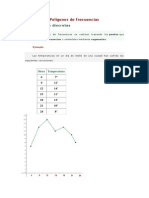
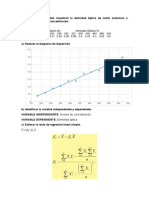
También podría gustarte
- Ejercicios ResueltosDocumento6 páginasEjercicios ResueltosEdwar Magallan50% (2)
- Regresión Lineal TallerDocumento2 páginasRegresión Lineal TallerJ Alexandra Alvarez U50% (4)
- EstadisticaDocumento10 páginasEstadisticaCedrick ReyesAún no hay calificaciones
- Manual EstadisticasDocumento59 páginasManual EstadisticasZagid PerazaAún no hay calificaciones
- Sintesis Datos y EstadisticaDocumento2 páginasSintesis Datos y EstadisticagreeciasAún no hay calificaciones
- Estadistica ToñoDocumento22 páginasEstadistica ToñoMau Mireles100% (1)
- Macroeconomia La InflacionDocumento5 páginasMacroeconomia La InflacionDustin MoralesAún no hay calificaciones
- Trabajo en Latex de Estadistica PDFDocumento15 páginasTrabajo en Latex de Estadistica PDFFlorencioRuaRiveros100% (1)
- Ingresos GastosDocumento152 páginasIngresos GastosANDRES FELIPE ZUBIETA CULMAAún no hay calificaciones
- Serie SimpleDocumento6 páginasSerie SimpleCYBERDEIBYSMARQUEZAún no hay calificaciones
- Temas de Estadística y ProbabilidadDocumento100 páginasTemas de Estadística y ProbabilidadElfredi0% (1)
- Ejercicios Resueltos Sobre Estadística DescriptivaDocumento11 páginasEjercicios Resueltos Sobre Estadística DescriptivaMario Orlando Suárez IbujésAún no hay calificaciones
- Primera Evaluación de Estadística y Probabilidades - 1Documento2 páginasPrimera Evaluación de Estadística y Probabilidades - 1Jose ChuquimiaAún no hay calificaciones
- Universidad Mariano GalvezDocumento18 páginasUniversidad Mariano GalvezEl MarcAún no hay calificaciones
- Cuales Son Las Ventajas de Usar Muestreo para Un Estudio EstadísticoDocumento3 páginasCuales Son Las Ventajas de Usar Muestreo para Un Estudio EstadísticoLuis Enrique Esparza LopezAún no hay calificaciones
- Qué Es Un Formulario en Microsoft AccessDocumento3 páginasQué Es Un Formulario en Microsoft AccessCyberPlus Cafe InternetAún no hay calificaciones
- 4.6. Prueba de Hipótesis Sobre Una Proporción PoblacionalDocumento13 páginas4.6. Prueba de Hipótesis Sobre Una Proporción PoblacionalJosé Isaac Arroyo SerpaAún no hay calificaciones
- Cuestionario 1 Identifique Su AvanceDocumento4 páginasCuestionario 1 Identifique Su Avancemadeleyne pizarroAún no hay calificaciones
- Caso Práctico Isocuantas e Isocostos PDFDocumento1 páginaCaso Práctico Isocuantas e Isocostos PDFCarlos EduardoAún no hay calificaciones
- Matriz Insumo ProductoDocumento2 páginasMatriz Insumo ProductoEddy GBAún no hay calificaciones
- PERMUTACIONES WikiDocumento5 páginasPERMUTACIONES WikiEva MoranAún no hay calificaciones
- Cuestionario de ABCDocumento3 páginasCuestionario de ABCcamila garcia osorioAún no hay calificaciones
- Lista de Ejercicios - EstadisticaDocumento4 páginasLista de Ejercicios - EstadisticaM4Gn3tO0% (1)
- Mezcla Promocional de Google A Nivel InternacionalDocumento33 páginasMezcla Promocional de Google A Nivel InternacionalJosue LemusAún no hay calificaciones
- La Estadística y Sus AplicacionesDocumento323 páginasLa Estadística y Sus Aplicacionesjpsi6Aún no hay calificaciones
- Prueba de Rachas de Una Muestra PDFDocumento11 páginasPrueba de Rachas de Una Muestra PDFDaniel Guzman RojasAún no hay calificaciones
- GLOSARIO Y FORMULARIO-suavizacionDocumento8 páginasGLOSARIO Y FORMULARIO-suavizacionAlexis González0% (1)
- Regresión Simple, Múltiple, CorrelaciónDocumento13 páginasRegresión Simple, Múltiple, CorrelaciónroymerAún no hay calificaciones
- Investigación Regresión Lineal Simple y MúltipleDocumento16 páginasInvestigación Regresión Lineal Simple y MúltipleEdgar PLAún no hay calificaciones
- Ejercicios de Organización de Datos: I I I IDocumento2 páginasEjercicios de Organización de Datos: I I I IXiomara DíazAún no hay calificaciones
- Regresion Lineal SimpleDocumento14 páginasRegresion Lineal SimplefacenunaAún no hay calificaciones
- Análisis Del Desarrollo Industrial MexicanoDocumento8 páginasAnálisis Del Desarrollo Industrial MexicanoJahziel Bañuelos CamuñezAún no hay calificaciones
- Ejercicio de Regresion Lineal MultipleDocumento6 páginasEjercicio de Regresion Lineal MultipleJulissa Alejandra Barturen SandovalAún no hay calificaciones
- Balance General BIMBODocumento9 páginasBalance General BIMBOjarry240990Aún no hay calificaciones
- Fórmulas de EstadísticaDocumento11 páginasFórmulas de Estadística战士僧Aún no hay calificaciones
- Extrapolación de Series de TiempoDocumento20 páginasExtrapolación de Series de TiempoAlexis OliveraAún no hay calificaciones
- Flujo Circular de La EconomiaDocumento1 páginaFlujo Circular de La EconomiaMartha Liliana Castro GrajalesAún no hay calificaciones
- Regresión LinealDocumento11 páginasRegresión LinealSergio A. Ardila ParraAún no hay calificaciones
- Investigación de Estadistica Regresion y CorrelacionDocumento5 páginasInvestigación de Estadistica Regresion y CorrelacionRaquel SantizoAún no hay calificaciones
- Tarea # 3 - Estadística IIDocumento2 páginasTarea # 3 - Estadística IIasdasdasfasfdasf50% (2)
- Correlación y RegresiónDocumento1 páginaCorrelación y RegresiónLIPNI DANIELA SANTANA ASPEITIAAún no hay calificaciones
- Método de La Esquina NoroesteDocumento6 páginasMétodo de La Esquina NoroesteEleazar AtencioAún no hay calificaciones
- 2do Cuestionario de Agregados EconomicosDocumento2 páginas2do Cuestionario de Agregados EconomicosNick ContrerasAún no hay calificaciones
- Ensayo Sistemas de EcuacionesDocumento4 páginasEnsayo Sistemas de EcuacionesAdrianAún no hay calificaciones
- Prueba No Paramétrica de McNemar-ejerciciosDocumento6 páginasPrueba No Paramétrica de McNemar-ejerciciosAngela SotoAún no hay calificaciones
- Medidas de Asimetria y CurtosisDocumento4 páginasMedidas de Asimetria y CurtosisRcristian DherreraAún no hay calificaciones
- ENTREGABLE 1 Mercado y ElasticidadesDocumento8 páginasENTREGABLE 1 Mercado y ElasticidadesAlfredo AparicioAún no hay calificaciones
- Factorizacion LUDocumento12 páginasFactorizacion LUJose Antonio Huerta Caballero100% (1)
- Polígonos de FrecuenciasDocumento7 páginasPolígonos de FrecuenciasJonathan Dominguez100% (1)
- Mínimos Cuadrados Ejemplo Paso A PasoDocumento7 páginasMínimos Cuadrados Ejemplo Paso A PasoeditronikxAún no hay calificaciones
- Aplicacion Del Algebra Lineal en La Vida CotidianaDocumento4 páginasAplicacion Del Algebra Lineal en La Vida CotidianaJuan Pablo Arciniegas GutierrezAún no hay calificaciones
- Métodos de Detección y Corrección de La HeterocedasticidadDocumento4 páginasMétodos de Detección y Corrección de La HeterocedasticidadMISHELL GUAMANAún no hay calificaciones
- Ensayo 1 Distribuciones de ProbabilidadDocumento3 páginasEnsayo 1 Distribuciones de ProbabilidadcamilaAún no hay calificaciones
- PiaDocumento6 páginasPiabofojesus123Aún no hay calificaciones
- Cuestionario Capitulo 1Documento2 páginasCuestionario Capitulo 1CarolValdizonAún no hay calificaciones
- Soluciones de Actividades y Ejercicios 2º Bachillerato de CienciasDocumento258 páginasSoluciones de Actividades y Ejercicios 2º Bachillerato de CienciasperistremaAún no hay calificaciones
- Regresión Lineal MúltipleDocumento11 páginasRegresión Lineal MúltipleNorberto MtzAún no hay calificaciones
- 2.2.1.1 Interpretación Gráficos X-R PDFDocumento3 páginas2.2.1.1 Interpretación Gráficos X-R PDFCETROMAún no hay calificaciones
- Factura CompresoresDocumento1 páginaFactura CompresoresLiliana Lina MartinezAún no hay calificaciones
- Guia #1 Grupo4Documento4 páginasGuia #1 Grupo4Rolando SortoAún no hay calificaciones
- Introduccion, Programacion Linea y Metodo SimplexDocumento40 páginasIntroduccion, Programacion Linea y Metodo SimplexWendy JaramilloAún no hay calificaciones
- Variables Que Inciden en La Balanza ComercialDocumento4 páginasVariables Que Inciden en La Balanza ComercialAlexander ArrietaAún no hay calificaciones
- Error Lineal SimpleDocumento28 páginasError Lineal SimpleEliEli BG33% (3)
- Regresión y Correlación Lineal Simple FINDocumento21 páginasRegresión y Correlación Lineal Simple FINLuisaAún no hay calificaciones
- Metodos Probabilisticos de Optimizacion para Ingenieria CivilDocumento95 páginasMetodos Probabilisticos de Optimizacion para Ingenieria CivilIssac HernándezAún no hay calificaciones
- BIMserver - Center VR Manual de UsoDocumento18 páginasBIMserver - Center VR Manual de UsoIssac HernándezAún no hay calificaciones
- Temario Curso CypecadDocumento2 páginasTemario Curso CypecadIssac HernándezAún no hay calificaciones
- Desplazamientos de ColumnasDocumento13 páginasDesplazamientos de ColumnasIssac HernándezAún no hay calificaciones
- S05 s5 Medidas+Documento21 páginasS05 s5 Medidas+Fiorella CLAún no hay calificaciones
- Modelos BifactorialesDocumento51 páginasModelos BifactorialesGustavo MonjeAún no hay calificaciones
- Hoja Formulas EFDocumento6 páginasHoja Formulas EFAndrea Perdomo FlorezAún no hay calificaciones
- Actividad 2.1 Probabilidad y EstadísticaDocumento9 páginasActividad 2.1 Probabilidad y EstadísticaDash BerlinAún no hay calificaciones
- CINTHYA - MATUTE - 61821375 T8 S8 Estadistica2Documento11 páginasCINTHYA - MATUTE - 61821375 T8 S8 Estadistica2paumatute7Aún no hay calificaciones
- Guia 8 - Distribuciones MuestralesDocumento4 páginasGuia 8 - Distribuciones MuestralesJose Fernando Ramos YampasiAún no hay calificaciones
- Trabajo EconometriaDocumento17 páginasTrabajo Econometriayanaly100% (1)
- T2. Razonamiento Cuantitativo - 07 - 05 - 2020 PDFDocumento43 páginasT2. Razonamiento Cuantitativo - 07 - 05 - 2020 PDFLorena OrjuelaAún no hay calificaciones
- 7distribuciones MuestralesDocumento31 páginas7distribuciones MuestralesAlejandro RuizAún no hay calificaciones
- Ejercicios Prueba de HipotesisDocumento16 páginasEjercicios Prueba de HipotesisERICKA SELENE GARCIA ECHEVARRIA100% (1)
- Actividades de La Unidad 2 TaguchiDocumento53 páginasActividades de La Unidad 2 TaguchiVivi VazquezAún no hay calificaciones
- SPSSDocumento55 páginasSPSSDavid FeceteAún no hay calificaciones
- Modelos Regresión COXDocumento49 páginasModelos Regresión COXjohn campoAún no hay calificaciones
- Trabajo de Estadistica IIDocumento6 páginasTrabajo de Estadistica IIniyivi caceresAún no hay calificaciones
- Análisis BivariadoDocumento10 páginasAnálisis BivariadonegritazulAún no hay calificaciones
- Inferencia EstadisticaDocumento6 páginasInferencia EstadisticaHipatia de AlejandríaAún no hay calificaciones
- Actividad Final, E.IDocumento4 páginasActividad Final, E.ICarolina Angarita ArevaloAún no hay calificaciones
- Tema - 3 - Ejercicios - Resueltos 1121Documento15 páginasTema - 3 - Ejercicios - Resueltos 1121German Gomez RuizAún no hay calificaciones
- Analisis Multivariado-ResumenDocumento37 páginasAnalisis Multivariado-ResumenCristian Javier Caranguay Cuaspud100% (1)
- ESTADISTICADocumento16 páginasESTADISTICASalito EmoshaAún no hay calificaciones
- Pgta 3Documento4 páginasPgta 3Wilhelm SánchezAún no hay calificaciones
- Varianza y Desviación Estándar para Datos Agrupados Por IntervalosDocumento9 páginasVarianza y Desviación Estándar para Datos Agrupados Por IntervalosMilicias Del TáchiraAún no hay calificaciones
- EconometríaDocumento9 páginasEconometríaJhonatan SortoAún no hay calificaciones
- Il3 Portafolio Estudiante (Estadistica Negocios)Documento62 páginasIl3 Portafolio Estudiante (Estadistica Negocios)Christian Neciosup HuillcaAún no hay calificaciones
- EBADocumento13 páginasEBAJenevieer HAún no hay calificaciones
- RETROALIMENTACION Revisio N Del Intento PDFDocumento3 páginasRETROALIMENTACION Revisio N Del Intento PDFjulio pegueroAún no hay calificaciones