáticamente)JOAN JUNIORS ATENCIO VELASQUEZAún no hay calificaciones
- Segundo Parcial G81 SolucionesDocumento2 páginasSegundo Parcial G81 SolucionesSrCuscusAún no hay calificaciones
- Ejercicio - Columna de Destilación Fraccionada Con Dos AlimentacionesDocumento7 páginasEjercicio - Columna de Destilación Fraccionada Con Dos AlimentacionesLuis Alfredo Cuentas CotrinaAún no hay calificaciones
- Consolidado Fisica 1 Trabajo Colaborativo Grupo 31Documento17 páginasConsolidado Fisica 1 Trabajo Colaborativo Grupo 31CRISTIAN VASQUEZAún no hay calificaciones
- Sesion 12. Ejercicios de Analisis de Regresion y Correlacion Sep 2021Documento16 páginasSesion 12. Ejercicios de Analisis de Regresion y Correlacion Sep 2021Maribel Sanchez LauraAún no hay calificaciones
- UNIDAD 2 Paso 4 - JOHAN MARULANDADocumento13 páginasUNIDAD 2 Paso 4 - JOHAN MARULANDAJohan MarulandaAún no hay calificaciones
- CorrelaciónDocumento22 páginasCorrelaciónERIKA TATIANA PATINO JIMENEZAún no hay calificaciones
- CI171 Unidad 5 Aproximacion Funciones 2022 01Documento53 páginasCI171 Unidad 5 Aproximacion Funciones 2022 01Nallely YanacAún no hay calificaciones
- REGRESIONDocumento111 páginasREGRESIONMaria Castro GamarraAún no hay calificaciones
- Interpolación bilineal: Mejora de la resolución y claridad de la imagen mediante interpolación bilinealDe EverandInterpolación bilineal: Mejora de la resolución y claridad de la imagen mediante interpolación bilinealAún no hay calificaciones
- Problemas resueltos de Hidráulica de CanalesDe EverandProblemas resueltos de Hidráulica de CanalesCalificación: 4.5 de 5 estrellas4.5/5 (7)
- Actividad Regresión y CorrelaciónDocumento2 páginasActividad Regresión y CorrelaciónKath ParedesAún no hay calificaciones
- Ejercicio de Modelo de SupervivenciaDocumento6 páginasEjercicio de Modelo de SupervivenciaKath ParedesAún no hay calificaciones
- InterpolaracionDocumento1 páginaInterpolaracionKath ParedesAún no hay calificaciones
- EvaluaciónDocumento1 páginaEvaluaciónKath ParedesAún no hay calificaciones
- ExamenDocumento2 páginasExamenKath ParedesAún no hay calificaciones
- Tarea Individual 3.1Documento15 páginasTarea Individual 3.1Kath ParedesAún no hay calificaciones
- Trabajo ColaborativoDocumento1 páginaTrabajo ColaborativoKath ParedesAún no hay calificaciones
- Muestreo Secuencial y Muestreo MúltipleDocumento8 páginasMuestreo Secuencial y Muestreo MúltipleAlejandro NatanzónAún no hay calificaciones
- Trabajo de Variables Aleatorias y Distribuciones de ProbabilidadDocumento10 páginasTrabajo de Variables Aleatorias y Distribuciones de ProbabilidadJanio Suarez FuentesAún no hay calificaciones
- Producto AcadémicoDocumento22 páginasProducto AcadémicoFERNANDO INOCENTE TRINIDAD GUERRA100% (1)
- Curso Estadisticas Ingreso Medicina Exani IIDocumento21 páginasCurso Estadisticas Ingreso Medicina Exani IIUby kyouyamaAún no hay calificaciones
- Instrumentacion Didactica - Estadistica Inferencial I - IQ-cDr. Jose A. Sarricolea ValenciaDocumento39 páginasInstrumentacion Didactica - Estadistica Inferencial I - IQ-cDr. Jose A. Sarricolea ValenciaJose Adalberto Sarricolea ValenciaAún no hay calificaciones
- Grupo 2 Elementos Que Integran Un Reporte de Investigación CuantitativaDocumento11 páginasGrupo 2 Elementos Que Integran Un Reporte de Investigación CuantitativaSteven Malave SanchezAún no hay calificaciones
- Qué Es La TerminologíaDocumento11 páginasQué Es La TerminologíaIris TovarAún no hay calificaciones
- Antología Diagnóstico Cultura Organizacional: Michael QuesadaDocumento14 páginasAntología Diagnóstico Cultura Organizacional: Michael QuesadaVanessa LoaizaAún no hay calificaciones
- Conceptos Generales Con Las Pruebas de HipotesisDocumento11 páginasConceptos Generales Con Las Pruebas de Hipotesislitzy arteaga guzmanAún no hay calificaciones
- Trabajo Practico de Estadistica 19Documento16 páginasTrabajo Practico de Estadistica 19Rosalin FloresAún no hay calificaciones
- Diseños Completamente Aleatorio y AnovaDocumento20 páginasDiseños Completamente Aleatorio y AnovaGlOw MTz67% (6)
- Prueba de EstabilidadDocumento3 páginasPrueba de EstabilidadDavid Ignacio Berastain HurtadoAún no hay calificaciones
- Requisitos de Estadística DescriptivaDocumento1 páginaRequisitos de Estadística DescriptivalolololoAún no hay calificaciones
- La Estrategia DMAICDocumento14 páginasLa Estrategia DMAICGERARDO RAFAEL REYNOSO IBARRAAún no hay calificaciones
- Eca PrograDocumento21 páginasEca Prograr0bert0iiAún no hay calificaciones
- Diseño de La InvestigaciónDocumento26 páginasDiseño de La Investigaciónjonatan ricaldiAún no hay calificaciones
- Simulacion Act1Documento7 páginasSimulacion Act1Javier CalderónAún no hay calificaciones
- Estadistica y ProbabilidadDocumento14 páginasEstadistica y ProbabilidadlucerokatAún no hay calificaciones
- AutoevaluaciónDocumento5 páginasAutoevaluaciónXiomaraMendozaAún no hay calificaciones
- Homogeneidad de Las Series PDFDocumento6 páginasHomogeneidad de Las Series PDFjosue rochaAún no hay calificaciones
- Examen Final Estadistica Diferencial 2 ParteDocumento4 páginasExamen Final Estadistica Diferencial 2 ParteAlvaro OreAún no hay calificaciones
- Análisis MultivariadoDocumento10 páginasAnálisis MultivariadocristaAún no hay calificaciones
- Automatizada 5Documento2 páginasAutomatizada 5flak.arenitaAún no hay calificaciones
- Mapa Est AVA 4 835faee0031a298Documento3 páginasMapa Est AVA 4 835faee0031a298Jose GutierrezAún no hay calificaciones
- Paso 4 - PsicometríaDocumento14 páginasPaso 4 - PsicometríaAmayra Barros BeltranAún no hay calificaciones
- NotasdeClaseDocumento8 páginasNotasdeClaseAndres BejaranoAún no hay calificaciones
- Tipos de Investigación Científica y Sus CaracterísticasDocumento25 páginasTipos de Investigación Científica y Sus CaracterísticasFanny CastelblancoAún no hay calificaciones
- Derecho A La LibertadDocumento212 páginasDerecho A La LibertadMariana Melendez CruzAún no hay calificaciones
- Sílabo: Datos GeneralesDocumento10 páginasSílabo: Datos GeneralesJean GonzalesAún no hay calificaciones
- Calculo de La Capacidad Del ProcesoDocumento4 páginasCalculo de La Capacidad Del ProcesoMaricruz Contreras MadrigalAún no hay calificaciones