También podría gustarte
- MEDICAMENTOs Inhibidores Del Factor XaDocumento3 páginasMEDICAMENTOs Inhibidores Del Factor XaAdrian Venegas ArroyoAún no hay calificaciones
- P Sem01 Ses01 Conceptos Variables Estadísticas ACT-1Documento71 páginasP Sem01 Ses01 Conceptos Variables Estadísticas ACT-1sebas trujilloAún no hay calificaciones
- Regresión Logística MultinomialDocumento6 páginasRegresión Logística MultinomialGuillermo BuragliaAún no hay calificaciones
- Chirinos MedinaDocumento2 páginasChirinos MedinaTizy LynAún no hay calificaciones
- Pirámide epidemiológica y solidez científicaDocumento8 páginasPirámide epidemiológica y solidez científicayaqueline garzonAún no hay calificaciones
- Marco TeoricoDocumento28 páginasMarco TeoricoGisela Flores100% (2)
- Fundamentos de Diagnostico en OdontologiaDocumento11 páginasFundamentos de Diagnostico en OdontologianicoAún no hay calificaciones
- Tema 9Documento58 páginasTema 9Melissa Rodriguez100% (1)
- Bioquimica de La Vision PDFDocumento7 páginasBioquimica de La Vision PDFShyannaAún no hay calificaciones
- Reporte de Caso Clínico12Documento7 páginasReporte de Caso Clínico12Reinaldo Quiroga MendozaAún no hay calificaciones
- Esquema Del Metodo CientificoDocumento1 páginaEsquema Del Metodo CientificoChristye Marjorie Silva GuerreroAún no hay calificaciones
- Taller 1 Probabilidad IIDocumento9 páginasTaller 1 Probabilidad IIJohn PalaciosAún no hay calificaciones
- Usat XCDocumento10 páginasUsat XCRickyQuintanaAún no hay calificaciones
- Resumen Epidemio AqbDocumento19 páginasResumen Epidemio AqbMica07 edlpAún no hay calificaciones
- Informe de Guardias Comunitarias - AgostoDocumento42 páginasInforme de Guardias Comunitarias - AgostoKaren Garay FloresAún no hay calificaciones
- Prueba de McnemarDocumento3 páginasPrueba de McnemarChava LozanoAún no hay calificaciones
- Mapa Conceptual Odontologia PDFDocumento2 páginasMapa Conceptual Odontologia PDFFaisury Trochez DaZa0% (1)
- Informe ProbabilidadDocumento5 páginasInforme ProbabilidadEmerson Pérez50% (2)
- SociemDocumento14 páginasSociemNoelia ZavalaAún no hay calificaciones
- Informe #2 - Fatiga.Documento6 páginasInforme #2 - Fatiga.Cristian Pineda GuevaraAún no hay calificaciones
- Informe de BiofisicaDocumento8 páginasInforme de BiofisicaJosé BarretoAún no hay calificaciones
- Escuelas de OclusiónDocumento12 páginasEscuelas de OclusiónBRITNEY ALEIDA ESQUIVEL HERNANDEZAún no hay calificaciones
- Histología Periodonto de InserciónDocumento7 páginasHistología Periodonto de InserciónKevin JirónAún no hay calificaciones
- Trabajo Listo de Estadistica InferencialDocumento28 páginasTrabajo Listo de Estadistica InferencialMardeyLozadaVargasAún no hay calificaciones
- Ejercicios EstadisticaDocumento1 páginaEjercicios EstadisticaHarold Andrew100% (1)
- Actividad Practica División de Patologia e Historia Natural de La EnfermedadDocumento5 páginasActividad Practica División de Patologia e Historia Natural de La EnfermedadSheyla Espinoza RiosAún no hay calificaciones
- Operacionalizacion de VariablesDocumento13 páginasOperacionalizacion de VariablesAreida GonzalezAún no hay calificaciones
- BIOFISICADocumento27 páginasBIOFISICAAnthony GamboaAún no hay calificaciones
- Grupo 39 Sem Mat Tarea 4Documento29 páginasGrupo 39 Sem Mat Tarea 4Denis Peralta VillalobosAún no hay calificaciones
- Qué Es Un PeriodontogramaDocumento1 páginaQué Es Un PeriodontogramaFrancisco EspinosaAún no hay calificaciones
- 01 Cálculo de Errores en Las MedicionesDocumento5 páginas01 Cálculo de Errores en Las MedicionesAlex Mendoza MoralesAún no hay calificaciones
- EjerciciosCorrelacionRegresionDocumento31 páginasEjerciciosCorrelacionRegresionrosa sanchezAún no hay calificaciones
- Evaluación - S03Documento2 páginasEvaluación - S03GUSTAVO JOSUE HINOSTROZA ARENAS100% (1)
- Ficha de Encuesta Proyecto Barreras CorregidaDocumento6 páginasFicha de Encuesta Proyecto Barreras CorregidaJorge Alejandro PardoAún no hay calificaciones
- McNemar PDFDocumento7 páginasMcNemar PDFBeatriz RiquelmeAún no hay calificaciones
- Caso Clinico ImplantologiaDocumento10 páginasCaso Clinico Implantologiaabigail0% (1)
- Monografia FffinallDocumento40 páginasMonografia FffinallHIROE MIYASHIROAún no hay calificaciones
- Región InfrahioideaDocumento3 páginasRegión InfrahioideaJorge Cabezas Rodríguez100% (1)
- s02 Medidas de ResumenDocumento29 páginass02 Medidas de ResumenRay Cuevas Pino0% (1)
- Examen 3 TelesupDocumento6 páginasExamen 3 TelesupEderAún no hay calificaciones
- HC FibroadenomaDocumento7 páginasHC FibroadenomaluisAún no hay calificaciones
- Ensayo Ortodoncia AtiDocumento9 páginasEnsayo Ortodoncia AtiAlexsandra Gutierrez PeñaAún no hay calificaciones
- Historia de La BioestadisticaDocumento4 páginasHistoria de La BioestadisticaAlexandra TorresAún no hay calificaciones
- La Democracia Es Una Manera de Organización PolíticaDocumento6 páginasLa Democracia Es Una Manera de Organización PolíticaGaby Santacruz ArteagaAún no hay calificaciones
- Tomograf°a LinealDocumento17 páginasTomograf°a Linealmi.ni.pe.100% (1)
- Comité de Etica AsistencialDocumento41 páginasComité de Etica AsistencialDenis Cardich Tello100% (1)
- Resumen Bases de Datos-Víctor EstradaDocumento2 páginasResumen Bases de Datos-Víctor EstradaVictor Estrada100% (1)
- Tipos de variables en investigaciónDocumento10 páginasTipos de variables en investigaciónCarlos Vigueras Rodríguez0% (2)
- Indicadores epidemiológicos en odontología: CPOD, Ceod, índice O'LearyDocumento34 páginasIndicadores epidemiológicos en odontología: CPOD, Ceod, índice O'Learymanolo1958Aún no hay calificaciones
- ENSAYODocumento4 páginasENSAYOZu Chiquinquira Lima HernandezAún no hay calificaciones
- Conceptos Básicos Sobre Estadística Parte BDocumento15 páginasConceptos Básicos Sobre Estadística Parte Bgenesis martinezAún no hay calificaciones
- Prueba de Hipótesis Diferencia de MediasDocumento4 páginasPrueba de Hipótesis Diferencia de MediasGina PerezAún no hay calificaciones
- Aplicaciones de La Lógica Proposicional y ConjuntosDocumento5 páginasAplicaciones de La Lógica Proposicional y ConjuntosEDINSON REYES ALVAAún no hay calificaciones
- Anemia posthemorrágica: causas, síntomas y tratamientoDocumento8 páginasAnemia posthemorrágica: causas, síntomas y tratamientoAlberto Delgado100% (1)
- Monografia AntibioticoDocumento13 páginasMonografia AntibioticoLeydy Flores tafurAún no hay calificaciones
- HCL Pediátrica FinalDocumento80 páginasHCL Pediátrica FinalJoselin PadillaAún no hay calificaciones
- Discusión Caso ClínicoDocumento24 páginasDiscusión Caso ClínicoInfectologia ClinicaAún no hay calificaciones
- Regresión Logistica CompletoDocumento35 páginasRegresión Logistica CompletoLENNIN BRAYAN DIAZ HERRERAAún no hay calificaciones
- Perelman - Algebra RecreativaDocumento160 páginasPerelman - Algebra Recreativachicho6404Aún no hay calificaciones
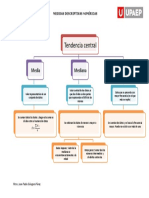
- Mapa Tendencia CentralDocumento1 páginaMapa Tendencia CentralJuan Pablo Góngora PérezAún no hay calificaciones
- Operaciones Matemáticas Básicas PDFDocumento16 páginasOperaciones Matemáticas Básicas PDFJuan Pablo Góngora PérezAún no hay calificaciones
- Rubrica de ReflexiónDocumento3 páginasRubrica de ReflexiónJuan Pablo Góngora PérezAún no hay calificaciones
- Proyecto de La Matrícula Universitaria - Período 2000-2030Documento46 páginasProyecto de La Matrícula Universitaria - Período 2000-2030Jhon Gonzls QlcAún no hay calificaciones
- Aplicaciones Estadísticas en Las Ciencias Sociales PDFDocumento6 páginasAplicaciones Estadísticas en Las Ciencias Sociales PDFCoordinación Académica Escuela de SociologiaAún no hay calificaciones
- Pruebas Estadisticas Que Se AplicanDocumento1 páginaPruebas Estadisticas Que Se AplicanJuan Pablo Góngora PérezAún no hay calificaciones
- Proyecto Universidad Card Paul Poupard 7jun2001Documento17 páginasProyecto Universidad Card Paul Poupard 7jun2001Juan Pablo Góngora PérezAún no hay calificaciones
- 06 GruposDocumento12 páginas06 GruposJuan Pablo Góngora PérezAún no hay calificaciones
- 07 ComunidadEducaplayDocumento34 páginas07 ComunidadEducaplayJuan Pablo Góngora PérezAún no hay calificaciones
- Constitucion Apostolica Ex Corde EcclesiaeDocumento20 páginasConstitucion Apostolica Ex Corde EcclesiaeJuan Pablo Góngora PérezAún no hay calificaciones
- 04 MisColeccionesDocumento12 páginas04 MisColeccionesJuan Pablo Góngora PérezAún no hay calificaciones
- 05 EncontrandoActividadesDocumento15 páginas05 EncontrandoActividadesJuan Pablo Góngora PérezAún no hay calificaciones
- EjemplosDocumento5 páginasEjemplosValentin BalderasAún no hay calificaciones
- 03 ActividadesEducaplay (II)Documento29 páginas03 ActividadesEducaplay (II)Juan Pablo Góngora PérezAún no hay calificaciones
- 02 ActividadesEducaplay (I)Documento29 páginas02 ActividadesEducaplay (I)Juan Pablo Góngora PérezAún no hay calificaciones
- Curso de Programación de Macros en ExcelDocumento157 páginasCurso de Programación de Macros en ExcelJuan RuizAún no hay calificaciones
- Registro en EducaplayDocumento3 páginasRegistro en EducaplayJuan Pablo Góngora PérezAún no hay calificaciones
- 01 IntroducciónAEducaplayDocumento12 páginas01 IntroducciónAEducaplayJose Andres GuerreroAún no hay calificaciones
- 00 MetodologíaDocumento62 páginas00 MetodologíaJuan Pablo Góngora PérezAún no hay calificaciones
- Investigacion de Operaciones Redes y La Administracion de Proyectos CPM y Pert - 2Documento59 páginasInvestigacion de Operaciones Redes y La Administracion de Proyectos CPM y Pert - 2Hack GamAMAún no hay calificaciones
- Cotización de repuestos para maquinaria pesadaDocumento2 páginasCotización de repuestos para maquinaria pesadaLuis Angel ChiloAún no hay calificaciones
- Características Primera RepúblicaDocumento6 páginasCaracterísticas Primera RepúblicaGabriela Jonaily Urdaneta Quijada100% (2)
- Acfutsur 2019 BarranquillaDocumento4 páginasAcfutsur 2019 BarranquillaLore Patri AndradeAún no hay calificaciones
- Celebracion Todo Santo, CopainalaDocumento28 páginasCelebracion Todo Santo, Copainalamaetna_23_669050168100% (1)
- Metodologia Teoria Del DerechoDocumento1 páginaMetodologia Teoria Del DerechoErika PGAún no hay calificaciones
- Rendimiento de Una Reaccion QuimicaDocumento7 páginasRendimiento de Una Reaccion QuimicaOlga MalaverAún no hay calificaciones
- Examen Enseñanza Por Competencia Semana 3Documento3 páginasExamen Enseñanza Por Competencia Semana 3Jose adrian Rocha rocha33% (3)
- Sisp U1 A1 OmbaDocumento5 páginasSisp U1 A1 OmbaOmar I Baqueiro AAún no hay calificaciones
- 02 Martes 05 Ciencia EL SISTEMA CIRCULATORIO Y EXCRETORDocumento3 páginas02 Martes 05 Ciencia EL SISTEMA CIRCULATORIO Y EXCRETORShido SempaiAún no hay calificaciones
- 3 Griffa y MorenoDocumento50 páginas3 Griffa y MorenoMicaela Lopez100% (1)
- Inteligencia Comercial MonografìaDocumento16 páginasInteligencia Comercial MonografìaAlejandro Miñano CalderonAún no hay calificaciones
- La EtimologíaDocumento7 páginasLa Etimologíadayner ojedaAún no hay calificaciones
- Instituto TecnolÓgico de QuerÉtaro.Documento12 páginasInstituto TecnolÓgico de QuerÉtaro.benjamin10Aún no hay calificaciones
- Capitulo 1 Delia LernerDocumento2 páginasCapitulo 1 Delia LernerRosita Ramirez RuizAún no hay calificaciones
- Manual Liderazgo en NTDocumento32 páginasManual Liderazgo en NTGustavo Martin KarakeyAún no hay calificaciones
- Funciones de Los Asesores Pedagogicos y Cordinadores PaebDocumento9 páginasFunciones de Los Asesores Pedagogicos y Cordinadores PaebMaría AlejandraAún no hay calificaciones
- Planificacion CACERES, CHAMBIDocumento4 páginasPlanificacion CACERES, CHAMBIElisa CaceresAún no hay calificaciones
- La Investigacion Como Proceso de Intervencion SocialDocumento5 páginasLa Investigacion Como Proceso de Intervencion SocialjosezawadskyAún no hay calificaciones
- Lista de Cotejo - Proyecto FinalDocumento1 páginaLista de Cotejo - Proyecto FinalGISELDA LOZADA SERVINAún no hay calificaciones
- Jurisdiccion VoluntariaDocumento4 páginasJurisdiccion VoluntarializethAún no hay calificaciones
- Integracion VisomotrizDocumento35 páginasIntegracion VisomotrizAnonymous bAOyv6orKAún no hay calificaciones
- TR1 Huancas MantnimientoDocumento14 páginasTR1 Huancas Mantnimientokevin anderson esquen cercadoAún no hay calificaciones
- Propiedades PeriodicasDocumento6 páginasPropiedades PeriodicasJose Antonio Ortega CastroAún no hay calificaciones
- Catalogo General 2019 Segundo SemestreDocumento268 páginasCatalogo General 2019 Segundo SemestreJuan Cristóbal Rivera PuellesAún no hay calificaciones
- Guía completa del vermutDocumento13 páginasGuía completa del vermutLuis Del AngelAún no hay calificaciones
- Informe Ejecutivo Sustentacion II Y IV Trimestre 425fa14aba8d788Documento6 páginasInforme Ejecutivo Sustentacion II Y IV Trimestre 425fa14aba8d788laura tellezAún no hay calificaciones
- Administracion de AlmacenesDocumento43 páginasAdministracion de AlmacenesYovanna VasquezAún no hay calificaciones
- Teoria Del Desarrollo FamiliarDocumento2 páginasTeoria Del Desarrollo FamiliarAmelia Guadalupe100% (1)