También podría gustarte
- Aprendizaje de lenguas asistido por computador (CALLDocumento3 páginasAprendizaje de lenguas asistido por computador (CALLYerson ValenzuelaAún no hay calificaciones
- Aprendizaje de lenguas asistido por computador (CALLDocumento3 páginasAprendizaje de lenguas asistido por computador (CALLYerson ValenzuelaAún no hay calificaciones
- Disco Protoplanetario de Un SistemaDocumento1 páginaDisco Protoplanetario de Un SistemaYerson ValenzuelaAún no hay calificaciones
- Gestión de Infraestructuras Asistida Por ComputadoraDocumento2 páginasGestión de Infraestructuras Asistida Por ComputadoraYerson ValenzuelaAún no hay calificaciones
- Caja de Computadora ActualDocumento11 páginasCaja de Computadora ActualYerson ValenzuelaAún no hay calificaciones
- Seguridad de Redes para EmpresasDocumento2 páginasSeguridad de Redes para EmpresasYerson ValenzuelaAún no hay calificaciones
- La Constitucion de 1979Documento13 páginasLa Constitucion de 1979Michael Santos ChicllaAún no hay calificaciones
- T Ucsg Pre Eco Adm 45 PDFDocumento121 páginasT Ucsg Pre Eco Adm 45 PDFMarcos Smart GadgetsAún no hay calificaciones
- La Vida de Jaime BaylyDocumento23 páginasLa Vida de Jaime BaylyYerson Valenzuela50% (2)
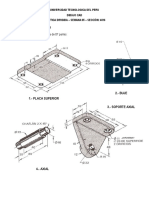
- Dibujo Cad EnsambleDocumento2 páginasDibujo Cad EnsambleYerson ValenzuelaAún no hay calificaciones
- Teoría General de SistemasDocumento4 páginasTeoría General de SistemasYerson ValenzuelaAún no hay calificaciones
- Diseño 4-Clase Engranajes Rectos1Documento36 páginasDiseño 4-Clase Engranajes Rectos1Yerson ValenzuelaAún no hay calificaciones
- ITIL vs COBIT: Comparación de marcos de gestión TIDocumento1 páginaITIL vs COBIT: Comparación de marcos de gestión TIالله ووكر وبالله100% (1)
- Ejemplos de Modo de ProducciónDocumento2 páginasEjemplos de Modo de Produccióncarol burgosAún no hay calificaciones
- Plan Hospitalario RCP H Virgen de Las NievesDocumento46 páginasPlan Hospitalario RCP H Virgen de Las NievesatalajacaAún no hay calificaciones
- Fichas SDP Se DocenteDocumento7 páginasFichas SDP Se DocentecinthyaAún no hay calificaciones
- Descargas ParcialesDocumento2 páginasDescargas ParcialesCarlos Villaseñor AvilaAún no hay calificaciones
- Magnatec 10w30 H TecnicaDocumento2 páginasMagnatec 10w30 H TecnicaJuly CFAún no hay calificaciones
- anexoDocRecursoApelaciones PHPDocumento4 páginasanexoDocRecursoApelaciones PHPsolucioneslegatesAún no hay calificaciones
- Secuencia Didactica Redes de ComputadorasDocumento2 páginasSecuencia Didactica Redes de ComputadorasCARLOS GONZALEZAún no hay calificaciones
- Trabajo Escalonado de Gestion de La SeguridadDocumento7 páginasTrabajo Escalonado de Gestion de La SeguridadAugusto Vilela100% (2)
- Obligación de DarDocumento32 páginasObligación de DarJimmy Joel Guevara CoralAún no hay calificaciones
- Medidores de FlujoDocumento8 páginasMedidores de FlujoluisAún no hay calificaciones
- Informe Final Proyecto de SoftwareDocumento2 páginasInforme Final Proyecto de SoftwareEduardo Zenteno Ramírez0% (1)
- Requisitos de RecursosDocumento3 páginasRequisitos de RecursosJamin mite0% (2)
- Procedimiento de inspección visual para limpieza de tanqueDocumento5 páginasProcedimiento de inspección visual para limpieza de tanqueKarla VelascoAún no hay calificaciones
- Tarea Tum 03Documento5 páginasTarea Tum 03DAVINIAAún no hay calificaciones
- Cuenta de CapitalDocumento5 páginasCuenta de CapitalandyAún no hay calificaciones
- Solucion. - Tarea 2 Balance de Materia y Energía. Seccion 04 2014-2015Documento6 páginasSolucion. - Tarea 2 Balance de Materia y Energía. Seccion 04 2014-2015JMGH80% (20)
- Introduccion A La Domotica PDFDocumento30 páginasIntroduccion A La Domotica PDFfmartosf100% (2)
- Ecos Diarios ClasificadosDocumento5 páginasEcos Diarios Clasificadoswebmaster3851Aún no hay calificaciones
- Competencias Del Desarrollo HumanoDocumento3 páginasCompetencias Del Desarrollo HumanoFermin Robles Ramos0% (1)
- Copia de Ejercicio 3Documento2 páginasCopia de Ejercicio 3Barbie RubioAún no hay calificaciones
- Ezshare 433119796 124Documento46 páginasEzshare 433119796 124betuco_1Aún no hay calificaciones
- Ejes PDFDocumento86 páginasEjes PDFErika Dayanna Gerena ArevaloAún no hay calificaciones
- Richard Lang PDFDocumento21 páginasRichard Lang PDFAlejandra AceroAún no hay calificaciones
- Tipos de Balances GeneralesDocumento2 páginasTipos de Balances Generalesdaynoky70% (10)
- Estudio de mercado de pintura látex en BoliviaDocumento152 páginasEstudio de mercado de pintura látex en Boliviaanon_267740532Aún no hay calificaciones
- Calendario Judio FiestasDocumento7 páginasCalendario Judio FiestasIvan MoralesAún no hay calificaciones
- Derecho Civil 2Documento37 páginasDerecho Civil 2ivonne arangure100% (2)
- Imprimacion Parcial 25 Solucionado de Economia General UniremingtonDocumento3 páginasImprimacion Parcial 25 Solucionado de Economia General Uniremingtonsimsonp musicAún no hay calificaciones
- Unidad Ii Modelos - Gerencia Por ObjetivosDocumento5 páginasUnidad Ii Modelos - Gerencia Por Objetivosisabella fuentes100% (1)