También podría gustarte
- Tecnicas de Modulacion Digital2Documento13 páginasTecnicas de Modulacion Digital2Jose J Pérez LópezAún no hay calificaciones
- Técnicas de Modulación AnalógicaDocumento6 páginasTécnicas de Modulación AnalógicaJose J Pérez LópezAún no hay calificaciones
- Técnicas de Modulación DigitalDocumento5 páginasTécnicas de Modulación DigitalJose J Pérez LópezAún no hay calificaciones
- Tarea 1 U1Documento7 páginasTarea 1 U1Jose J Pérez LópezAún no hay calificaciones
- Conversion Analogico & DigitalDocumento11 páginasConversion Analogico & DigitalJose J Pérez LópezAún no hay calificaciones
- Conversion Analogico & Digital2Documento3 páginasConversion Analogico & Digital2Jose J Pérez LópezAún no hay calificaciones
- Componentes Internos PDFDocumento8 páginasComponentes Internos PDFJose J Pérez LópezAún no hay calificaciones
- Equipo de ComputoDocumento14 páginasEquipo de ComputoJose J Pérez LópezAún no hay calificaciones
- Protocolos & EstándaresDocumento10 páginasProtocolos & EstándaresJose J Pérez LópezAún no hay calificaciones
- Componentes Internos PDFDocumento8 páginasComponentes Internos PDFJose J Pérez LópezAún no hay calificaciones
- Organización y arquitectura de computadoras: modos de direccionamiento y ciclo de instrucciónDocumento14 páginasOrganización y arquitectura de computadoras: modos de direccionamiento y ciclo de instrucciónJose J Pérez LópezAún no hay calificaciones
- Medios Guiados 2Documento4 páginasMedios Guiados 2Jose J Pérez LópezAún no hay calificaciones
- Cable directo vs cruzadoDocumento4 páginasCable directo vs cruzadoJose J Pérez LópezAún no hay calificaciones
- ANALISISDocumento5 páginasANALISISJose J Pérez LópezAún no hay calificaciones
- Medios Guiados 1Documento5 páginasMedios Guiados 1Jose J Pérez LópezAún no hay calificaciones
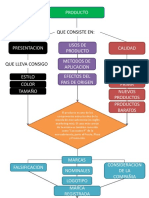
- Producto: Que Consiste enDocumento2 páginasProducto: Que Consiste enJose J Pérez LópezAún no hay calificaciones
- Fundamentos de Telecomunicaciones: Emisor, Receptor y MediosDocumento7 páginasFundamentos de Telecomunicaciones: Emisor, Receptor y MediosJose J Pérez LópezAún no hay calificaciones
- Capacidad de Transmisión de Un Canal y Perturbaciones en La TransmisiónDocumento4 páginasCapacidad de Transmisión de Un Canal y Perturbaciones en La TransmisiónJose J Pérez LópezAún no hay calificaciones
- Cualquier ArchivoDocumento1 páginaCualquier ArchivoJose J Pérez LópezAún no hay calificaciones
- La Informatica Tarea 2.2 IronelyDocumento3 páginasLa Informatica Tarea 2.2 IronelyAmarante gonzalez rojasAún no hay calificaciones
- Área 3Documento7 páginasÁrea 3Julieth IguadAún no hay calificaciones
- 02-Manejo de Archivos Con InputStream y OutputStreamDocumento11 páginas02-Manejo de Archivos Con InputStream y OutputStreamjosepalacio497Aún no hay calificaciones
- Eva 5645036Documento17 páginasEva 5645036Melisa Consuelo Hidalgo CastilloAún no hay calificaciones
- AnálisisDocumento10 páginasAnálisiswarashirleyAún no hay calificaciones
- AP05 AA6 EV04 Elaboracion Clausulas Tecnicas ContratacionDocumento15 páginasAP05 AA6 EV04 Elaboracion Clausulas Tecnicas ContratacionMaria Vargas100% (2)
- Evaluación Diagnóstica Revisión Del IntentoDocumento29 páginasEvaluación Diagnóstica Revisión Del IntentoGEORGE RONDA100% (1)
- 11 Grado Tecnologia 2PDocumento10 páginas11 Grado Tecnologia 2PCharlis ZarzaAún no hay calificaciones
- Salvoconducto o Guías de Movilización Desde La App AUNAPDocumento15 páginasSalvoconducto o Guías de Movilización Desde La App AUNAProbinsonAún no hay calificaciones
- HP DesignJet T250Documento2 páginasHP DesignJet T250Manuel RabanalAún no hay calificaciones
- Sistemas Digitales y Periféricos Extra 2Documento7 páginasSistemas Digitales y Periféricos Extra 2Misael Ayala0% (1)
- Ev1.Utec - edu.Uy-Cuestionario de VC 2 Semana 5 Attempt ReviewDocumento4 páginasEv1.Utec - edu.Uy-Cuestionario de VC 2 Semana 5 Attempt ReviewguhAún no hay calificaciones
- Capítulo 3 - Variables en PowerShellDocumento3 páginasCapítulo 3 - Variables en PowerShelldirecthitAún no hay calificaciones
- Teleasistencia Help Line PDFDocumento4 páginasTeleasistencia Help Line PDFDanilo LarzoneiAún no hay calificaciones
- Las 5 Reglas de Oro Ante El Riesgo Eléctrico. TrabajoDocumento5 páginasLas 5 Reglas de Oro Ante El Riesgo Eléctrico. TrabajoZarra R.S.Aún no hay calificaciones
- Series IV Calculo IntegralDocumento15 páginasSeries IV Calculo IntegralLuis QuintanaAún no hay calificaciones
- Parte 3Documento16 páginasParte 3DominikAún no hay calificaciones
- Funciones Máximo y Mínimo en CDocumento20 páginasFunciones Máximo y Mínimo en CRogerOrihuelaAún no hay calificaciones
- Aportaciones Sobre Las TIC-Daniel CamposDocumento19 páginasAportaciones Sobre Las TIC-Daniel CamposDaniel CamposAún no hay calificaciones
- Análisis Sobre Módulos de Seguridad en ApacheDocumento6 páginasAnálisis Sobre Módulos de Seguridad en ApacheLizbeth Gianella Egusquiza VicenteAún no hay calificaciones
- in VitroDocumento8 páginasin VitroDaniel AriasAún no hay calificaciones
- OSHA 30 Capitulo 12Documento16 páginasOSHA 30 Capitulo 12grorbinAún no hay calificaciones
- Clase 1.conceptos - de - Bases - de - DatosDocumento47 páginasClase 1.conceptos - de - Bases - de - DatosKimberly LeandroAún no hay calificaciones
- EncuestaDocumento11 páginasEncuestaFOTOS GRADUADOSAún no hay calificaciones
- Profesional CreativoDocumento12 páginasProfesional CreativoAaron Mendoza SianquezAún no hay calificaciones
- Exposición TF CI1B Matematica Basica UpcDocumento7 páginasExposición TF CI1B Matematica Basica UpcLucas Muñoz100% (1)
- Sistema Bikefit Analisis BiomecanicoDocumento33 páginasSistema Bikefit Analisis BiomecanicoLeo Vasquez BlasAún no hay calificaciones
- Base de Datos - TP 3Documento3 páginasBase de Datos - TP 3ABIGAIL SAJAMAAún no hay calificaciones
- Estructruas de Papel 1Documento3 páginasEstructruas de Papel 1Jhon J Galan RAún no hay calificaciones
- Deber LagrangeDocumento2 páginasDeber LagrangeValerie CevallosAún no hay calificaciones