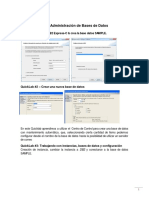
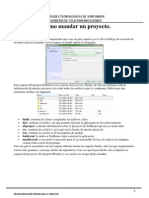
También podría gustarte
- 07 - Practica - Consultas Resumen PDFDocumento26 páginas07 - Practica - Consultas Resumen PDFelreyes2Aún no hay calificaciones
- LaboratoriosBDII PDFDocumento20 páginasLaboratoriosBDII PDFJosué MaidanaAún no hay calificaciones
- Control motor paso bipolar ArduinoDocumento4 páginasControl motor paso bipolar ArduinoJuan Carlos Hernandez MejiaAún no hay calificaciones
- Hibernate mapeo clasesDocumento100 páginasHibernate mapeo clasesAmadorSalami10Aún no hay calificaciones
- Investigación Bibliotecas Estáticas y DinámicasDocumento8 páginasInvestigación Bibliotecas Estáticas y DinámicasRaúl NolascoAún no hay calificaciones
- Examen Unidad 3Documento3 páginasExamen Unidad 3fanysluuAún no hay calificaciones
- P.O.O. VBA ExcelDocumento12 páginasP.O.O. VBA ExcelHugoCamposAún no hay calificaciones
- 01 - Unidad 01 - SQL Server - Instalación y Configuración Inicial v4Documento24 páginas01 - Unidad 01 - SQL Server - Instalación y Configuración Inicial v4José Miguel GarcíaAún no hay calificaciones
- MySQL Triggers BitacoraDocumento5 páginasMySQL Triggers Bitacoragovelinos_341609115Aún no hay calificaciones
- Estructuras de Datos en LabVIEW - National InstrumentsDocumento7 páginasEstructuras de Datos en LabVIEW - National InstrumentsRafael MendozaAún no hay calificaciones
- Rep p2Documento11 páginasRep p2ivan zapata100% (1)
- Modelo Osi (Exposicion) 1Documento21 páginasModelo Osi (Exposicion) 1karlavr100% (1)
- Quicksort en O(nlognDocumento12 páginasQuicksort en O(nlognmtcyosAún no hay calificaciones
- Etiquetas de Movimiento en HTMLDocumento7 páginasEtiquetas de Movimiento en HTMLLuis Enrique HernandezAún no hay calificaciones
- Manejo de Archivos y Registro de DatosDocumento4 páginasManejo de Archivos y Registro de DatosEdilson ValderramaAún no hay calificaciones
- SQLDocumento58 páginasSQLcarlos lopezAún no hay calificaciones
- Apuntes Unidad I Sistemas ProgramableDocumento12 páginasApuntes Unidad I Sistemas ProgramableAndy GaytanAún no hay calificaciones
- Modelos de Procesos de Software para Sistemas EmbebidosDocumento4 páginasModelos de Procesos de Software para Sistemas EmbebidosSaroff Yataco IrrazábalAún no hay calificaciones
- Instalacion de Sistemas de Control Electrico IndustrialDocumento26 páginasInstalacion de Sistemas de Control Electrico IndustrialWILLIAM MONTOYA VILLA100% (1)
- Ventajas y Desventajas de HeapsortDocumento1 páginaVentajas y Desventajas de HeapsortMarifer GalvezAún no hay calificaciones
- Guía de Laboratorio #3Documento14 páginasGuía de Laboratorio #3Jimmy HerreraAún no hay calificaciones
- Guia Java Básico UTSDocumento89 páginasGuia Java Básico UTSkmantillaAún no hay calificaciones
- Conectando SQL Server y Netbeans Con JDBC - Parte 2Documento5 páginasConectando SQL Server y Netbeans Con JDBC - Parte 2Jhordan Leon ZegarraAún no hay calificaciones
- Definición de Circuitos SSI, MSI, LSI, y VLSI.Documento12 páginasDefinición de Circuitos SSI, MSI, LSI, y VLSI.Yajaira Yaguapaz VeraAún no hay calificaciones
- Java Fundamentos Curso POO Bases DatosDocumento2 páginasJava Fundamentos Curso POO Bases DatosArturo Kaleo Gaona VaraAún no hay calificaciones
- Lab 13 CallableStatement 2020 2 Cconislla Puma JosephDocumento6 páginasLab 13 CallableStatement 2020 2 Cconislla Puma JosephBrandon Gomez ParionaAún no hay calificaciones
- Informe de Microcontroladores - Juego de TetrisDocumento8 páginasInforme de Microcontroladores - Juego de TetrisAlbeiro NúñezAún no hay calificaciones
- Conexión A Base de Datos MySql Con JDBCDocumento15 páginasConexión A Base de Datos MySql Con JDBCSantiaguin_94Aún no hay calificaciones
- 1.1 ÓpticosDocumento4 páginas1.1 Ópticoserick_lcAún no hay calificaciones
- Graficacion 3dDocumento27 páginasGraficacion 3dinggafabifiAún no hay calificaciones
- 13 Cursores PDFDocumento23 páginas13 Cursores PDFEstebanBareiroAún no hay calificaciones
- Grupo2 Preinf6Documento3 páginasGrupo2 Preinf6sebatianAún no hay calificaciones
- Tecnicas de Programacion Orientada A Objetos - Java Semana 6 Sesion 1-2-3Documento15 páginasTecnicas de Programacion Orientada A Objetos - Java Semana 6 Sesion 1-2-3Carlos SanchezAún no hay calificaciones
- OrdenamientoDocumento19 páginasOrdenamientoAlex Ruiz CicourelAún no hay calificaciones
- Listas Enlazadas de Estructuras de DatosDocumento14 páginasListas Enlazadas de Estructuras de DatosJulio Cesar GuerreroAún no hay calificaciones
- Actividad 1 Unidad 2 Taller Protocolo ConacitDocumento8 páginasActividad 1 Unidad 2 Taller Protocolo ConacitMaajo CisnerosAún no hay calificaciones
- 1.2 Creacion Del Esquema General de Base de DatosDocumento4 páginas1.2 Creacion Del Esquema General de Base de DatosJesus Daniel Castro Orea100% (1)
- Ejemplo ANTLRDocumento6 páginasEjemplo ANTLRHumberto José MejiasAún no hay calificaciones
- Instalación y Actualización de MS SQL Server y SBO 2007Documento70 páginasInstalación y Actualización de MS SQL Server y SBO 2007Fredy Reyes Orantes100% (1)
- Métodos Abiertos ElectrotecniaDocumento6 páginasMétodos Abiertos ElectrotecniaAlbrecht HerradoraAún no hay calificaciones
- Introducción a VHDLDocumento34 páginasIntroducción a VHDLAnel VallarinoAún no hay calificaciones
- Reconocimiento PCDocumento4 páginasReconocimiento PCAndy SilvaAún no hay calificaciones
- Aplicar DLL A Base de DatosDocumento3 páginasAplicar DLL A Base de DatosmantillavictorAún no hay calificaciones
- Definición de Marco TeóricoDocumento9 páginasDefinición de Marco TeóricoDavid MahrezAún no hay calificaciones
- Persistencia (Conexión JDBC)Documento47 páginasPersistencia (Conexión JDBC)GastónAún no hay calificaciones
- Sistemas OperativosDocumento15 páginasSistemas OperativosJhon Alejandro Esáa ArnaízAún no hay calificaciones
- Diagrama de Ojos Informe de LaboratorioDocumento3 páginasDiagrama de Ojos Informe de LaboratorioKarla BenthamAún no hay calificaciones
- 5 - Compuertas Nand, Nor, Xor y XnorDocumento8 páginas5 - Compuertas Nand, Nor, Xor y XnorMatías Felipe ContardoAún no hay calificaciones
- Listas enlazadas ejerciciosDocumento2 páginasListas enlazadas ejerciciosJason AndersonAún no hay calificaciones
- Diseño de un robot evasor de obstáculos basado en autómatas finitosDocumento16 páginasDiseño de un robot evasor de obstáculos basado en autómatas finitosMoises Daniel0% (1)
- Taller de Base de Datos 7ma UnidadDocumento19 páginasTaller de Base de Datos 7ma UnidadOzckar Da SilvaAún no hay calificaciones
- Thymeleaf ControladoresDocumento8 páginasThymeleaf ControladoresMikiAún no hay calificaciones
- Sobrecarga de OperadoresDocumento29 páginasSobrecarga de OperadoresFranco Airo Rey CordovaAún no hay calificaciones
- Transacciones y concurrencia en SGBDDocumento16 páginasTransacciones y concurrencia en SGBDkevinAún no hay calificaciones
- JSP, Beans y librerías de etiquetasDocumento90 páginasJSP, Beans y librerías de etiquetasMarys_AAún no hay calificaciones
- CUBODocumento23 páginasCUBOMichael Quispe SanchezAún no hay calificaciones
- Introducción a los Algoritmos y las Estructuras de Datos 2: Introducción a los Algoritmos y las Estructuras de Datos, #2De EverandIntroducción a los Algoritmos y las Estructuras de Datos 2: Introducción a los Algoritmos y las Estructuras de Datos, #2Aún no hay calificaciones
- Preguntas Sobre Índices SQL ServerDocumento11 páginasPreguntas Sobre Índices SQL ServerKevin Roman H.Aún no hay calificaciones
- Documento Sin TítuloDocumento3 páginasDocumento Sin TítuloOSCAR LEONEL HERNÁNDEZ GARCÍAAún no hay calificaciones
- INDICESDocumento13 páginasINDICESJosé Pedro PascualAún no hay calificaciones
- 2da. Semana CONFLICTOLOGIA. Matriz Indagacion Critica (5 Ptos)Documento1 página2da. Semana CONFLICTOLOGIA. Matriz Indagacion Critica (5 Ptos)modesto heribertoAún no hay calificaciones
- CAMIILODocumento1 páginaCAMIILOmodesto heribertoAún no hay calificaciones
- Normas de ConvivenciaDocumento42 páginasNormas de ConvivenciaEdral RodriguezAún no hay calificaciones
- Las Ciudades Han Sido Siempre Protagonistas Del Desarrollo de Las CivilizacionesDocumento1 páginaLas Ciudades Han Sido Siempre Protagonistas Del Desarrollo de Las Civilizacionesmodesto heribertoAún no hay calificaciones
- Actividad IIDocumento57 páginasActividad IImodesto heribertoAún no hay calificaciones
- Capitulo XDocumento1 páginaCapitulo Xmodesto heribertoAún no hay calificaciones
- Certificassion de Venta Alcaldía de Semana SantaDocumento1 páginaCertificassion de Venta Alcaldía de Semana Santamodesto heribertoAún no hay calificaciones
- CharlesDocumento3 páginasCharlesmodesto heribertoAún no hay calificaciones
- Cesarina de Los SantosDocumento1 páginaCesarina de Los Santosmodesto heribertoAún no hay calificaciones
- CAPITULOV111Documento2 páginasCAPITULOV111modesto heribertoAún no hay calificaciones
- Charla Sobre La Prevención Del BIH SidaDocumento1 páginaCharla Sobre La Prevención Del BIH Sidamodesto heribertoAún no hay calificaciones
- Razón y Palabra 1605-4806 Instituto Tecnológico y de Estudios Superiores de Monterrey MéxicoDocumento22 páginasRazón y Palabra 1605-4806 Instituto Tecnológico y de Estudios Superiores de Monterrey Méxicomodesto heribertoAún no hay calificaciones
- Cesarina de Los SantosDocumento1 páginaCesarina de Los Santosmodesto heribertoAún no hay calificaciones
- Carta A Daniel MedinaDocumento1 páginaCarta A Daniel Medinamodesto heribertoAún no hay calificaciones
- Capitulo 1Documento1 páginaCapitulo 1modesto heribertoAún no hay calificaciones
- CAPITULO111Documento1 páginaCAPITULO111modesto heribertoAún no hay calificaciones
- 1Documento6 páginas1AbSb Ramdom100% (9)
- Capilo XDocumento3 páginasCapilo Xmodesto heribertoAún no hay calificaciones
- Geometría Entes Fundamentales Recta PlanoDocumento3 páginasGeometría Entes Fundamentales Recta Planomodesto heribertoAún no hay calificaciones
- Planificacion Clase A Clase MaDocumento7 páginasPlanificacion Clase A Clase Mamodesto heribertoAún no hay calificaciones
- ValoresDocumento1 páginaValoresAlejandra GCAún no hay calificaciones
- A Mis FamiliaresDocumento1 páginaA Mis Familiaresmodesto heribertoAún no hay calificaciones
- Boletín de pago quincenal empleadoDocumento8 páginasBoletín de pago quincenal empleadomodesto heribertoAún no hay calificaciones
- Energía EléctricaDocumento1 páginaEnergía Eléctricamodesto heribertoAún no hay calificaciones
- 1Documento1 página1modesto heribertoAún no hay calificaciones
- 1Documento1 página1modesto heribertoAún no hay calificaciones
- Energía EléctricaDocumento1 páginaEnergía Eléctricamodesto heribertoAún no hay calificaciones
- Geometría Entes Fundamentales Recta PlanoDocumento3 páginasGeometría Entes Fundamentales Recta Planomodesto heribertoAún no hay calificaciones
- 1Documento1 página1modesto heribertoAún no hay calificaciones
- Energía EléctricaDocumento1 páginaEnergía Eléctricamodesto heribertoAún no hay calificaciones
- Paso A Paso Pagina Web HTMLDocumento9 páginasPaso A Paso Pagina Web HTMLVane MArtinAún no hay calificaciones
- Bloque 3 Administración Avanzada de Sistemas I VirtualizaciónDocumento7 páginasBloque 3 Administración Avanzada de Sistemas I VirtualizaciónAriel perezAún no hay calificaciones
- Webinar Gratuito: Guía de Pruebas de OWASPDocumento18 páginasWebinar Gratuito: Guía de Pruebas de OWASPAlonso Eduardo Caballero QuezadaAún no hay calificaciones
- Tarea 2Documento22 páginasTarea 2VICTOR MANUEL HERNANDEZ SANTOSAún no hay calificaciones
- Sistema de Información de Marketing (SIM) Andreina OsioDocumento1 páginaSistema de Información de Marketing (SIM) Andreina OsioAndreina OsioAún no hay calificaciones
- Cuadernillo Practicas VB 6.0Documento54 páginasCuadernillo Practicas VB 6.0Edgar Eduardo Mora ReyesAún no hay calificaciones
- Fundamentos Lenguaje SQLDocumento6 páginasFundamentos Lenguaje SQLRaúl Enrique Fernández BejaranoAún no hay calificaciones
- Sistema de ArchivosDocumento12 páginasSistema de ArchivosAndres LeonAún no hay calificaciones
- Mejores Plataformas de Ecommerce para Armar Tu Tienda OnlineDocumento9 páginasMejores Plataformas de Ecommerce para Armar Tu Tienda OnlineAliciaSofia BonillaGalindoAún no hay calificaciones
- Vladimir Soto - Jose A. LlanosDocumento4 páginasVladimir Soto - Jose A. Llanoseso4b30Aún no hay calificaciones
- Introducción A SQL y PLSQLDocumento65 páginasIntroducción A SQL y PLSQLmagalipappaAún no hay calificaciones
- Diagramas UML 2Documento5 páginasDiagramas UML 2Christian PeñaAún no hay calificaciones
- Base de DatosDocumento5 páginasBase de DatosciberhannsAún no hay calificaciones
- IrisDocumento215 páginasIrisNESTOR HERRERAAún no hay calificaciones
- MetadatosDocumento12 páginasMetadatosLöręną PąląføxAún no hay calificaciones
- 20191103201129895361 (1)Documento57 páginas20191103201129895361 (1)Brahian Estuardo Juárez AvilaAún no hay calificaciones
- 1.1 MSQLDocumento5 páginas1.1 MSQLHector Ramon Flores BernalAún no hay calificaciones
- Algoritmos y programación - Abstracción de datosDocumento43 páginasAlgoritmos y programación - Abstracción de datosbedahom66Aún no hay calificaciones
- Enunciados de Practicas FP 2021-22Documento31 páginasEnunciados de Practicas FP 2021-22Javier Pérez García -Aún no hay calificaciones
- Practica 2 ScriptsDocumento6 páginasPractica 2 ScriptsErnesto Jair Silva SeguraAún no hay calificaciones
- Lab 13 Implementación de AD FS (1.3)Documento28 páginasLab 13 Implementación de AD FS (1.3)jose luisAún no hay calificaciones
- Ejemplo Plan de Proyecto de Software (PAPS)Documento58 páginasEjemplo Plan de Proyecto de Software (PAPS)Demilson Terrazas100% (2)
- Fundamentos de PostgresqlDocumento166 páginasFundamentos de PostgresqlMiguel TolabaAún no hay calificaciones
- 02 Ejercicio 1 de UbuntuDocumento12 páginas02 Ejercicio 1 de UbuntuRicardo MonzonAún no hay calificaciones
- Capitulo 6 (Normalización y Dependencias Funcionales) PDFDocumento23 páginasCapitulo 6 (Normalización y Dependencias Funcionales) PDFDani SolanoAún no hay calificaciones
- Manual de Instalación y Configuración de Liferay SODocumento40 páginasManual de Instalación y Configuración de Liferay SOJuan Carlos Quispe ZapataAún no hay calificaciones
- Content Management SystemDocumento4 páginasContent Management SystemGERMAN RODRIGUEZ CARDENASAún no hay calificaciones
- Almacenes KanbanDocumento9 páginasAlmacenes KanbanPedroAún no hay calificaciones
- Capítulo 7 - Uso de Diagramas de FlujoDocumento8 páginasCapítulo 7 - Uso de Diagramas de FlujoCadmiel FerdinandAún no hay calificaciones