También podría gustarte
- Indicadores Epidemiológicos (Gero)Documento3 páginasIndicadores Epidemiológicos (Gero)g.forteza.ecoAún no hay calificaciones
- Demostraciones Del Modelo Lineal Simple (Gero)Documento14 páginasDemostraciones Del Modelo Lineal Simple (Gero)g.forteza.ecoAún no hay calificaciones
- EJEMPLO DE ANOVA CON DATOS (Gero)Documento1 páginaEJEMPLO DE ANOVA CON DATOS (Gero)g.forteza.ecoAún no hay calificaciones
- Cambio de BaseDocumento1 páginaCambio de Baseg.forteza.ecoAún no hay calificaciones
- Fórmulas en Epidemiología (Gero)Documento6 páginasFórmulas en Epidemiología (Gero)g.forteza.ecoAún no hay calificaciones
- Ejercicio Importante de MicroeconomíaDocumento1 páginaEjercicio Importante de Microeconomíag.forteza.ecoAún no hay calificaciones
- Corrección de Yates.Documento1 páginaCorrección de Yates.g.forteza.ecoAún no hay calificaciones
- Distribuciones de Probabilidad Con R (Gero)Documento8 páginasDistribuciones de Probabilidad Con R (Gero)g.forteza.ecoAún no hay calificaciones
- Ecuaciones DiofánticasDocumento13 páginasEcuaciones Diofánticasg.forteza.ecoAún no hay calificaciones
- Ecuaciones DiofánticasDocumento13 páginasEcuaciones Diofánticasg.forteza.ecoAún no hay calificaciones
- COMPONENTES PRINCIPALES (Gero)Documento10 páginasCOMPONENTES PRINCIPALES (Gero)g.forteza.ecoAún no hay calificaciones
- Aplicación Práctica Del Análisis de Componentes Principales.Documento7 páginasAplicación Práctica Del Análisis de Componentes Principales.g.forteza.ecoAún no hay calificaciones
- Error Tipo IIDocumento2 páginasError Tipo IIg.forteza.ecoAún no hay calificaciones
- Deducción de La Derivada de La Función Logarítmica en Cualquier Base (Hecho Por Gero)Documento2 páginasDeducción de La Derivada de La Función Logarítmica en Cualquier Base (Hecho Por Gero)g.forteza.ecoAún no hay calificaciones
- La Curva IS y La Curva LMDocumento8 páginasLa Curva IS y La Curva LMg.forteza.ecoAún no hay calificaciones
- Entropía en La Distribución Binomial (Gero)Documento2 páginasEntropía en La Distribución Binomial (Gero)g.forteza.ecoAún no hay calificaciones
- Entropía en La Distribución Binomial (Gero)Documento2 páginasEntropía en La Distribución Binomial (Gero)g.forteza.ecoAún no hay calificaciones
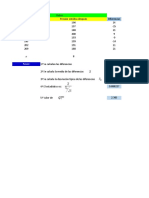
- Ejercicio de Diferencia de Medias Datos PareadosDocumento2 páginasEjercicio de Diferencia de Medias Datos Pareadosg.forteza.ecoAún no hay calificaciones
- Distribución F M, N (Gero)Documento2 páginasDistribución F M, N (Gero)g.forteza.ecoAún no hay calificaciones
- Cambio de Escala en Las Variables (Hecho Por Gero)Documento9 páginasCambio de Escala en Las Variables (Hecho Por Gero)g.forteza.ecoAún no hay calificaciones