También podría gustarte
- Parallel Video Processing Performance Evaluation On The Ibm Cell Broadband Engine ProcessorDocumento13 páginasParallel Video Processing Performance Evaluation On The Ibm Cell Broadband Engine Processornajwa_bAún no hay calificaciones
- Design and Implementation of A Soc Reconfigurable Computing Architecture For Multimedia ApplicationsDocumento7 páginasDesign and Implementation of A Soc Reconfigurable Computing Architecture For Multimedia ApplicationsAli AbdAún no hay calificaciones
- Neural Cache: Bit-Serial In-Cache Acceleration of Deep Neural NetworksDocumento14 páginasNeural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networksreg2regAún no hay calificaciones
- Tesseract Pim Architecture For Graph Processing - Isca15Documento13 páginasTesseract Pim Architecture For Graph Processing - Isca15Megha JoshiAún no hay calificaciones
- Memory ControllerDocumento26 páginasMemory ControllerbulkaenAún no hay calificaciones
- TC 2019 06 0318finalDocumento14 páginasTC 2019 06 0318finaldewufhweuihAún no hay calificaciones
- Intelligent Memory ComputersDocumento9 páginasIntelligent Memory ComputersJanna Tammar Al-WardAún no hay calificaciones
- Tiger Sharc ProcessorDocumento23 páginasTiger Sharc ProcessorKing ChetanAún no hay calificaciones
- Memory Arbitration and Cache Management in Stream-Based SystemsDocumento6 páginasMemory Arbitration and Cache Management in Stream-Based SystemsalekhyakushikAún no hay calificaciones
- Implementing Image Processing Algorithms On Fpgas: C. T. Johnston, K. T. Gribbon, D. G. BaileyDocumento6 páginasImplementing Image Processing Algorithms On Fpgas: C. T. Johnston, K. T. Gribbon, D. G. BaileysemiramistAún no hay calificaciones
- Array Processors: An Introduction To Their Architecture, Software, and Applications in Nuclear MedicineDocumento9 páginasArray Processors: An Introduction To Their Architecture, Software, and Applications in Nuclear MedicineRohan LoharAún no hay calificaciones
- Mapping Vision Algorithms On Simd Architecture Smart CamerasDocumento8 páginasMapping Vision Algorithms On Simd Architecture Smart CamerasVitalie VitalAún no hay calificaciones
- L5-L6-Performance IssuesDocumento47 páginasL5-L6-Performance IssuesAnubhav ShrivastavaAún no hay calificaciones
- 7f99 PDFDocumento8 páginas7f99 PDFSubhadeep Deb RoyAún no hay calificaciones
- An Efficient ASIC Architecture For Real-Time Edge DetectionDocumento10 páginasAn Efficient ASIC Architecture For Real-Time Edge Detectionprakashjyoti0901Aún no hay calificaciones
- Sum Product PaperDocumento10 páginasSum Product PaperpeoriditoAún no hay calificaciones
- A 1 TOPS - W Analog Deep Machine-Learning Engine With Floating-Gate Storage in 0.13 Μm CMOSDocumento12 páginasA 1 TOPS - W Analog Deep Machine-Learning Engine With Floating-Gate Storage in 0.13 Μm CMOSKjfsa TuAún no hay calificaciones
- Octopus: An RDMA-enabled Distributed Persistent Memory File SystemDocumento15 páginasOctopus: An RDMA-enabled Distributed Persistent Memory File SystemPrince RajAún no hay calificaciones
- Stream Processing in General-Purpose ProcessorsDocumento1 páginaStream Processing in General-Purpose Processorszalmighty78Aún no hay calificaciones
- Design and Implementation of 6-Stage 64-Bit MIPS Pipelined ArchitectureDocumento7 páginasDesign and Implementation of 6-Stage 64-Bit MIPS Pipelined ArchitectureAiman JalaliAún no hay calificaciones
- MM 3Documento11 páginasMM 3Doğuş KantarciAún no hay calificaciones
- The Demikernel Datapath OS Architecture For Microsecond-Scale Datacenter SystemsDocumento17 páginasThe Demikernel Datapath OS Architecture For Microsecond-Scale Datacenter Systemsrose jackAún no hay calificaciones
- An Inter-Processor Communication (Ipc) Data Sharing Architecture in Heterogeneous Mpsoc For OfdmaDocumento17 páginasAn Inter-Processor Communication (Ipc) Data Sharing Architecture in Heterogeneous Mpsoc For Ofdmaasu asuAún no hay calificaciones
- Embedded SystemDocumento10 páginasEmbedded SystemBikash RoutAún no hay calificaciones
- Power Efficientreconfigurable Accelerator For Deep Convolutional Neural NetworksDocumento6 páginasPower Efficientreconfigurable Accelerator For Deep Convolutional Neural NetworksAbhishek SrivastavaAún no hay calificaciones
- Research and Realization of Reflective Memory Network: 1. AbstractDocumento56 páginasResearch and Realization of Reflective Memory Network: 1. AbstractAtul KumbharAún no hay calificaciones
- CXL Over Ethernet A Novel FPGA-based MemoryDocumento9 páginasCXL Over Ethernet A Novel FPGA-based Memoryy18864773539Aún no hay calificaciones
- Compute Caches: NtroductionDocumento12 páginasCompute Caches: NtroductionGoblenAún no hay calificaciones
- A Ferroelectric FET-Based Processing-In-Memory ArcDocumento8 páginasA Ferroelectric FET-Based Processing-In-Memory ArcFlavia Monica RodriguesAún no hay calificaciones
- High-Speed I/O: The Operating System As A Signalling MechanismDocumento8 páginasHigh-Speed I/O: The Operating System As A Signalling MechanismiferiantoAún no hay calificaciones
- How Data Transfer Modes and Synchronization Schemes Affect The Performance of A Communication System Based On MyrinetDocumento21 páginasHow Data Transfer Modes and Synchronization Schemes Affect The Performance of A Communication System Based On Myrinetsrikaanth3811Aún no hay calificaciones
- Real-Time Image Processing On A Custom Computing: Pixels, andDocumento9 páginasReal-Time Image Processing On A Custom Computing: Pixels, andimteyazashrafAún no hay calificaciones
- Unit I: Cloud Architecture and ModelDocumento14 páginasUnit I: Cloud Architecture and ModelVarunAún no hay calificaciones
- Allspark: Workload Orchestration For Visual Transformers On Processing In-Memory SystemsDocumento14 páginasAllspark: Workload Orchestration For Visual Transformers On Processing In-Memory SystemslarrylynnmailAún no hay calificaciones
- Research Article Image Processing Design and Algorithm Research Based On Cloud ComputingDocumento10 páginasResearch Article Image Processing Design and Algorithm Research Based On Cloud ComputingKiruthiga PrabakaranAún no hay calificaciones
- Computer96 PsDocumento26 páginasComputer96 PsDom DeSiciliaAún no hay calificaciones
- A Methodology To Design and Prototype Optimized Embedded RobDocumento6 páginasA Methodology To Design and Prototype Optimized Embedded RobHelder Anibal HerminiAún no hay calificaciones
- Chapter 2Documento34 páginasChapter 2ivanmcwils022Aún no hay calificaciones
- Fpga Implementation of A License Plate Recognition Soc Using Automatically Generated Streaming AcceleratorsDocumento8 páginasFpga Implementation of A License Plate Recognition Soc Using Automatically Generated Streaming AcceleratorsMuhammad Awais Bin AltafAún no hay calificaciones
- A Dynamic Scratchpad Memory Collaborated With Cache Memory For Transferring Data For Multi-Bit Error CorrectionDocumento9 páginasA Dynamic Scratchpad Memory Collaborated With Cache Memory For Transferring Data For Multi-Bit Error CorrectionEditor IJTSRDAún no hay calificaciones
- Cluster ComputingDocumento5 páginasCluster Computingshaheen sayyad 463Aún no hay calificaciones
- Lec2 ParallelProgrammingPlatformsDocumento26 páginasLec2 ParallelProgrammingPlatformsSAIAún no hay calificaciones
- High Speed Communication System DevelopmDocumento6 páginasHigh Speed Communication System DevelopmShashank RocksAún no hay calificaciones
- Large-Scale Graph Processing On Commodity Systems: Understanding and Mitigating The Impact of SwappingDocumento11 páginasLarge-Scale Graph Processing On Commodity Systems: Understanding and Mitigating The Impact of SwappingSudip DasAún no hay calificaciones
- Single Producer - Multiple Consumers Ring Buffer Data Distribution System With Memory ManagementDocumento12 páginasSingle Producer - Multiple Consumers Ring Buffer Data Distribution System With Memory ManagementCarlosHEAún no hay calificaciones
- C4-IEEE ParallelRTDocumento8 páginasC4-IEEE ParallelRTLordu GamerAún no hay calificaciones
- Hardware Memory Management For Future Mobile Hybrid Memory SystemsDocumento11 páginasHardware Memory Management For Future Mobile Hybrid Memory SystemsMansoor GoharAún no hay calificaciones
- CA Assignment #2Documento3 páginasCA Assignment #2Chachu-420Aún no hay calificaciones
- Implementing Parallel Processing in Rugged Embeddable EnvironmentDocumento6 páginasImplementing Parallel Processing in Rugged Embeddable EnvironmentMeharban SinghAún no hay calificaciones
- Hard NetDocumento10 páginasHard NetdocjagAún no hay calificaciones
- Edge DetectionDocumento9 páginasEdge Detectionabinabin2Aún no hay calificaciones
- Deploying Customized Data Representation and Approximate Computing in Machine Learning ApplicationsDocumento6 páginasDeploying Customized Data Representation and Approximate Computing in Machine Learning ApplicationsHarsh Mittal-36Aún no hay calificaciones
- Algorithms 12 00154Documento24 páginasAlgorithms 12 00154arania313Aún no hay calificaciones
- Chapter 11Documento33 páginasChapter 11halilkuyukAún no hay calificaciones
- On-Chip vs. Off-Chip Memory - PandaDocumento23 páginasOn-Chip vs. Off-Chip Memory - Pandasarathkumar3389Aún no hay calificaciones
- A Stream Algebra For Computer Vision PipelinesDocumento8 páginasA Stream Algebra For Computer Vision PipelinesaaAún no hay calificaciones
- Introduction To Parallel ProcessingDocumento23 páginasIntroduction To Parallel ProcessingJámès KõstãAún no hay calificaciones
- Area-Time Efficient Streaming Architecture For FAST and BRIEF DetectorDocumento6 páginasArea-Time Efficient Streaming Architecture For FAST and BRIEF DetectorsrinecehodAún no hay calificaciones
- Deep Learning with Python: A Comprehensive Guide to Deep Learning with PythonDe EverandDeep Learning with Python: A Comprehensive Guide to Deep Learning with PythonAún no hay calificaciones
- Image Compression: Efficient Techniques for Visual Data OptimizationDe EverandImage Compression: Efficient Techniques for Visual Data OptimizationAún no hay calificaciones
- Hand Out Fire SurpressDocumento69 páginasHand Out Fire SurpressSeptiawanWandaAún no hay calificaciones
- 385C Waw1-Up PDFDocumento4 páginas385C Waw1-Up PDFJUNA RUSANDI SAún no hay calificaciones
- Poetry UnitDocumento212 páginasPoetry Unittrovatore48100% (2)
- Famous Little Red Book SummaryDocumento6 páginasFamous Little Red Book SummaryMatt MurdockAún no hay calificaciones
- EKC 202ABC ManualDocumento16 páginasEKC 202ABC ManualJose CencičAún no hay calificaciones
- BLP#1 - Assessment of Community Initiative (3 Files Merged)Documento10 páginasBLP#1 - Assessment of Community Initiative (3 Files Merged)John Gladhimer CanlasAún no hay calificaciones
- Modern School For SaxophoneDocumento23 páginasModern School For SaxophoneAllen Demiter65% (23)
- 5066452Documento53 páginas5066452jlcheefei9258Aún no hay calificaciones
- Practical Modern SCADA Protocols. DNP3, 60870.5 and Related SystemsDocumento4 páginasPractical Modern SCADA Protocols. DNP3, 60870.5 and Related Systemsalejogomez200Aún no hay calificaciones
- Mathematics Mock Exam 2015Documento4 páginasMathematics Mock Exam 2015Ian BautistaAún no hay calificaciones
- Kosher Leche Descremada Dairy America Usa Planta TiptonDocumento2 páginasKosher Leche Descremada Dairy America Usa Planta Tiptontania SaezAún no hay calificaciones
- Lesson Plan For Implementing NETSDocumento5 páginasLesson Plan For Implementing NETSLisa PizzutoAún no hay calificaciones
- Knee JointDocumento28 páginasKnee JointRaj Shekhar Singh100% (1)
- Iphone and Ipad Development TU GrazDocumento2 páginasIphone and Ipad Development TU GrazMartinAún no hay calificaciones
- Feasibility Study For Cowboy Cricket Farms Final Report: Prepared For Prospera Business Network Bozeman, MTDocumento42 páginasFeasibility Study For Cowboy Cricket Farms Final Report: Prepared For Prospera Business Network Bozeman, MTMyself IreneAún no hay calificaciones
- Derebe TekesteDocumento75 páginasDerebe TekesteAbinet AdemaAún no hay calificaciones
- Codan Rubber Modern Cars Need Modern Hoses WebDocumento2 páginasCodan Rubber Modern Cars Need Modern Hoses WebYadiAún no hay calificaciones
- Mozal Finance EXCEL Group 15dec2013Documento15 páginasMozal Finance EXCEL Group 15dec2013Abhijit TailangAún no hay calificaciones
- Artificial Intelligence Techniques For Encrypt Images Based On The Chaotic System Implemented On Field-Programmable Gate ArrayDocumento10 páginasArtificial Intelligence Techniques For Encrypt Images Based On The Chaotic System Implemented On Field-Programmable Gate ArrayIAES IJAIAún no hay calificaciones
- Semi Detailed Lesson PlanDocumento2 páginasSemi Detailed Lesson PlanJean-jean Dela Cruz CamatAún no hay calificaciones
- Biology Key Stage 4 Lesson PDFDocumento4 páginasBiology Key Stage 4 Lesson PDFAleesha AshrafAún no hay calificaciones
- Dominion Wargame RulesDocumento301 páginasDominion Wargame Rules4544juutf100% (4)
- Komunikasi Sebagai Piranti Kebijakan Bi: Materi SESMABI Mei 2020Documento26 páginasKomunikasi Sebagai Piranti Kebijakan Bi: Materi SESMABI Mei 2020syahriniAún no hay calificaciones
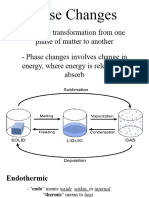
- General Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveDocumento19 páginasGeneral Chemistry 2 Q1 Lesson 5 Endothermic and Exotheric Reaction and Heating and Cooling CurveJolo Allexice R. PinedaAún no hay calificaciones
- Bajaj Vs Hero HondaDocumento63 páginasBajaj Vs Hero HondaHansini Premi100% (1)
- Santu BabaDocumento2 páginasSantu Babaamveryhot0950% (2)
- Maritta Koch-Weser, Scott Guggenheim - Social Development in The World Bank - Essays in Honor of Michael M. Cernea-Springer (2021)Documento374 páginasMaritta Koch-Weser, Scott Guggenheim - Social Development in The World Bank - Essays in Honor of Michael M. Cernea-Springer (2021)IacobAún no hay calificaciones
- Epreuve Anglais EG@2022Documento12 páginasEpreuve Anglais EG@2022Tresor SokoudjouAún no hay calificaciones
- CLG418 (Dcec) PM 201409022-EnDocumento1143 páginasCLG418 (Dcec) PM 201409022-EnMauricio WijayaAún no hay calificaciones
- Feed-Pump Hydraulic Performance and Design Improvement, Phase I: J2esearch Program DesignDocumento201 páginasFeed-Pump Hydraulic Performance and Design Improvement, Phase I: J2esearch Program DesignJonasAún no hay calificaciones