También podría gustarte
- M1u1 MapaDocumento1 páginaM1u1 MapaRodrigo RexAún no hay calificaciones
- G Comun Marzo 2022Documento1 páginaG Comun Marzo 2022Rodrigo RexAún no hay calificaciones
- TMBCOT - ConsultaBoletaPdf Mal Producciones, SalfaDocumento1 páginaTMBCOT - ConsultaBoletaPdf Mal Producciones, SalfaRodrigo RexAún no hay calificaciones
- Ley 15076 Estatuto Médicos FuncionariosDocumento15 páginasLey 15076 Estatuto Médicos FuncionariosRodrigo RexAún no hay calificaciones
- ER Matrícula Por Alumno PUBL MRUN WEBDocumento20 páginasER Matrícula Por Alumno PUBL MRUN WEBviejopiscoleroAún no hay calificaciones
- Flyer Masas Bajo Cero - ImprentaDocumento1 páginaFlyer Masas Bajo Cero - ImprentaRodrigo RexAún no hay calificaciones
- Dto 788 - 17 Feb 2001Documento6 páginasDto 788 - 17 Feb 2001Rodrigo RexAún no hay calificaciones
- Ley 18834 - 23 Sep 1989Documento56 páginasLey 18834 - 23 Sep 1989Rodrigo RexAún no hay calificaciones
- Dto 847 - 07 Feb 2001Documento9 páginasDto 847 - 07 Feb 2001Rodrigo RexAún no hay calificaciones
- Dto 841 - 21 Abr 2001Documento3 páginasDto 841 - 21 Abr 2001Rodrigo RexAún no hay calificaciones
- sFTHGuKJVj7jK03clase2 TransfDocumento63 páginassFTHGuKJVj7jK03clase2 TransfRodrigo RexAún no hay calificaciones
- Y6bVg7MsxcjC3t3clase3 VizualizacionDocumento40 páginasY6bVg7MsxcjC3t3clase3 VizualizacionRodrigo RexAún no hay calificaciones
- Ley 20982 - 28 DIC 2016Documento5 páginasLey 20982 - 28 DIC 2016Rodrigo RexAún no hay calificaciones
- Encuesta de Presupuestos FamiliaresDocumento25 páginasEncuesta de Presupuestos FamiliaresEl MostradorAún no hay calificaciones
- DctoTrabajo13 PIACCDocumento40 páginasDctoTrabajo13 PIACCRodrigo RexAún no hay calificaciones
- Cemento Vs Adobe, Las Ventajas de La BioconstrucciónDocumento9 páginasCemento Vs Adobe, Las Ventajas de La BioconstrucciónRodrigo RexAún no hay calificaciones
- Presentacion Del Director Nacional Sobre Resultados VIII EpfDocumento27 páginasPresentacion Del Director Nacional Sobre Resultados VIII EpfPablo ReyesAún no hay calificaciones
- Listado de Cupos Medicos Aps 2013Documento2 páginasListado de Cupos Medicos Aps 2013Rodrigo RexAún no hay calificaciones
- Casa Ecológica Demostrativa Proyecto Con CorrecionesDocumento6 páginasCasa Ecológica Demostrativa Proyecto Con CorrecionesRodrigo RexAún no hay calificaciones
- Listado de Cupos Dentistas NP 2013Documento1 páginaListado de Cupos Dentistas NP 2013Rodrigo RexAún no hay calificaciones
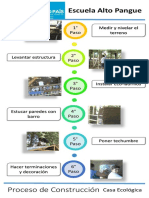
- Afiche - Proceso de ConstrucciónDocumento1 páginaAfiche - Proceso de ConstrucciónRodrigo RexAún no hay calificaciones
- Listado de Cupos Medicos NP 2013Documento1 páginaListado de Cupos Medicos NP 2013Rodrigo RexAún no hay calificaciones
- Cuenta Publica San RafaelDocumento17 páginasCuenta Publica San RafaelRodrigo RexAún no hay calificaciones
- Manual de Tierra CrudaDocumento252 páginasManual de Tierra CrudaFilipe Pereira100% (4)
- Juntas de Vecinos Junio 2017Documento3 páginasJuntas de Vecinos Junio 2017Rodrigo RexAún no hay calificaciones
- Filtros Caseros de Aguas GrisesDocumento8 páginasFiltros Caseros de Aguas Grisesangek_dAún no hay calificaciones
- Guía para La Participación Anticipada de La Comunidad en ProDocumento46 páginasGuía para La Participación Anticipada de La Comunidad en ProDaniela Fuentes SalinasAún no hay calificaciones
- Biofiltro de Arena (Univ. Veracruzana)Documento11 páginasBiofiltro de Arena (Univ. Veracruzana)yolcharnnguenAún no hay calificaciones
- Un 40% de la población urbana de L. A. vive en condiciones miserablesDocumento5 páginasUn 40% de la población urbana de L. A. vive en condiciones miserablesTamara RZAún no hay calificaciones
- Actividad Estructuras CiclicasDocumento3 páginasActividad Estructuras CiclicasVideo GamerAún no hay calificaciones
- Laboratorio de Vectores y MatricesDocumento10 páginasLaboratorio de Vectores y MatricesJavier SotoAún no hay calificaciones
- Programacion Con Java PDFDocumento113 páginasProgramacion Con Java PDFdaves_sanchezAún no hay calificaciones
- Uso de ArreglosDocumento5 páginasUso de ArreglosKarla CarmonaAún no hay calificaciones
- Arreglos en C++Documento13 páginasArreglos en C++Junior Palza RiegaAún no hay calificaciones
- Programación IIDocumento112 páginasProgramación IImolivares870% (1)
- Instrucciones Fundamentales Del Lenguaje CDocumento8 páginasInstrucciones Fundamentales Del Lenguaje CKevin VasquezAún no hay calificaciones
- Anillo Generico de Visual BasicDocumento6 páginasAnillo Generico de Visual BasicAnderson Steve RamírezAún no hay calificaciones
- Movies MAtlabDocumento10 páginasMovies MAtlabLuis QuinoAún no hay calificaciones
- Arreglos 1DDocumento5 páginasArreglos 1DGabriel Eduardo Castillo OlveraAún no hay calificaciones
- ALGORITMOS y PROGRAMAS LAB Nro 1 PDFDocumento42 páginasALGORITMOS y PROGRAMAS LAB Nro 1 PDFJuan Pablo Ossa YepesAún no hay calificaciones
- Metodos Basicos de Ordenamiento en VectoresDocumento31 páginasMetodos Basicos de Ordenamiento en VectoresAlexx SamiiAún no hay calificaciones
- Programación en C++ Arrays y Cadenas de TextoDocumento9 páginasProgramación en C++ Arrays y Cadenas de TextoJessica L PeñaAún no hay calificaciones
- Prof: Ing. José MarvalDocumento60 páginasProf: Ing. José MarvalLewisGarciaAún no hay calificaciones
- Ejercicios Con PunterosDocumento2 páginasEjercicios Con Punterosdennis sumiriAún no hay calificaciones
- Programacion Ejercicios ResueltosDocumento7 páginasProgramacion Ejercicios ResueltosCristofer GuamboAún no hay calificaciones
- Sesión 16 Vectores en JavaDocumento29 páginasSesión 16 Vectores en JavaDAVID ALFONSO SAN JOSE SIERRAAún no hay calificaciones
- EXAMEN (3) Operador InformáticaDocumento10 páginasEXAMEN (3) Operador InformáticaperezfjvAún no hay calificaciones
- Arreglo de MicrofonosDocumento20 páginasArreglo de MicrofonosjuankmalagonAún no hay calificaciones
- Vectores y MatricesDocumento14 páginasVectores y MatricesRafael Angel Mejias IzquierdoAún no hay calificaciones
- Guia de Ejercicios 11Documento4 páginasGuia de Ejercicios 11peopleAún no hay calificaciones
- Estructuras y Organización de Datos PDFDocumento109 páginasEstructuras y Organización de Datos PDFJoséAún no hay calificaciones
- Aaa - Clases 2013Documento103 páginasAaa - Clases 2013Gustavo Espínola MenaAún no hay calificaciones
- Presentación Método de Ordenamiento ShellDocumento10 páginasPresentación Método de Ordenamiento ShellKevin VarelitaAún no hay calificaciones
- Estructuras C++: Área de círculo, suma de complejos, pertenencia a círculo y rectaDocumento8 páginasEstructuras C++: Área de círculo, suma de complejos, pertenencia a círculo y rectatony pinkAún no hay calificaciones
- POO Punteros en C++Documento20 páginasPOO Punteros en C++skilltikAún no hay calificaciones
- Java - Primitivos y ReferenciasDocumento20 páginasJava - Primitivos y ReferenciaszeroxjoelAún no hay calificaciones
- Material Rap 3Documento26 páginasMaterial Rap 3Ernesto Victor Castro LópezAún no hay calificaciones
- Manual de FortranDocumento22 páginasManual de FortraneinstengAún no hay calificaciones
- 04 - I Parcial 2009-1 - MetalurgicaDocumento2 páginas04 - I Parcial 2009-1 - MetalurgicaLeira NogueraAún no hay calificaciones