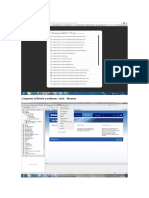
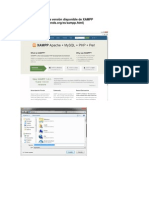
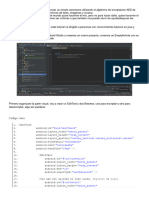
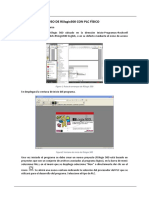
También podría gustarte
- Prog Datasci 5 API Tutorial ScrapyDocumento6 páginasProg Datasci 5 API Tutorial Scrapy504591 504591Aún no hay calificaciones
- Introduccion A WebScrapingDocumento12 páginasIntroduccion A WebScrapingJimmy MuñozAún no hay calificaciones
- 03.1. JavaScript AvanzadoDocumento15 páginas03.1. JavaScript AvanzadoJose Antonio GarciaAún no hay calificaciones
- Desarrollar Modulos en IssabelDocumento24 páginasDesarrollar Modulos en Issabeljorge100% (1)
- Taller SpringDocumento57 páginasTaller SpringDan PerezAún no hay calificaciones
- Ejemplo Simple JaxbDocumento5 páginasEjemplo Simple JaxbfmurdaAún no hay calificaciones
- Practica UNIDAD2Documento12 páginasPractica UNIDAD2soniayamile01100% (1)
- Cómo Usar La Librería JQUERY en Un HTMLDocumento28 páginasCómo Usar La Librería JQUERY en Un HTMLdevourbyverminAún no hay calificaciones
- JavaDocumento35 páginasJavaDaries DctAún no hay calificaciones
- Cear Un Foro PHP y MysqlDocumento11 páginasCear Un Foro PHP y MysqlJose E. Vega EstradaAún no hay calificaciones
- Laboratorio 3 hGzOAfkDocumento5 páginasLaboratorio 3 hGzOAfkelio40294774Aún no hay calificaciones
- Guia 8 (PHP) - POO EN PHP PDFDocumento6 páginasGuia 8 (PHP) - POO EN PHP PDFJo Me CiAún no hay calificaciones
- BicicletasDocumento8 páginasBicicletaslondonpark147Aún no hay calificaciones
- Ar Queti Pos MavenDocumento6 páginasAr Queti Pos MavenMarcos LozanoAún no hay calificaciones
- Uso de Prompts Con Java ScriptsDocumento3 páginasUso de Prompts Con Java ScriptspepeperezpintoAún no hay calificaciones
- Tarea 05Documento20 páginasTarea 05Jorge PadillaAún no hay calificaciones
- JLex y Java Cup Instalacion y EjemploDocumento12 páginasJLex y Java Cup Instalacion y EjemploJose LuisAún no hay calificaciones
- DJANGO-Modelos Resumen - Compressed - 231103 - 001207Documento105 páginasDJANGO-Modelos Resumen - Compressed - 231103 - 001207Dania AllendeAún no hay calificaciones
- Primer TomcatDocumento4 páginasPrimer TomcatManuelito LinuxAún no hay calificaciones
- Helen Stephanie Excepciones, Constructores, Destructores y Arreglos (Java)Documento10 páginasHelen Stephanie Excepciones, Constructores, Destructores y Arreglos (Java)Steph PjAún no hay calificaciones
- Struts 2 Hola Mundo TutorialDocumento7 páginasStruts 2 Hola Mundo TutorialRicardo GranadosAún no hay calificaciones
- Ejemplo de Registro de Datos Con Java en PostgresDocumento2 páginasEjemplo de Registro de Datos Con Java en PostgresJuan Carlos Obando RoldánAún no hay calificaciones
- Spring PDFDocumento11 páginasSpring PDFjose patiñoAún no hay calificaciones
- Como Importar ProyectoDocumento10 páginasComo Importar ProyectoJimmy Mayta MamaniAún no hay calificaciones
- Funciones Autoejecutables en Javascript - EtnasSoftDocumento17 páginasFunciones Autoejecutables en Javascript - EtnasSoftAmilcar de Jesus Gómez CogolloAún no hay calificaciones
- Blog CodeigneterDocumento18 páginasBlog CodeigneterMiguel VenturaAún no hay calificaciones
- 3.6.6 Lab - Parse Different Data Types With PythonDocumento6 páginas3.6.6 Lab - Parse Different Data Types With Pythoncesar castilloAún no hay calificaciones
- Paso A Paso DjangoDocumento12 páginasPaso A Paso DjangoHERNAN ARANGO ISAZAAún no hay calificaciones
- Ejemplo XMLDocumento35 páginasEjemplo XMLMarian FerrerAún no hay calificaciones
- ¿Crear Cuadro de Búsqueda Con Ajax en Django - Entre DesarrolladoresDocumento13 páginas¿Crear Cuadro de Búsqueda Con Ajax en Django - Entre DesarrolladoresDennysCAún no hay calificaciones
- Cifrar y Descifrar Datos Con DES - Java - Consultoría Informática PDFDocumento3 páginasCifrar y Descifrar Datos Con DES - Java - Consultoría Informática PDFJorge Cortés AnguitaAún no hay calificaciones
- Aplicación Web de Flask Con PythonDocumento6 páginasAplicación Web de Flask Con Pythonmiguel junior0% (3)
- Clase 11 12 Tags Struts2Documento45 páginasClase 11 12 Tags Struts2pablo_ferreira_5Aún no hay calificaciones
- Backend - Clase 03 - EjerciciosDocumento3 páginasBackend - Clase 03 - Ejerciciospapayyo2Aún no hay calificaciones
- Instalando XamppDocumento18 páginasInstalando Xamppl_enrikeAún no hay calificaciones
- Modernweb-Com - Translate.goog-45 Consejos Trucos y Mejores Prácticas Útiles de JavaScriptDocumento11 páginasModernweb-Com - Translate.goog-45 Consejos Trucos y Mejores Prácticas Útiles de JavaScriptDivine SolutionsAún no hay calificaciones
- Enum (Enumerados) en Java, Con Ejemplos - JarrobaDocumento15 páginasEnum (Enumerados) en Java, Con Ejemplos - JarrobaEskiwis ProgramadorAún no hay calificaciones
- Cómo Conocer La Cantidad de Memoria Total, Usada y Libre en JavaDocumento16 páginasCómo Conocer La Cantidad de Memoria Total, Usada y Libre en JavaMiguel Romero VelardeAún no hay calificaciones
- JavaServer Pages Standard Tag Library (JSTL)Documento39 páginasJavaServer Pages Standard Tag Library (JSTL)Doomsday73Aún no hay calificaciones
- Practica CorbaDocumento11 páginasPractica CorbaJavier Briceño MontañoAún no hay calificaciones
- Creando Un Ransomware para Android Desde 0Documento12 páginasCreando Un Ransomware para Android Desde 0Alvaro ZamoraAún no hay calificaciones
- FetchDocumento8 páginasFetchJoaco.. .PerezAún no hay calificaciones
- Paquetes, Interfaces y HerenciaDocumento9 páginasPaquetes, Interfaces y Herenciaarmy_84100% (1)
- 04-Django - Bases de Datos, Modelo y Aplicacion de AdministradorDocumento27 páginas04-Django - Bases de Datos, Modelo y Aplicacion de AdministradorFabio Alexander Bedoya AlvarezAún no hay calificaciones
- Ejemplo Practico de Ajax y JSON Con Jquery-Libre PDFDocumento10 páginasEjemplo Practico de Ajax y JSON Con Jquery-Libre PDFLorenzo Arce GomezAún no hay calificaciones
- Guía para Eventos y WebDocumento43 páginasGuía para Eventos y WebtrianaaaaAún no hay calificaciones
- Documentacion CRUD MascotasDocumento14 páginasDocumentacion CRUD MascotasRafael jose herrera zarateAún no hay calificaciones
- 05 Django Vistas y PlantillasDocumento38 páginas05 Django Vistas y PlantillasFabio Alexander Bedoya AlvarezAún no hay calificaciones
- Control Repeater ASPDocumento18 páginasControl Repeater ASPIndigoMagisterialAún no hay calificaciones
- ManualDocumento61 páginasManualsakura kasuganoAún no hay calificaciones
- Administración y Organización de DatosDocumento24 páginasAdministración y Organización de DatosFelipe Jesus MendozaAún no hay calificaciones
- Tutorial de Combos Dependientes Con Ajax y JSPDocumento11 páginasTutorial de Combos Dependientes Con Ajax y JSPMiguel GarciaAún no hay calificaciones
- Uso de SuperDocumento3 páginasUso de SuperAquilino CastañoAún no hay calificaciones
- Python para PentestingDocumento15 páginasPython para PentestingAinoa Piudo CabelloAún no hay calificaciones
- Utilizar Scrapy Sin La TerminalDocumento2 páginasUtilizar Scrapy Sin La TerminalPabloJavierCastilloAún no hay calificaciones
- FPS-12 Plan de Trabajo para Práctica v2021Documento2 páginasFPS-12 Plan de Trabajo para Práctica v2021DERIAN LARRAHONDOAún no hay calificaciones
- Proyecto ABP - OfficeRecovery Online DemoDocumento4 páginasProyecto ABP - OfficeRecovery Online DemoDERIAN LARRAHONDOAún no hay calificaciones
- Ejemplo MoscaDocumento170 páginasEjemplo MoscaDERIAN LARRAHONDOAún no hay calificaciones
- La Jugada MaestraDocumento2 páginasLa Jugada MaestraDERIAN LARRAHONDOAún no hay calificaciones
- ENVIRONMENTAL MANAGEMENT PPTDocumento11 páginasENVIRONMENTAL MANAGEMENT PPTDERIAN LARRAHONDOAún no hay calificaciones
- Quinta Unidad Influencia Del Derecho Anglosajon en ColombiaDocumento42 páginasQuinta Unidad Influencia Del Derecho Anglosajon en ColombiaDERIAN LARRAHONDOAún no hay calificaciones
- Saber Pro 2021aDocumento14 páginasSaber Pro 2021aDERIAN LARRAHONDOAún no hay calificaciones
- Comsumo Percapita-InclusoftDocumento6 páginasComsumo Percapita-InclusoftDERIAN LARRAHONDOAún no hay calificaciones
- NataliaDocumento1 páginaNataliaDERIAN LARRAHONDOAún no hay calificaciones
- ENSAYO Poder Autoridad LiderazgoDocumento2 páginasENSAYO Poder Autoridad LiderazgoJose Miguel Rojas67% (6)
- Iniciando Con NEOj4 - Comandos CypherDocumento5 páginasIniciando Con NEOj4 - Comandos CypherDERIAN LARRAHONDOAún no hay calificaciones
- MarisolDocumento1 páginaMarisolDERIAN LARRAHONDOAún no hay calificaciones
- CONCEPTOS)Documento3 páginasCONCEPTOS)DERIAN LARRAHONDOAún no hay calificaciones
- HUS - Análisis y Creación de Una Empresa Informática - PC DreamZoneDocumento170 páginasHUS - Análisis y Creación de Una Empresa Informática - PC DreamZonedaniel bejaranoAún no hay calificaciones
- DIRIGIR - Electiva AdministrativaDocumento11 páginasDIRIGIR - Electiva AdministrativaDERIAN LARRAHONDOAún no hay calificaciones
- Plantilla ABP Nivel 3 Unicomfacaucav2Documento9 páginasPlantilla ABP Nivel 3 Unicomfacaucav2DERIAN LARRAHONDOAún no hay calificaciones
- Borradorestra MercadoDocumento2 páginasBorradorestra MercadoDERIAN LARRAHONDOAún no hay calificaciones
- Códigos de Clases Ing. Sistemas 2021-I Sede PopayanDocumento8 páginasCódigos de Clases Ing. Sistemas 2021-I Sede PopayanDERIAN LARRAHONDOAún no hay calificaciones
- Comsumo Percapita-InclusoftDocumento6 páginasComsumo Percapita-InclusoftDERIAN LARRAHONDOAún no hay calificaciones
- 2018Documento55 páginas2018DERIAN LARRAHONDOAún no hay calificaciones
- AuditoriaDocumento4 páginasAuditoriaDERIAN LARRAHONDOAún no hay calificaciones
- Funciones de La Administracion - DireccionDocumento10 páginasFunciones de La Administracion - DireccionDERIAN LARRAHONDOAún no hay calificaciones
- Saber Pro 2021aDocumento14 páginasSaber Pro 2021aDERIAN LARRAHONDOAún no hay calificaciones
- Evaluacion Cobit RiesgosDocumento18 páginasEvaluacion Cobit RiesgosDERIAN LARRAHONDOAún no hay calificaciones
- Exp PasantiasDocumento19 páginasExp PasantiasDERIAN LARRAHONDOAún no hay calificaciones
- Horarios ZN Con EnlacesDocumento1 páginaHorarios ZN Con EnlacesDERIAN LARRAHONDOAún no hay calificaciones
- Ley 1672-2013Documento13 páginasLey 1672-2013DERIAN LARRAHONDOAún no hay calificaciones
- Institucional (Blanca)Documento9 páginasInstitucional (Blanca)DERIAN LARRAHONDOAún no hay calificaciones
- Grafo 6 ADocumento6 páginasGrafo 6 ADERIAN LARRAHONDOAún no hay calificaciones
- Exclusión MutuaDocumento11 páginasExclusión Mutualuisa roaAún no hay calificaciones
- Módulo 2 Interruptor Básico y Configuración Del Dispositivo FinalDocumento41 páginasMódulo 2 Interruptor Básico y Configuración Del Dispositivo Finalangel custodio asumu osa esahaAún no hay calificaciones
- Tipos de Archivos y ExtensionesDocumento4 páginasTipos de Archivos y ExtensionesJoel A. Martinez100% (23)
- Daza Sandra 2012Documento119 páginasDaza Sandra 2012camilorichAún no hay calificaciones
- Regla Simpson 1 3 CDocumento5 páginasRegla Simpson 1 3 CDaniel CondeAún no hay calificaciones
- Manuel Eduardo Cortés VallejosDocumento2 páginasManuel Eduardo Cortés VallejosEmmanuel PalmaAún no hay calificaciones
- Sistema de Monitoreo CACTIDocumento7 páginasSistema de Monitoreo CACTIGerman SantiaguesAún no hay calificaciones
- Caso Práctivo N°1 - Guillermo Olivares CDocumento16 páginasCaso Práctivo N°1 - Guillermo Olivares CGuillermo Olivares CalderonAún no hay calificaciones
- Ejemplo Completo de Power Builder para PrincipiantesDocumento154 páginasEjemplo Completo de Power Builder para Principiantesanro_1982100% (5)
- BricsCAD V15 For AutoCAD Users EsDocumento271 páginasBricsCAD V15 For AutoCAD Users EsAnonymous 8ioPBMMZoAún no hay calificaciones
- Manual Del AspiranteDocumento20 páginasManual Del AspiranteMauricio CaloriAún no hay calificaciones
- Repaso de Funciones Semana 8 Victoria LunaDocumento15 páginasRepaso de Funciones Semana 8 Victoria LunaKarina Hernandez HolguinAún no hay calificaciones
- Tesis Sunarp PDFDocumento284 páginasTesis Sunarp PDFAla FukiuAún no hay calificaciones
- Oswer RiofrioDocumento5 páginasOswer RiofrioOSWER FRANCISCO RIOFRIO SANCHEZAún no hay calificaciones
- YawcamDocumento24 páginasYawcamJosemariaAún no hay calificaciones
- Virus, Gusanos, Bot y RootkitsDocumento7 páginasVirus, Gusanos, Bot y Rootkitsandres castilloAún no hay calificaciones
- Manual RSlogixDocumento7 páginasManual RSlogixZurd_oAún no hay calificaciones
- Instalación Básica Oracle 10g en RedHat 5Documento12 páginasInstalación Básica Oracle 10g en RedHat 5Laura Maria MartinAún no hay calificaciones
- PR05-GITE - TI - Copias de Respaldo de Información en La ODPE - V03Documento12 páginasPR05-GITE - TI - Copias de Respaldo de Información en La ODPE - V03Andre Miller MatosAún no hay calificaciones
- Hacia Una Didáctica de La Informática PDFDocumento11 páginasHacia Una Didáctica de La Informática PDFAna Valeria GonzálezAún no hay calificaciones
- FHW02. - Instalación de Software de Utilidad y Propósito General para Un Sistema InformáticoDocumento2 páginasFHW02. - Instalación de Software de Utilidad y Propósito General para Un Sistema InformáticoToni GffbdkrAún no hay calificaciones
- Auditoria Informatica (Capítulo 5)Documento7 páginasAuditoria Informatica (Capítulo 5)paulfullAún no hay calificaciones
- Act 13Documento3 páginasAct 13Erik Gregorio Velasquez HernandezAún no hay calificaciones
- Libro Angular 2Documento29 páginasLibro Angular 2100057213Aún no hay calificaciones
- d00008063 ProyDocumento7 páginasd00008063 ProyWashynAceroMAún no hay calificaciones
- Clase 8 Web AplicationDocumento66 páginasClase 8 Web AplicationDaniel AlvarezAún no hay calificaciones
- Taller Base de DatosDocumento7 páginasTaller Base de DatosVICTORIA EUGENIA HOLGUIN RESTREPOAún no hay calificaciones
- Checklist Periódico Resumido de SAPDocumento5 páginasChecklist Periódico Resumido de SAPChristopher Mitchell Tapia100% (1)
- Qgis FolletoDocumento2 páginasQgis FolletoELDA MORENO VERGELAún no hay calificaciones
- Model BuilderDocumento7 páginasModel BuilderCieza Cueva VitteAún no hay calificaciones